نمونه ترجمه های سایت ای ترجمه
مقاله اینترنت اشیا و سایر راه حلهای الکترونیکی در مدیریت زنجیره عرضه ممکن است خطراتی را در بخش انرژی بوجود میآورد
3.2. The Internet of Things and Its Consequences
Internet of Things became a popular topic of Industry 4.0. Many publications regarding these topics focus on large-, small- and medium-sized firms. Ashton introduced the term Internet of Things in 1999. It refers to a system in which the material world communicates with computers using sensors [12,49–58]. Several years later, the number of devices connected to the network exceeded the number of people around the world. This moment, according to Cisco, is the actual birth of the “Internet of Things”, referred to more often as the “Internet of Everything”. A system consists of people and objects, as well as processes, animals and data, including atmospheric phenomena—all elements that can be used as variables [12].
The Internet of Things has three distinguishing features. These are context, omnipresence and optimisation. The Internet of Things creates the possibility of an advanced interaction between an object and its environment and enables immediate response to change. The feature of context manifests itself in providing location, atmospheric conditions and other information necessary for an object. Omnipresence illustrates that connected objects are not only human users of the network. Objects will communicate with each other without human interference. Optimisation is the expression of the functionality of any object [12]. Tun et al. [57] argue that the Internet of Things can be used in healthcare systems globally. It may improve the quality of life of elderly populations while reducing costs on healthcare systems. However, one should point out the threat posed by the unauthorised usage of this technology and the possibility of tracking people without their permission. The “Big Brother” case is not fictitious. Quite recently, the media circulated information about the illegal tapping of private conversations of the President of France with the use of spyware [58]. Therefore, it is already necessary to consider preventive measures.
3.2. اینترنت اشیا و پیامدهای آن
اینترنت اشیا به موضوع محبوب صنعت 4.0 تبدیل شد. بسیاری از نشریات مربوط به این موضوعات، بر شرکتهای بزرگ، کوچک و متوسط تمرکز دارند. اشتون اصطلاح اینترنت اشیاء را در سال 1999 معرفی کرد. این اصطلاح به سیستمی که در آن دنیای مادی با استفاده از حسگرها با کامپیوترها ارتباط برقرار میکند، اشاره دارد [12, 49-58]. چندین سال بعد، تعداد دستگاههای متصل به شبکه از تعداد افراد سراسر جهان تجاوز کرد. به گفتهی سیسکو، این لحظهی تولد واقعی "اینترنت اشیا"، که بیشتر به عنوان "اینترنت همه چیز" شناخته میشود، است. یک سیستم متشکل از افراد و اشیاء، و نیز فرآیندها، حیوانات و داده ها، از جمله پدیدههای جوی - همه عناصری که میتوانند به عنوان متغیر استفاده شوند [12].
اینترنت اشیا سه ویژگی متمایز دارد. این ویژگیها عبارتند از زمینه، حضور در همه جا و بهینهسازی. اینترنت اشیا، تعامل پیشرفته بین یک شئ و محیط آن را ممکن ساخته و واکنش فوری به تغییر را امکانپذیر میکند. ویژگی زمینه، خود را در ارائه مکان، شرایط جوی و سایر اطلاعات لازم برای یک شئ نشان میدهد. حضور همه جانبه نشان میدهد که اشیاء متصل، فقط کاربران انسانی شبکه نیستند. اشیاء بدون دخالت انسان با یکدیگر ارتباط برقرار خواهند کرد. بهینه سازی عبارت است از نشان دادن عملکرد هر شئ [12]. تون و همکارانش [57] بر اینکه میتوان از اینترنت اشیاء در سیستمهای مراقبتهای بهداشتی در سطح جهانی استفاده کرد، بحث میکنند. این در حین کاهش هزینههای سیستمهای مراقبت بهداشتی، میتواند کیفیت زندگی جمعیت سالمند را بهبود بخشد. با اینحال، بایستی به خطر ناشی از استفاده غیرمجاز از این فناوری و احتمال زیر نظر گرفتن افراد بدون اجازه آنها، اشاره کرد. پروندهی «برادر بزرگ» ساختگی نیست. اخیراً رسانهها اطلاعاتی را در مورد شنود غیرقانونی مکالمات خصوصی رئیس جمهور فرانسه با استفاده از نرم افزارهای جاسوسی، منتشر کردهاند [58]. بنابراین، لحاظ کردن اقدامات پیشگیرانه، بسیار ضروری است.
توضیحات: این مقاله انگلیسی در سال 2021 در mdpi چاپ شده و در سال 1401 در سایت ای ترجمه توسط مترجم کد T5619 ترجمه با کیفیت مبتدی گردیده است.
مقاله راهکارهای ارتقا شناختی برای بهبود درمان شناختی-رفتاری برای هیجان و اختلالات مرتبط
Methods of Augmenting CBT With Cognitive Enhancement
CBT augmented with cognitive enhancement can be completed through two avenues that can be conducted on their own or in conjunction with each other. The first method is to utilize specific cognitive strategies to enhance understanding and memory for and implementation of CBT techniques. For example, a therapist may utilize repetition to increase patient recall for important components of treatment. Specific memory support strategies have been used in targeting depression in younger (Dong, Lee, & Harvey, 2017; Harvey et al., 2016) and older adults (Scogin et al., 2013) and late-life GAD (Mohlman et al., 2003). See Table 1 for specific strategies that may be implemented to enhance treatment.
The second method is to apply cognitive enhancement more generally by aiming to improve cognitive skills themselves. Therapists can augment CBT with cognitive skills training as poor cognitive skills have been shown to impact CBT outcomes (Mohlman & Gorman, 2005). This nonspecific strategy has been tested in younger adults with unipolar depression (Siegle, Ghinassi, & Thase, 2007), bipolar disorder (BD; Deckersbach et al., 2010), and social anxiety disorder (SAD; McEvoy & Perini, 2009 ) , and in older adults with GAD (Mohlman, 2008; Mohlman & Gorman, 2005), anxiety co -occurring with Parkinson ’s disease (PD; Mohlman, DeVito, Lauderdale, & Dobkin, 2017), and hoarding disorder (HD; Ayers, Wetherell, Golshan, & Saxena, 2011 ; Ayers et al., 2009).
روش های ارتقا CBT با تقویت شناختی
CBT تقویت شده با افزایش شناختی را می توان از طریق دو مسیر تکمیل کرد که می توانند به تنهایی یا در ارتباط با یکدیگر انجام شوند. روش اول استفاده از رویکردهای شناختی ویژه برای ارتقا درک و حافظه برای اجرای تکنیک های CBT است. برای مثال، یک پزشک ممکن است از تکرار برای افزایش یادآوری بیمار برای اجزای مهم درمان استفاده کند. راهکارهای حمایت از حافظه ویژه در هدف قرار دادن افسردگی در جوانان (دونگ، لی، و هاروی، 2017؛ هاروی و همکاران، 2016) و افراد بزرگسال (اسکاگین و همکاران، 2013) و GAD در سنین بالا استفاده شده است. برای راهکار های ویژه ای که ممکن است برای اصلاح درمان اجرا شوند، جدول 1 را ببینید.
روش دوم این است که با هدف اصلاح مهارت های شناختی به طور کلی تر، ارتقای شناختی را اعمال کنید. پزشکان می توانند CBT را با آموزش مهارت های شناختی ارتقا ببخشند زیرا نشان داده شده است که مهارت های شناختی ضعیف بر نتایج CBT تأثیر می گذارد (مهلمان & Gorman, 2005). این راهکار غیر اختصاصی در بزرگسالان جوان مبتلا به افسردگی تک قطبی امتحان شده است (Siegle, Ghinassi, & Thase, 2007)، اختلال دوقطبی( BD; دکرزباخ و همکاران، 2010)، و اختلال اضطراب اجتماعی (SAD؛ McEvoy و Perini، 2009)، و در بزرگسالان مسن مبتلا به GAD مهلمان )، 2008؛ مهلمان و Gorman، 2005)، اضطراب همزمان با بیماری پارکینسون (PD; مهلمان ، DeVito، Lauderdale و Dobkin، 2017) و اختلال انباشت (HD؛ Ayers، Wetherell، Golshan، & Saxena، 2011؛ Ayers و همکاران، 2009).
توضیحات: این مقاله انگلیسی در سال 2022 در الزویر چاپ شده و در سال 1401 در سایت ای ترجمه توسط مترجم کد T5481 ترجمه با کیفیت مبتدی گردیده است.
مقاله اینترنت اشیا برای شهرهای هوشمند
IV. AN EXPERIMENTAL STUDY: PADOVA SMART CITY
The framework discussed in this paper has already been successfully applied to a number of different use cases in the context of IoT systems. For instance, the experimental wireless sensor network testbed, with more than 300 nodes, deployed at the University of Padova [31], [32] has been designed according to these guidelines, and successfully used to realize proof-ofconcept demonstrations of smart grid [33] and health care [34] services.
In this section, we describe a practical implementation of an urban IoT, named “Padova Smart City,” that has been realized in the city of Padova; thanks to the collaboration between public and private parties, such as the municipality of Padova, which has sponsored the project, the Department of Information Engineering of the University of Padova, which has provided the theoretical background and the feasibility analysis of the project, and Patavina Technologies s.r.l.,9 a spin-off of the University of Padova specialized in the development of innovative IoT solutions, which has developed the IoT nodes and the control software.
The primary goal of Padova Smart City is to promote the early adoption of open data and ICT solutions in the public administration. The target application consists of a system for collecting environmental data and monitoring the public street lighting by means of wireless nodes, equipped with different kinds of sensors, placed on street light poles and connected to the Internet through a gateway unit. This system shall make it possible to collect interesting environmental parameters, such as CO level, air temperature and humidity, vibrations, noise, and so on, while providing a simple but accurate mechanism to check the correct operation of the public lighting system by measuring the light intensity at each post. Even if this system is a simple application of the IoT concept, it still involves a number of different devices and link layer technologies, thus being representative of most of the critical issues that need to be taken care of when designing an urban IoT.
IV. تحقیق تجربی: شهر هوشمند پادوا
چارچوب بحث شده در این مقاله اخیرا برای موقعیت های مختلف در سیستم های IoT به کار گرفته شده است. برای نمونه، بستر آزمایشی تجربی بی سیم با بیش از 300 گره که در دانشگاه پاودا توسعه یافته است (31) (32) با توجه قوانین طراحی شده است و با موفقیت برای درک مفهوم اثباتی استفاده شده است و تشریح کننده خدمات مدار های هوشمند (33) و درمان (34) می باشد.
در این بخش، کاربرد تجربی یک سیستم شهری اینترنت اشیا را در شهر پاودا توصیف کردیم که دلیل آن تعامل و مشارکت بین بخش های دولتی و خصوصی مثل شهرداری پاودا است که حمایت مالی پروژه توسط دپارتمان مهندسی اطلاعات دانشگاه پاودا انجام شده است که پیش زمینه تئوری و تحلیل کارایی پروژ s.s.i.r.9ه را برای دانشگاه پادوا انجام داده است که متخصص در زمینه توسعه راه حل های ابتکاری IoT است که برای گره های Iot و توسعه نرم افزاری ارائه شده است.
هدف اولیه شهر هوشمند چاودا، ارتقای کاربرد داده های آزاد و راه حل های ICT در امور اجرایی شهر است. کاربردهای هدف شامل سیستم گردآوری داده های محیطی و کنترل روشنایی عمومی از طریق گره های بی سیم است که مجهز به سنسورهای مختلف هستند که بر روی تیرهای برق نصب شده اند و از طریق درگاه به اینترنت متصل هستند. این سیستم امکان گردآوری پارامترهای محیطی جالب مثل سطح CO، دمای هوا و رطوبت، ارتعاش، صدا و غیره را فراهم می آورد در حالی که یک مکانیزم ساده اما دقیق برای کنترل عملیات مناسب سیستم روشنایی عمومی از طریق اندازه گیری شدت نور در هر پست فراهم می آورد. حتی اگر این سیستم کاربرد ساده مفهوم IoT باشد، همچنان شامل ابزار و فناوری های مختلف پیوندی است، بنابراین ، نمایانگر مسائل مهم است که باید در طراحی IoT شهری در نظر گرفته شوند. یک بررسی سطح بالا از انواع و نقش های ابزار موجود در این سیستم در ادامه آورده شده اند.
توضیحات: این مقاله انگلیسی در سال 2014 در آی تریپل ای چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T1714 با کیفیت مبتدی ترجمه گردیده است.
مقاله اعتماد و وفاداری برند: دیدگاه میانجی و تعدیل کننده
4. HYPOTHESES DEVELOPMENTS
4.1 Brand Trust and Brand Loyalty
Brand trust and brand loyalty have been classified as central aspects of brand management (Chaudhuri & Holbrook, 2001). Brand trust has been operationalized severally in the extant literature. For instance, Delgadoballester et al. [10] view brand trust as a state of feeling secure while interacting with a brand based on the discernment that the brand will remain dependable and responsible to satisfy the customer. Brand trust is also viewed as consumers’ inclination to rely on a brand (Chaudhri & Holbrook, 2001; Mobiman et al., 1993). Additionally, brand trust is perceived as expectations that are based on beliefs that a brand has specific features and traits that are consistent, competent and credible [13,12].
From the view of Garbine and Johnson [11], brand trust is an outcome of previous experiences and interactions and it mirrors the process of learning over time. This position is a corroboration of Keller and Krishnan's [22] position that brand involvement is an essential source of brand trust. Additionally, Morgan and Hunt [18] note that trust is an important factor in building loyalty as it establishes relationships that are considered with high value. In line with the foregoing, Kumar and Advani [25] intimate that high levels of trust in a brand enable customers to reduce perceived risk and facilitate repeat patronage of the brand which leads to loyalty. Consequent to these arguments, it stands to reason that consumers’ trust in a brand has a positive effect on consumer’s loyalty to the brand and therefore we argue that brand trust will positively and significantly predict brand loyalty.
4. تدوین فرضیات
4.1 اعتماد برند و وفاداری به برند
اعتماد برند و وفاداری ابعاد اصلی مدیریت برند را تشکیل می دهند(Chaudhuri & Holbrook, 2001) . مطالعات موجود به طور جداگانه اعتماد به برند را بررسی می کند. برای مثال، Delgadoballester et al. [10] ، اعتماد به برند را وضعیتی در نظر می گیرد که در آن مصرف کننده در هنگام تعامل با یک برند احساس امنیت بیشتری می کند و به این درک منتهی می شود که یک برند برای تامین نیازهای مصرف کنندگان خود قابل اعتماد و مسئول باقی خواهد ماند. اعتماد به یک برند یعنی تمایل مصرف کننده به تکیه کردن به آن برند (Chaudhri & Holbrook, 2001; Mobiman et al., 1993). علاوه بر این، اعتماد برند به انتظاراتی اتلاق می شود که معتقد است یک برند دارای ویژگی ها و خصیصه هایی از قبیل سازگاری، شایستگی و اعتبار می باشد [13,12].
دیدگاهGarbine and Johnson [11] بر این باور استوار است که اعتماد برند نتیجه تجربیات و تعاملات قبلی است و فرآیند یادگیری را در طور زمان منعکس می کند. این موقعیت اثباتی برای موضع Keller and Krishnan's [22] است که نشان می دهد مشارکت برند منبع اصلی اعتماد به برند است. به علاوه، Morgan and Hunt [18] ذکر کردند که اعتماد یکی از عوامل مهم در ایجاد وفاداری است چرا که روابط با ارزشی را ایجاد می کند. Kumar and Advani [25] ، با توجه به موارد فوق، خاطر نشان کردند که سطح بالایی از اعتماد به یک برند، ای امکان را به مشتریان می دهد که ریسک درک شده را کاهش دهند و حمایت مجدد از برند را که به وفاداری منجر می شود تسهیل کنند. تحلیل این بجث ها به این جمع بندی منتهی می شود که اعتماد مصرف کنندگان به برند اثر مثبتی بر وفاداری مصرفکننده به آن برند دارد و به همین ترتیب ما استدلال می کنیم که اعتماد برند، وفاداری به برند را به طور مثبت و قابل توجهی پیش بینی می کند.
توضیحات: این مقاله انگلیسی در سال 2019 در journalcjast چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T5177 با کیفیت مبتدی ترجمه گردیده است.
مقاله تقویت(افزایش) توسعه شهری پایدار از طریق برنامههای کاربردی شهر هوشمند
3. Research design
3.1 Research aim
Smart city applications address various environmental problems and challenges that cities with growing urbanization are facing today. These include traffic congestion, air pollution and waste disposal (Bhatta, 2010; Broere, 2012; Ferguson and Dickens, 1999). Moreover, software applications are a core component of the multi-layer architecture of the technology stack for smart cities (Komninos et al., 2014), as they act as integrators of heterogeneous ICT hardware, data, user engagement and urban processes (Tsarchopoulos et al., 2017). However, these applications vary significantly both in terms of purpose and in terms of function. Considering digital technologies as an enabling feature of smart cities, the questions we wish to discuss in this paper concern what kind of digital applications cities can currently use to tackle environmental issues, identify the main trends and detect gaps on technical and policy levels. Moreover, we examine whether these applications could attain the “zero vision” objective.
3.2 Research approach
To address these questions, we analyzed 32 applications addressing environmental sustainability issues that can be found in the Intelligent/Smart Cities Open Source (ICOS) community repository (ICOS, 2017). ICOS is a meta-repository for intelligent/ smart cities applications and solutions, addressed to city authorities and application developers with the aim of facilitating the uptake and implementation of smart city solutions (Komninos et al., 2016). Each application is categorized by the domain it serves (“Innovation Economy”, “Living in the city – Quality of life”, “City Infrastructure and utilities”, “City Governance” and “Generic”) (Table I), the type of software it uses, its technical characteristics and license type. These four domains correspond to the classic structuring elements of cities, the production and consumption subsystems, their network system and the pertinent government system (Castells, 1974). Based on their relevance with the topic of this paper, the applications selected for this research are included in the domains of “City infrastructure and Utilities” and “Living in the city – Quality of life” and they are listed in (Digital applications assessed [authors’ elaboration]).
3. طراحی تحقیق
3.1 هدف تحقیق
کاربردهای شهر هوشمند، مسائل و چالشهای زیستمحیطی مختلفی را مورد توجه قرار میدهد که شهرهای با شهرنشینی رو به رشد، امروزه با آن مواجه هستند. این موارد عبارتند از تراکم ترافیک، آلودگی هوا و دفع زباله (باتا، ۲۰۱۰ برویر، ۲۰۱۲ فرگوسن و دیکنز، ۱۹۹۹). علاوه بر این، برنامههای کاربردی نرمافزار یک جز اصلی از معماری چند لایه دسته فنآوری برای شهرهای هوشمند هستند، زیرا آنها به عنوان یکپارچه کنندههای سختافزار، داده، تعامل کاربر و فرآیندهای شهری فناوری اطلاعات و ارتباطات ICT ناهمگن عمل میکنند. (Komninos et al.,2014; Tsarchopoulos et al., 2017) با این حال، این کاربردها هم از نظر هدف و هم از نظر عملکرد به طور قابلتوجهی متفاوت هستند. با در نظر گرفتن فنآوریهای دیجیتال به عنوان یک ویژگی توانمند کننده شهرهای هوشمند، سوالاتی که در این مقاله مورد بحث قرار میگیرند، این نگرانی را ایجاد میکنند که شهرها در حال حاضر چه نوع برنامههای کاربردی دیجیتال را می توان برای مقابله با مسائل زیستمحیطی، شناسایی روندهای اصلی و شناسایی شکاف در سطوح فنی و سیاسی مورد استفاده قرار دهند. علاوه بر این، ما بررسی میکنیم که آیا این کاربردها میتوانند به هدف دید صفر دست یابند.
3.2 رویکرد تحقیق
برای پرداختن به این سوالات، ما ۳۲ برنامه کاربردی را تجزیه و تحلیل کردیم که به مسائل پایداری زیستمحیطی میپردازند که می توان آنها را در شهرهای هوشمند / هوشمند یافت که منبع جامعه را معرفی میکنند (ICOS). (ICOS, 2017) ICOS یک متا - مخزن برای کاربردها و راهحلهای شهرهای هوشمند / هوشمند است، که به مقامات شهری و توسعه دهندگان برنامههای کاربردی با هدف تسهیل جذب و اجرای راهحلهای شهر هوشمند میپردازد. (Komninos et al., 2016) هر برنامه کاربردی توسط دامنه خدماتی (اقتصاد نوآوری، زندگی در کیفیت زندگی شهر، زیرساخت و خدمات شهری، حاکمیت شهر و عمومی)(جدول ۱)، نوع نرمافزاری که استفاده میکند، ویژگیهای فنی و نوع مجوز آن طبقهبندی میشود. این چهار حوزه، با عناصر ساختاری کلاسیک شهرها، زیرسیستم های تولید و مصرف، سیستم شبکهای آنها و سیستم دولتی مربوطه، مطابقت دارند. (Castells, 1974) براساس ارتباط آنها با موضوع این مقاله، برنامههای کاربردی انتخاب شدهبرای این تحقیق شامل قلمرو زیرساختها و تاسیسات شهری و زندگی در کیفیت زندگی شهر است و در لیست قرار دارند (برنامههای دیجیتال ارزیابی شدهاند [ نویسندگان شرح و بسط ]).
توضیحات: این مقاله انگلیسی در سال 2018 در امرالد چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T4464 با کیفیت مبتدی ترجمه گردیده است.
مقاله مقایسه های اجتماعی در فیس بوک و آفلاین: رابطه با علائم افسردگی
2. Method
2.1. Research design
This study employed a cross-sectional correlational design.
2.2. Participants
The population of interest was Facebook users aged between 18 and 25 years as emerging adulthood is a key period for self-identity exploration (Arnett, 2000), inviting social comparisons. An a-priori analysis determined that to capture the small to moderate effect sizes reported in previous research (Feinstein et al., 2013; Hanna et al., 2017) at a statistical power of 0.08 and an alpha level of 0.05, a sample size of 167 participants would be required. The final sample recruited was 181 participants aged 18 to 25 years (M age = 21.90 years; SD = 2.14; 51 males, 130 females). Employment status of the sample was 71.2% employed, 43.6% students, 8.9% unemployed, and 1.1% homemakers. The median number of Facebook friends was 520 (SD = 496.51; range = 1–2500), and the median number of minutes spent on Facebook per day was 60 (SD = 71.47; range = 1–300).
2. روش
2.1. طراحی تحقیق
این مطالعه از یک طرح همبستگی مقطعی استفاده کردهاست.
2.2. شرکت کنندگان
جمعیت مورد نظر کاربران فیس بوک بودند که بین ۱۸ تا ۲۵ سال سن داشتند چون ظهور بزرگسالی یک دوره کلیدی برای اکتشاف هویت شخصی است و مقایسههای اجتماعی را دعوت میکند. (Arnett, 2000) یک تحلیل قیاسی مشخص کرد که برای ثبت اندازههای اثر کوچک تا متوسط گزارششده در تحقیقات قبلی (فاینشتاین و همکاران، ۲۰۱۳؛ هانا و همکاران، ۲۰۱۷)با قدرت آماری ۰.۰۸ و سطح آلفای ۰.۰۵، یک اندازه نمونه ۱۶۷ نفری مورد نیاز خواهد بود. نمونه نهایی به کار گرفتهشده ۱۸۱ شرکتکننده در محدوده سنی ۱۸ تا ۲۵ سال بود (۲۱.۹۰ سال= سن M ؛ SD = 2.14; 51مرد، ۱۳۰ زن). وضعیت اشتغال نمونه ۷۱.۲ درصد بود، ۴۳.۶ درصد دانشجو، ۸.۹ درصد بیکار و ۱.۱ درصد خانهدار بودند. میانه تعداد دوستان فیس بوک ۵۲۰ بود (۴۹۶.۵۱ SD =؛ محدوده = 1-2500)، و میانه تعداد دقایق صرفشده در فیس بوک در هر روز ۶۰ بود (۷۱.۴۷ SD =؛ محدوده = 1-3000).
توضیحات: این مقاله انگلیسی در سال 2019 در الزویر چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T5017 با کیفیت مبتدی ترجمه گردیده است.
مقاله یادگیری شکست ها با و بدون فناوری آموزشی: چه چیزی برای دانش آموزان زرنگ و تنبل اهمیت دارد؟
3. Results
We report analyses of the pretest results for both studies at first. Results of the posttest are reported for study 1 and study 2 separately before differences between high-achieving and low-achieving students are given.
3.1. Prior knowledge of fractions
First, we checked whether high-achieving and low-achieving students, girls and boys, and students from the three different intervention groups differed in terms of prior knowledge of fractions before the intervention. We used the pretest as a measure of this prior knowledge. Table 4 summarizes the results from the pretest for high-achieving students (left) and low-achieving students (right), respectively. Here, the mean number of items solved in the pretest are reported separately for the total sample, female and male students, and different intervention groups.
For our a priori appraisal of high-achieving and low-achieving students to be eligible, we expected the high-achieving students to have more prior knowledge of fractions than the low-achieving students before the intervention. As can be seen in Table 4, the data is in line with our expectation: high-achieving students solved on average 4.84 of the 10 items in the pretest, whereas low-achieving students only got a mean number of 2.28 items correct. Thus, there was a significant and large effect of the a priori achievement grouping—operationalized through different school tracks of the German three-track public school system—on the pretest scores, t(645.45) = 15.66, p < .001, d = 0.95, 95%CI [0.81, 1.10], in favor of the high-achieving students. Therefore, we concluded that our operationalization of high-achieving and lowachieving students is appropriatesystem—on the pretest scores, t(645.45) = 15.66, p < .001, d = 0.95, 95%CI [0.81, 1.10], in favor of the high-achieving students. Therefore, we concluded that our operationalization of high-achieving and lowachieving students is appropriate.
3. نتایج
ما در ابتدا تجزیه و تحلیل نتایج پیشآزمون را برای هر دو مطالعه گزارش میکنیم. نتایج پسآزمون برای مطالعه ۱ و مطالعه ۲ به طور جداگانه قبل از تفاوتهای بین دانش آموزان موفق و ناموفق گزارش شدهاست.
3.1. دانش قبلی کسرها
ابتدا، ما بررسی کردیم که آیا دانش آموزان موفق و ناموفق، دختران و پسران و دانش آموزان از سه گروه مداخله متفاوت از نظر دانش قبلی از کسر قبل از مداخله تفاوت دارند یا خیر. ما از پیشآزمون به عنوان معیاری از این دانش قبلی استفاده کردیم. جدول ۴ نتایج حاصل از پیشآزمون را به ترتیب برای دانش آموزان با پیشرفت بالا (چپ) و دانش آموزان با پیشرفت پایین (راست) خلاصه میکند. در اینجا، میانگین تعداد موارد حلشده در پیشآزمون به طور جداگانه برای کل نمونه، دانش آموزان دختر و پسر و گروههای مداخله مختلف گزارش شدهاست.
برای ارزیابی قبلی ما از دانش آموزان با پیشرفت بالا و دانش آموزان با پیشرفت پایین، ما انتظار داشتیم که دانش آموزان با پیشرفت بالا نسبت به دانش آموزان با پیشرفت پایین قبل از مداخله، دانش قبلی بیشتری در مورد کسر داشته باشند. همانطور که در جدول ۴ دیده میشود، دادهها در راستای انتظار ما هستند: دانش آموزان با پیشرفت بالا به طور متوسط ۴.۸۴ از ۱۰ مورد پیشآزمون را حل کردند، در حالی که به مطالعه با تعداد ۲.۲۸ مورد درست رسیدند. بنابراین، اثر قابلتوجه و بزرگی از گروهبندی پیشرفت قبلی وجود داشت - که از طریق مسیرهای مدرسه مختلف سیستم مدارس دولتی سه مرحله ای آلمان - در نمرات پیش آزمون t(645.45)=15.66, p < .001, d =0.95,95%CI [0.81, 1.10],، به نفع دانش آموزان با موفقیت بالا وجود. بنابراین، ما نتیجه گرفتیم که عملیاتی کردن دانش آموزان با با موفقیت بالا و دستیابی پایین مناسب است.
توضیحات: این مقاله انگلیسی در سال 2020 در الزویر چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T5400 با کیفیت مبتدی ترجمه گردیده است.
مقاله تمرین های مهندسی نرم افزار برای توسعه نرم افزارهای علمی: یک تحقیق نگاشتی سیستماتیک
3. Study design
In this section, we present the protocol of the systematic mapping study based on the guidelines described by Petersen et al. (2008).
3.1 Objectives and Research Questions
The goal of this study, expressed in the Goal-Question-Metrics (GQM) format (Basili et al., 1994), is to analyze the development of scientific software applications for the purpose of characterization and evaluation with respect to the software engineering practices employed and the quality attributes of interest from the point of view of researchers and practitioners. Based on this goal, we define the following research questions. To address the cross-cutting G3 (assess the level of empirical evidence that supports the use of SE practices in scientific software development), we have added sub-research questions in RQ2.
RQ1: Which SE practices used in the development of scientific software have researchers studied the most?
3. طرح تحقیق
در این بخش، ما پروتکل نگاشت سیستماتیک را بر اساس قوانین توصیف شده توسط پترسون و همکارانش در سال 2008 ارائه کرده ایم.
3.1. اهداف و سوالات تحقیق
هدف این تحقیق که در فرمت ماتریس هدف- سوال (GQM) (باسلی و همکاران 1994) ارائه شده است، تحلیل توسعه برنامه های نرم افزار علمی برای هدف توصیف و تکامل با توجه به تمرین های مهندسی نرم افزار مورد استفاده و شاخص های کیفیت مورد علاقه از چشم انداز محققان و دست اندرکاران می باشد. بر اساس این هدف، ما سوالات تحقیق زیر را بیان می کنیم. برای بیان معیار G3(ارزیابی سطح شواهد تجربی که استفاده از تمرین های SE را در توسعه نرم افزار علمی تائید می کنند)، چند سوال فرعی دیگر هم در RQ2 اضافه می کنیم.
RQ1: کدام یک از تمرین های SE مورد استفاده در توسعه نرم افزار علمی بیشتر توسط محققان مورد بررسی قرار گرفته است؟
توضیحات: این مقاله انگلیسی در سال 2021 در الزویر چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T4237 با کیفیت مبتدی ترجمه گردیده است.
مقاله مدیر کمیته حسابرسی دارای صلاحیت چهارگانه: مفاهیمی برای کنترل و کاهش فساد مالی
2.5. Quad-qualification: composite of (a) independence, (b) directorship experience and financial expertise, (c) bandwidth, and (d) stock ownership
As described earlier, monitoring effectiveness is contingent on the combined presence of three aspects of ability plus motivation. These four requisite qualifications collectively enhance the likelihood that a given audit committee director will be a superior monitor. Such a person is able to monitor vigilantly on behalf of shareholders and also be willing to do so.
These qualifications equip an audit committee director to withstand the prevalent social influence that suppresses effective monitoring. Prior research has demonstrated that over time CEOs attempt to persuade, ingratiate, threaten, and socialize independent directors to enlist into corrupt cultures (Khanna et al., 2015; Westphal and Khanna, 2003; Zyglidopoulos and Fleming, 2008). Such influence is essential to sustaining corrupt practices (Ashforth and Anand, 2003). By virtue of the ability to (a) be dispassionate, (b) be cognizant of such influence and stand up to executives in financial matters, (c) devote the requisite time and energy to keep a close watch, together with the drive to govern vigilantly, the quad-qualified audit committee director can effectively nullify such corrupting influence. If this director identifies a problem, he or she is likely to raise the alarm when others would not be able or willing to do so (Hambrick et al., 2015). Correspondingly, the quad-qualified audit committee director is effective in deterring financial corruption. Thus, we posited the following hypothesis:
Hypothesis 1. The presence of a quad-qualified audit committee director will reduce the likelihood of financial corruption.
2.5. صلاحیت چهارگانه: ترکیبی از (الف) استقلال، (ب) تجربه مدیریت و تخصص مالی، (ج) پهنای باند و (د) مالکیت سهام
همانطور که قبلا توضیح داده شد، موثر بودن نظارت مشروط به وجود سه جنبه توانایی به علاوه انگیزه هست. این چهار شایستگی ضروری مجموعا احتمال اینکه یک مدیر کمیته حسابرسی یک ناظر برتر شود را بیشتر می کند. چنین شخصی می تواند هوشیارانه از طرف سهامداران نظارت کند و همچنین مشتاق به انجام این کار است.
این شایستگی ها یک مدیر کمیته حسابرسی را برای مقاومت در برابر نفوذهای اجتماعی متداول که نظارت موثر را سرکوب می کنند، تجهیز می کند. تحقیقات پیشین نشان داده اند که به مرور زمان مدیران عامل تلاش می کنند که مدیران موثر را برای این که به فرهنگ فاسد دعوت کنند ترقیب می کنند، مورد توجه قرار می دهند، تهدید می کنند و یا با آنها معاشرت می کنند (Khanna et al., 2015; Westphal and Khanna, 2003; Zyglidopoulos and Fleming, 2008). چنین تاثیری برای حفظ اقدامات فاسد ضروری است (Ashforth and Anand, 2003). به دلیل توانایی (الف) بی طرف بودن، (ب) آگاه بودن از چنین نفودی و ایستادگی کردن در برابر مدیران در امور مالی، (ج) اختصاص دادن زمان و انرژی لازم برای اینکه به دقت زیر نظر داشته باشد، به همراه انگیزه برای نظارت هوشیارانه، مدیر کمیته حسابرسی دارای صلاحیت چهارگانه به طور موثری می تواند چنین نفوذ فساد آوری را خنثی کند. اگر این مدیر مشکلی را شناسایی کند، احتمال دارد زمانی که دیگران نمی خواهند یا قادر نیستند زنگ خطر را به صدا دربیاورد (Hambrick et al., 2015). متقابلا، مدیر کمیته حسابرسی دارای صلاحیت چهارگانه در تشخیص فساد مالی موثر است. بنابراین، ما فرضیه زیر را مطرح کردیم:
فرضیه 1. حضور مدیر کمیته حسابرسی دارای صلاحیت چهارگانه احتمال فساد مالی را کاهش خواهد داد.
توضیحات: این مقاله انگلیسی در سال 2021 در الزویر چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T5417 با کیفیت مبتدی ترجمه گردیده است.
مقاله برآورد پتانسیل روانگرایی خاک: یک مورد مطالعاتی برای شهر مولویبازار(Moulvibazar)، سیلهت(Sylhet)، بنگلادش(Bangladesh)
4. Results and discussion
The LPI values of 25 SPT-N profles and other information are provided in Table 4. The liquefaction hazard map for Moulvibazar town has been prepared based on the LPI values and cumulative frequency distribution of the LPI values for each unit Fig. 6. The contour lines of equal LPI values have been drawn at an interval of 5 LPI value to predict the LPI values for the areas where the SPT-N profles are not available. The liquefaction hazard map also represents the likelihood of surface manifestation of liquefaction of each surface geological unit as percentage, where the LPI value is equal to or greater than 5. Thus, the study area is divided into two liquefaction hazard zones based on the surface geological units: Zone 1 (Holo–Pleistocene low elevated terrace deposits) and Zone 2 (Holocene food plain deposits). Zone 1 covers southeastern corner of the mapped area that contains fve LPI values, and Zone 2 covers rest of the mapped area that contains twenty LPI values.
Cumulative frequency distribution of LPI is a quantitative approach to estimate how much area of a surface geological unit will show surface manifestation of liquefaction. Large and small percentage of area predicted to liquefy by cumulative frequency distribution of LPI is consistent with historical earthquake [12]. However, in Zone 1, 42% of the total area will show surface manifestation of liquefaction, whereas in Zone 2, 78% of total area will show surface manifestation of liquefaction
4. نتایج و بحث
مقادیر LPI بیست و پنج پروفیل SPT-N و دیگر اطلاعات در جدول 4 ارائه شده اند. نقشه خطر روانگرایی برای شهر مولویبازار بر اساس مقادیر LPI و توزیع فراوانی تجمعی هر واحد در شکل 6 آماده شده اند. خطوط تراز مقادیر LPI با فاصله های 5 واحد LPI رسم شده اند تا مقادیر LPI در نواحی که پروفیل SPT-N آنها موجود نیست، پیش بینی شود. همچنین نقشه خطر روانگرایی، احتمال جلوه سطحی روانگرایی را برای هر واحد سطحی زمین شناختی که مقدار LPI آن بزرگتر یا مساوی 5 است، توسط درصد نشان می دهد. بنابراین، محل مورد مطالعه بر اساس واحد سطحی زمین شناختی به دو ناحیه خطر روانگرایی تقسیم شده است: ناحیه 1 (ذخایر کم ارتفاع هولو-پلیستوسین) و ناحیه 2 (ذخایر دشت سیلابی هولوسین). ناحیه 1 گوشه جنوب شرقی مساحت نقشه برداری شده را پوشش می دهد که شامل 5 مقدار LPI است و ناحیه 2 بقیه مساحت نقشه برداری شده را پوشش می دهد که شامل بیست مقدار LPI است.
توزیع فراوانی تجمعی LPI یک رویکرد کمی برای تخمین مساحتی از یک واحد سطحی زمین شناختی است که جلوه روانگرایی سطحی نشان می دهد. درصد های کوچک و بزرگ مساحت پیش بینی شده با توزیع فراوانی تجمعی LPI در زلزله های تاریخی ثابت است[12] . با این وجود، در ناحیه 1، 42% از مساحت کل جلوه سطحی روانگرایی را نشان خواهد داد؛ در حالی که، در ناحیه 2، 78% مساحت کل جلوه سطحی روانگرایی را نشان خواهد داد.
توضیحات: این مقاله انگلیسی در سال 2020 در اشپرینگر چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T5427 با کیفیت مبتدی ترجمه گردیده است.
مقاله شهرهای هوشمند: چالشی برای تحقیق و تجزیه و تحلیل سیاست
Smart urban analytics and policy: editorial introduction
In the ‘century of the city’, with an increasing share of the world population living in urban agglomerations, cities have not only increased in number and size, but have also turned into complex and multi-faceted organisms. A modern city is no longer a simple settlement system with buildings, infrastructure and people, but displays nonlinear evolutionary structures and trajectories as a result of an underlying complex force field comprising a multiplicity of (internal and external) actors and of (tangible and immaterial) constituents that altogether shape contemporaneous city life. Urbanity has become a “modus vivendi” of the 21st century, in which urban agglomerations are the geographic projections of an emerging new society characterized by connectivity, mobility and flexibility.
The complexity of ever growing cities in this world prompts serious policy concerns regarding environmental quality, energy use, transport accessibility, social cohesion, labour and housing markets, public amenities, safety, effective governance, local well-being, and so forth. To cope with all these challenges – and many more – in the harsh reality of urban policy and management, city authorities have over the years often resorted to sectoral responses, without sufficient regard of the interwovenness of a complex urban system and without carefully basing necessary urban decisions and adjustments on a solid and verified information base that maps out the multidimensional complexity of the urban area concerned. Consequently, urban policy tends to become fragmented and not supported by quantitative accountability and solid test principles.
تحلیل و سیاست هوشمند شهری: معرفی سرمقاله
در قرن شهر، با افزایش سهم جمعیت جهان که در مراکز شهری زندگی میکنند، شهرها نه تنها از نظر تعداد و اندازه افزایشیافته اند، بلکه به ارگانیزمهای پیچیده و چند وجهی تبدیل شدهاند. شهر مدرن دیگر یک سیستم اسکان ساده با ساختمانها، زیرساختها و مردم نیست، بلکه سازهها و مسیرهای تکاملی غیرخطی را در نتیجه یک زمینه نیروی پیچیده اساسی شامل تعدد عوامل (داخلی و خارجی) و اجزای (ملموس و غیرمادی) نشان میدهد که در مجموع زندگی شهری معاصر را شکل میدهند. شهرنشینی به مدلی از قرن بیست و یکم تبدیل شدهاست که در آن، تراکم شهری، پیشبینیهای جغرافیایی یک جامعه جدید نوظهور است که ویژگی آن اتصال، تحرک و انعطافپذیری است.
پیچیدگی شهرهای در حال رشد در این جهان، نگرانیهای سیاسی جدی در رابطه با کیفیت زیستمحیطی، استفاده از انرژی، دسترسی به حمل و نقل، انسجام اجتماعی، بازار کار و مسکن، امکانات عمومی، ایمنی، حاکمیت موثر، رفاه محلی، و غیره را برانگیخته است. مقامات شهری، برای مقابله با تمام این چالشها و بسیاری موارد دیگر در واقعیت خشن سیاست و مدیریت شهری، در طول سالها، اغلب به پاسخهای بخشی متوسل شدهاند، بدون توجه کافی به پیچیدگی سیستم شهری پیچیده و بدون مبنا قرار دادن دقیق تصمیمات و تنظیمات ضروری شهری بر پایه اطلاعات محکم و تایید شدهای که پیچیدگی چند بعدی منطقه شهری مربوطه را ترسیم میکند. در نتیجه، سیاست شهری معمولا تکهتکه میشود و توسط پاسخگویی کمی و اصول آزمون یکپارچه پشتیبانی نمیشود.
توضیحات: این مقاله انگلیسی در سال 2018 در الزویر چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T5400 با کیفیت مبتدی ترجمه گردیده است.
مقاله بازیابی تصویر پوشش منفی رسانه ای از مسابقه ورزش: ملاحظات، مسابقه ،مقصد و مکان
1. Events in destination branding
Destinations often bid for and host large international events with the intention to help shape the image and profile of the city (Xing & Chalip, 2006). Destination image is, ‘‘the sum of beliefs, ideas, and impressions that a person has of a destination’’ (Crompton, 1979, p. 18). How visitors perceive the destination contributes to the location’s ability to attract tourists and maintain competitiveness. Hosting large international sport events such as the Commonwealth Games provides increased media exposure and attention to the host city and country (Green, 2002). Destinations often utilize events in their destination marketing efforts to increase both direct, which includes visitor expenditure during the actual event, and indirect tourism that focuses on the effects the media coverage of the event has on brand awareness and recognition of the destination as an attractive location to tourists (Chalip, Green, & Hill, 2003; Getz & Fairley, 2004).
Likewise, the event also seeks to create a strong brand image. Keller (1993) defined brand image as consumer-held perceptions as determined by brand associations. These associations are linked in memory and create meaning of the brand for the consumer (Keller, 1993). Events provide these linkages between the brand image of the host community and the events it hosts (Chalip, 2004). Due to these linkages, potentially reciprocal effects and transfer of image of event to destination and destination to event through strategic marketing initiatives could possibly be expected (Brown, Chalip, Jago, & Mules, 2004). Xing and Chalip (2006) suggested that events seem to have a bigger impact on the destination’s image than vice versa, with size and status of the event as key determinants of sport event image (Gwinner, 1997). Thus, it is useful for students to consider the role of events in destination branding.
1. رویدادها در مارک تجاری مقصد
مقاصد غالباً با هدف کمک به شکل دادن به تصویر و ظاهر شهر ، مسابقات بزرگ بین المللی را پیشنهاد می دهند و میزبان آنها هستند (Xing & Chalip، 2006). تصویر ذهنی مقصد "مجموع اعتقادات ، ایده ها و برداشت هایی است که شخص از مقصد دارد" (Crompton، 1979، p. 18). نحوه فهم بازدیدکنندگان از مقصد به توانایی مکان در جذب گردشگر و حفظ رقابت کمک می کند. میزبانی مسابقات بزرگ ورزشی بین المللی مانند بازی های مشترک المنافع باعث افزایش توجه رسانه ها و توجه به شهر و کشور میزبان می شود (گرین ، 2002). مقاصد معمولاً از مسابقات در تلاش های بازاریابی اهداف خود استفاده می کند تا هم مستقیم افزایش یابد ، که شامل هزینه بازدیدکننده در حین مسابقه واقعی است و هم گردشگری غیرمستقیم که بر تأثیرات پوشش رسانه ای این مسابقه بر آگاهی از مارک و شناخت مقصد به عنوان یک مکان جذاب متمرکز است (Chalip، Green، & Hill، 2003؛ Getz & Fairley، 2004).
به این ترتیب ، این مسابقه همچنین به دنبال ایجاد یک تصویر تجاری قوی است. Keller (1993) تصویر برند را به عنوان فهم مصرف کننده تعریف می کند که توسط انجمن های تجاری تعیین می شود. این ارتباطات با حافظه در ارتباط هستند و معنای نام تجاری را برای مصرف کننده ایجاد می کنند (Keller، 1993). مسابقات این ارتباطات را بین تصویر برند جامعه میزبان و مسابقاتی که میزبان آن است فراهم می کند (Chalip، 2004). با توجه به این ارتباطات ، احتمالاً انتظار این است تاثیر متقابل انتقال تصویر مسابقه به مقصد و مقصد به مسابقه از طریق خلاقیت های استراتژیک بازاریابی پیش بینی شود (براون ، چلیپ ، ژاگو و مولس ، 2004). زینگ و چالیپ (2006) اعلام نمودند که به نظر می رسد مسابقات با توجه به اندازه و وضعیت مسابقه به عنوان عوامل اصلی تعیین کننده تصویر مسابقه ورزشی ، تأثیر بیشتری بر تصویر ذهنی مقصد داشته باشند (گوینر ، 1997). بنابراین ، برای دانشجویان مفید است که نقش مسابقات را در مارک تجاری مقصد در نظر بگیرند.
توضیحات: این مقاله انگلیسی در سال 2016 در الزویر چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T5506 با کیفیت مبتدی ترجمه گردیده است.
مقاله سیستم نظارت بر آبزی پروری مزرعه ماهی خودکار مبتنی بر اینترنت اشیاء
I. INTRODUCTION
Aquaculture is one of the thriving areas in many countries in the world since demand for fish and the fish prepared food is expanding day by day. According to The United Nations Food and Agriculture Organization (UNFAO) "2012 State of World Fisheries and Aquaculture ", Worldwide yearly production of fishery items add up to around 128 million tons. The animal protein intake per individual is about 15% and increase the human reliance on fishery resources. The average consumption of fish products is 19 to 20 kg per person per year today and will be 16.7 kg per year in 2030 according to UNFAO. Production of fisheries, advancement and future food needs are firmly related [1].
Aquaculture comprises of the set of exercises, information and techniques for the rearing of aquatic plants and a few animal groups. This activity has an awesome significance in financial improvement and food production. Commercial aquaculture is confronting numerous issues because of sudden climatic vacillation leading to changes in water quality parameters. Aqua farmers are relying upon manual testing for knowing the condition of the various parameters of the water. But this manual testing is time consuming and also give inappropriate results as parameters for measuring water quality changes continuously. It will be better if automatic monitoring can be done somehow. So modern technology should be brought to aquaculture to overcome this problem. For rural development, technologies have to support several key application areas, for example, living quality, wellbeing, environmental change etc. [20]. So we have to be more selective in choosing the appropriate technologies for this kind of advancement.
An integrated on chip computer Raspberry Pi is used in our system as data processing and storing device which has an inbuilt Wi-Fi module. Using the Dataplicity service we can also access the Raspberry Pi through internet [18]. So, no additional Wi-Fi or Internet module is required. Smartphones are very obtainable and most of the smartphones have Media Transfer Protocol(MTP) today. Using these and performing some analysis on the water quality parameters make our work unique.
I. مقدمه
در بسیاری از کشورهای جهان آبزی پروری یکی از حیطه های رو به پیشرفت بوده است چون تقاضا برای ماهی و غذاهای حاوی ماهی روز به روز افزایش می یابد. طبق «وضعیت شیلات و آبزی پروری جهان در سال 2012» سازمان خواربار و کشاورزی ملل متحد (UNFAO)، تولید سالانه جهانی اقلام شیلات بالغ بر 128 میلیون تن است. جذب پروتئین حیوانی به ازای هر فرد حدود 15 درصد است و این سبب افزایش وابستگی انسان به منابع شیلات می گردد. طبق گفته UNFAO امروزه میانگین مصرف محصولات ماهی به ازای هر فرد 19 تا 20 کیلوگرم در سال است و در سال 2030 به 16.7 کیلوگرم در سال می رسد. تولید شیلات، پیشرفت و نیازهای غذایی آینده ارتباط مهمی با هم دارند [1].
آبزی پروری شامل یک سری تمرینات، اطلاعات و تکنیک ها برای پرورش گیاهان آبزی و چندین گروه از حیوانات است. این فعالیت اهمیت زیادی در بهبود مالی و تولید غذا دارد. بخاطر نوسانات جوی ناگهانی که منجر به تغییراتی در پارامترهای کیفیت آب می گردند، آبزی پروری تجاری با مشکلات متعددی مواجه شده است. کشاورزان محصولات آبزی برای آگاه شدن از شرایط پارامترهای مختلف آب از آزمایشات دستی استفاده می کنند. اما این آزمایشات دستی زمان بر است و همچنین به نتایج نامناسبی ختم می شود چون پارامترهای موجود برای ارزیابی کیفیت آب مدام تغییر می کنند. بنابراین بهتر است که نوعی نظارت خودکار صورت گیرد. بنابراین تکنولوژی مدرن باید به آبزی پروری وارد گردد تا این مشکل حل شود. برای توسعه روستایی، تکنولوژی ها باید از چندین حیطه کاربرد کلیدی همچون کیفیت زندگی، رفاه، تغییرات محیطی و غیره پشتیبانی کنند [20]. لذا ما باید در انتخاب تکنولوژی های مناسب برای این نوع پیشرفت، دقت بیشتری به خرج دهیم.
ما از یک دستگاه اضافه (و یکپارچه) شده به تراشه کامپیوتر رزبری پای در سیستم خود برای پردازش داده و ذخیره سازی استفاده می کنیم که دارای یک ماژول وای فای توکار است. ما با استفاده از سرویس Dataplicity می توانیم از طریق اینترنت به رزبری پای دسترسی پیدا کنیم [18]. بنابراین ما به هیچ ماژول اینترنت یا وای فای دیگر نیاز نخواهیم داشت. تلفن های هوشمند به راحتی در دسترس هستند و امروزه اغلب این تلفن ها دارای پروتکل انتقال رسانه (MTP) هستند. ما با استفاده از این تلفن های هوشمند و با انجام برخی تحلیل ها بر روی پارامترهای کیفیت آب، یک مطالعه منحصر به فرد را انجام می دهیم.
توضیحات: این مقاله انگلیسی در سال 2018 در آی تریپل ای چاپ شده و در سال 1401 در سایت ای ترجمه توسط مترجم کد T2383 ترجمه گردیده است.
مقاله تشخیص چهره سریع عمیق کونولوشن در Wild Exploiting Hard Sample Minig
3.2. CNN Architecture
Firstly, a fully-convolutional CNN comprised of seven convolutional layers was trained with RGB images of size 32 × 32, the architecture of which corresponds to the top part of the network shown in Figure 2. Table 1 displays the trained architecture of this network as well as the number of trainable parameters, where conv accompanied by an index denotes a convolutional layer and prelu accompanied by the same index denotes the respective activation layer. In between successive activation and convolutional layers, dropout layers are added, which have been shown to improve the performance of FNNs by allowing for better generalization [64]. A softmax function is applied to the output of the last convolutional layer, which produces probabilities for the two different detection scores, each one corresponding to the two classes of the detection task (e.g., face, non-face). Channel-wise parameters were learned for each PReLU layer. In total, the training of 76,376 free parameters is required for this network. The architecture of the network has been designed having in mind the constraint of a very fast face detector that will require minimum GPU memory and will be appropriate for large-scale visual information analysis and real-time face detection in the wild. Decisions regarding the number of the filters, the type of activations, the training procedures have been made by studying all the relevant bibliography and heavy experimentation with the large dataset that has been used for training.
Additionally, a second network consisting of four convolutional layers interspersed by three dropout layers for the task of facial parts detection was trained with RGB images of size 16 × 16. The output of the network is comprised of four detection scores, each one corresponding to the four classes of the facial parts (e.g., mouth, nose, eyes, irrelevant). The architecture of this CNN is also summarized in Figure 2 and Table 2. A total of 20,088 free parameters require training for this network.
3.2. معماری CNN
در ابتدا، CNN کاملا کانولوشن، از 7 لایه کانولوشن تشکیل شده است که با استفاده از تصاویر RGB با سایز 32*32 آموزش داده شده است، که معماری آن متناظر به قسمت بالایی شبکه نشان داده شده در شکل 2 می باشد. جدول 1 معماری آموزش دیده این شبکه و نیز تعداد پارامترهای قابل آموزش را نشان می دهد، که در آن conv با یک شاخص که نشان دهنده لایه کانولوشن می باشد و prelu بوسیله همان شاخص که نشان دهنده لایه فعالسازی نسبی می باشد، نشان داده می شود. در بین لایه های کانولوشن و فعالسازی متوالی، لایه های حذف شدن ، اضافه شده اند که جهت بهبود عملکرد FNN با فراهم نمودن امکان بهتری برای تعمیم، نشان داده شده اند[64]. تابع softmax به خروجی لایه قبلی کانولوشن اعمال شده است که احتمالاتی را برای خروجی لایه کانولوشن آخری اعمال می نماید که هر یک متناظر با دو کلاس تشخیص وظیفه هستند( به عنوان مثال صورت، غیره صورت). پارامترهای کانال برای هر لایه PReLU آموزش دیده اند. درکل، آموزش 76376 پارامتر آزاد برای این شبکه مورد نیاز است. معماری شبکه با در نظر گرفتن این نکته که محدودیتهای تشخیص دهنده بسیار سریع صورت نیازمند حداقل حافظه GPU می باشد و برای آنالیز اطلاعات تصویری مقیاس بزرگ و تشخیص چهره مناسب خواهد بود، طراحی شده است. تصمیمات با توجه به تعداد فیلترها، نوع فعالیت ، فرایند آموزش با مطالعه تمامی مراجع مرتبط و آزمایشات سنگین با استفاده از مجموعه داده های بزرگ که برای آموزش به کار رفته، انجام شده است.
علاوه بر این، شبکه دوم که شامل 4 لایه کانولوشن می باشد که بوسیله سه لایه حذفی برای وظیفه تشخیص اجزای چهره توسط تصاویر RGB با سایز 16*16 آموزش دیده است، جدا شده است. خروجی شبکه از چهار امتیاز تشخیص چهره تشکیل شده است که هر یک متناظر با چهار کلاس اجزای صورت می باشد( به عنوان مثال دهان، دماغ، چشم، نامربوط). معماری این CNN در شکل 2 به طور خلاصه نشان داده شده است. در مجموع 20088 پارامتر آزاد نیازمند یادگیری این شبکه هستند.
توضیحات: این مقاله انگلیسی در سال 2018 در الزویر چاپ شده و در سال 1401 در سایت ای ترجمه توسط مترجم کد T5728 ترجمه گردیده است.
مقاله تاثیرات رسانه های اجتماعی بر دانشجویان دانشگاه در عراق
4. Results and disscusion
4.1. General results analysis
We also review the results. Here, in the answer to the first question, we find that a clear majority believes that there are positive impacts on the utilize of social media. In the second question, many see themselves as vulnerable to privacy violations and blackmail while using social media. In the third question, we see a high percentage of those who sometimes see the possibility of social media negatively affecting their health and, to a lesser extent, In the fourth question, the answer was clear to a majority of those with a common belief that their use of the social media exposed them to addiction. However, the answer to the fifth question gave us a significant majority who see the importance of social media as an important factor in awareness Society and in the sixth question, there is also an absolute majority do not use fake pages on social media. In the seventh question shows us the most widely used website by Facebook is very distinctive. In the eighth question, there are varying percentages of them who believe that the personal data is reserved, confidential and reliable on their accounts in the social media. The ninth question is that we have the impression that the majority of them easily use these means with the simple access to information. In question 10, Its negative media impact is negative on the real social community between family, relatives and friends. In this question, we conclude with the eleventh question that the nature of the use of these means of social communication is to browse in a majority and preference.
4. نتایج و بحث
4.1. تحلیل نتایج کلی
نتایج را نیز بررسی خواهیم کرد. در اینجا، در پاسخ به سوال اول، دریافتیم که اکثریت بر این باورند که ادراک مثبتی درباره کاربرد رسانه های اجتماعی وجود دارد. در سوال دوم، بسیاری افراد خود را در برابر نقض حریم خصوصی و تهدید، هنگام استفاده از رسانه های اجتماعی، آسیب پذیر می دانند. در سوال سوم، درصد بالایی از افرادی را می بینیم که تصور می کنند که استفاده رسانه های اجتماعی بر سلامت آنها تاثیر منفی دارد، و به میزانی کمتر در سوال چهارم، پاسخ این بود که اکثر افراد بر این باور بودند که استفاده از رسانه های اجتماعی آنها را در معرض اعتیاد قرار می دهد. با این وجود، در پاسخ به سوال پاسخ اکثریت قابل توجهی از افراد را می بینیم که به اهمیت رسانه های اجتماعی به عنوان یک عامل مهم در آگاهی اجتماعی پی بردند و در سوال ششم، اکثریتی وجود دارد که از صفحات تقلبی در رسانه های اجتماعی استفاده نمی کنند. سوال هفتم، به ما نشان می دهد که وب سایتی که به طور گسترده مورد استفاده قرار می گیرد؛ فیس بوک، بسیار شاخص است. در سوال هشتم، درصد افرادی که معتقدند اطلاعات شخصی در زمینه حساب های آنها در رسانه های اجتماعی محرمانه و قابل اطمینان است، متغیر است. سوال نهم، در این مورد است که ما تصور می کنیم که اکثر افراد با دسترسی ساده به اطلاعات، به راحتی از این ابزارها استفاده می کنند. در سوال دهم، تاثیر منفی رسانه های اجتماعی بر جوامع اجتماعی واقعی بین خانواده، اقوم و دوستان، منفی است. در این سوال، با سوال یازدهم به پایان می رسانیم، که مربوط به این موضوع است که ماهیت استفاده از ابزارها ارتباطات اجتماعی جستجو در اکثریت و بررسی الویت ها است.
توضیحات: این مقاله انگلیسی در سال 2020 در الزویر چاپ شده و در سال 1400 در سایت ای ترجمه توسط مترجم کد T4062 ترجمه گردیده است.
مقاله رد فرضیه پدیدآمدن ویروس کرونای نوظهور (2019-nCoV) در نتیجه یک رخداد نوترکیبی اخیر با ارزیابی تکاملی ژنوم کامل
Abstract
Background: A novel coronavirus (2019-nCoV) associated with human to human transmission and severe human infection has been recently reported from the city of Wuhan in China. Our objectives were to characterize the genetic relationships of the 2019-nCoV and to search for putative recombination within the subgenus of sarbecovirus.
Methods: Putative recombination was investigated by RDP4 and Simplot v3.5.1 and discordant phylogenetic clustering in individual genomic fragments was confirmed by phylogenetic analysis using maximum likelihood and Bayesian methods.
Results: Our analysis suggests that the 2019-nCoV although closely related to BatCoV RaTG13 sequence throughout the genome (sequence similarity 96.3%), shows discordant clustering with the Bat_SARS-like coronavirus sequences. Specifically, in the 5′-part spanning the first 11,498 nucleotides and the last 3′-part spanning 24,341–30,696 positions, 2019-nCoV and RaTG13 formed a single cluster with Bat_SARS-like coronavirus sequences, whereas in the middle region spanning the 3′-end of ORF1a, the ORF1b and almost half of the spike regions, 2019-nCoV and RaTG13 grouped in a separate distant lineage within the sarbecovirus branch.
Conclusions: The levels of genetic similarity between the 2019-nCoV and RaTG13 suggest that the latter does not provide the exact variant that caused the outbreak in humans, but the hypothesis that 2019-nCoV has originated from bats is very likely. We show evidence that the novel coronavirus (2019-nCov) is not-mosaic consisting in almost half of its genome of a distinct lineage within the betacoronavirus. These genomic features and their potential association with virus characteristics and virulence in humans need further attention.
The family Coronaviridae includes a large number of viruses that in nature are found in birds and mammals (Kahn and McIntosh, 2005; Fehr and Perlman, 2015). Human coronaviruses, first characterized in the 1960s, are associated with a large percentage of respiratory infections both in children and adults (Kahn and McIntosh, 2005; Paules et al., 2020).
Scientific interest in Coronaviruses exponentially increased after the emergence of SARS-Coronavirus (SARS-CoV) in Southern China (Drosten et al., 2003; Ksiazek et al., 2003; Peiris et al., 2003). Its rapid spread led to the global appearance of more than 8000 human cases and 774 deaths (Kahn and McIntosh, 2005). The virus was initially detected in Himalayan palm civets (Guan et al., 2003) that may have served as an amplification host; the civet virus contained a 29-nucleotide sequence not found in most human isolates that were related to the global epidemic (Guan et al., 2003).
چکیده
پیش زمینه: اخیراً کروناویروس نوظهوری (2019-nCoV) در ارتباط با انتقال انسان به انسان و عفونت شدید در انسان ها در شهر ووهان چین گزارش شده است. هدف ما توصیف روابط ژنتیکی کروناویروس نوظهور و جست و جو برای یافتن نوترکیبی مفروض در بین زیرسرده ساربکوویروس بوده است.
روشها: نوترکیبی مفروض با استفاده از برنامه های RDP4 و Simplot نسخه 3.5.1 مورد بررسی قرار گرفت و خوشه بندی تبارزایشی نامتجانس در قطعات ژنومی واحد با کمک ارزیابی تبارزاشی و با استفاده از بزرگنمایی بیشینه و روش های بیزی تایید گردید.
نتایج: ارزیابی ما مطرح کننده آن است که گرچه کروناویروس نوظهور در سراسر ژنوم خود ارتباط نزدیکی با توالی RaTG13 کروناویروس خفاشی دارد (شباهت توالی 96.3%)، خوشه بندی نامتجانسی با توالی های کروناویروس های شبه سارس خفاشی (bat-SARS like) از خود نشان می دهد. به ویژه، در بخش 5 دربردارنده ی 11498 نوکلئوتید اول و بخش نهایی 3 دربردارنده جایگاه های 30696-24341، کروناویروس نوظهور و RaTG13 با توالی های کروناویروس شبه سارس خفاشی خوشه ی واحدی تشکیل می دهند، درحالیکه در ناحیه میانی شامل انتهای 3 ORF1a، ORF1b و تقریبا نیمی از نواحی زوائد گرزی شکل، کروناویروس نوظهور و RaTG13 در دودمان مجزایی با فاصله از کروناویروس خفاشی در درون شاخه ساربکوویروس گروه بندی شده اند.
جمع بندی: سطوح شباهت ژنتیکی در بین کروناویروس نوظهور 2019 و RaTG13 بیانگر آن است که دومی نوعِ به خصوصی که عامل همه گیری در انسان هاست را ارائه نمی کند، اما این فرضیه که کروناویروس نوظهور از خفاش ها به وجود آمده است، بسیار محتمل می باشد. ما شواهدی را ارائه می نماییم که مطرح می کند کروناویروس نوظهور (2019-nCoV) موزائیکی نبوده و در دست کم نیمی از ژنوم خود از یک دودمان منحصر به فرد در بتاکروناویروس ها تشکیل شده است. این خصوصیات ژنومی و هم بستگی بالقوه ی آنها با ویژگی های ویروس و بیماری زایی در انسان ها درخور توجه آتی است.
خانواده کروناویریده شامل تعداد زیادی از ویروس هایی است که در طبیعت در پرندگان و پستانداران یافت می گردند (کان و مکاینتاش، 2005؛ فر و پرلمن، 2015 ). کروناویروس های انسانی که نخست در دهه 1960 توصیف شدند، در ایجاد درصد بالایی از عفونت های تنفسی هم در کودکان و هم در بزرگسالان نقش دارند (کان و مکاینتاش، 2005؛ پالز و همکاران، 2020 ).
گرایش علمی به کروناویروس ها پس از ظهور کروناویروس عامل سارس (SARS-CoV) در جنوب چین به طور تصاعدی افزایش یافت (دروستن و همکاران، 2003؛ شازک و همکاران، 2003؛ پیریز و همکاران، 2003 ). انتشار سریع آن منجر به بروز جهانی بیش از 8000 مورد انسانی و 774 مرگ گردید (کان و مکاینتاش ). ویروس نخست در زبادهای نخلی هیمالیا شناسایی گردید (گوان و همکاران، 2003 ). این حیوانات می توانند نقش یک میزبان تقویت کننده را ایفا نمایند؛ ویروس در زباد حاوی یک توالی 29 نوکلئوتیدی بود که در اکثر نمونه های جداسازی شده از انسان که در ارتباط با اپیدمی جهانی بوده اند، یافت نشده است (گوان و همکاران، 2003 ).
توضیحات: این مقاله انگلیسی در سال 2020 در الزویر چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T4390 ترجمه گردیده است.
مقاله رواج افسردگی و تاثیر آن بر کیفیت زندگی پرستاران خط مقدم بخش های اورژانس در حین شیوع ویروس کرونا
2.2. Instruments
Basic demographic information included gender, age, marital status, educational background, work experience, shift duty, living circumstances, rank (junior/senior), type of hospital (primary/tertiary), work place (inpatient/outpatient), current smoking status, and work experience during the 2003 Severe Acute Respiratory Syndrome (SARS) outbreak. Nurses were also asked three additional standardized questions whether (1) they were directly engaged in clinical services for patients with COVID-19; (2) their family, friends or colleagues were infected with the COVID-19; and (3) there were 500 or more confirmed COVID19 cases in the province where they lived/worked.
Depression was measured with the Patient Health Questionnaire (PHQ)-Chinese version. The PHQ is a 9-item self-report instrument, which is widely used in clinical settings. Each item is scored from 0 to 3, with the total score of 5 or more indicating “depression” (Kroenke et al., 2010). A total score of 5–9 indicates ‘mild depression’; 10–14 ‘moderate depression’, 15–19 ‘moderate-to-severe depression’, and ≥20 ‘severe depression’ (Kroenke et al., 2010). The Chinese version of PHQ-9 demonstrated satisfactory psychometric properties (Cronbach's alpha=0.89) (Chen et al., 2015; Leung et al., 2020).
2-2. ابزارها
اطلاعات جمعیتی پایه شامل جنسیت، سن، وضعیت ازدواج، سوابق تحصیلی، تجربه کاری، شیفت کاری، شرایط زندگی، رتبه شغلی، نوع بیمارستان (اولیه/ثالت)، محل کار (با و بدون بیمار)، وضعیت سیگار کشیدن و تجربه کار حین همه گیری بیماری سارس در سال 2003 بود. هم چنین از پرستاران سه سوال استاندارد نیز پرسیده شد: 1) آیا بطور مستقیم با بیماران مبتلا به کرونا سروکار داشتند 2) آیا خانواده، دوستان یا یکی از همکاران آنها به این بیماری مبتلا شده بود و 3) آیا بیماران مبتلا به کرونا در استان محل زندگی/کار آنها 500 مورد به بالا بود یا نه؟
افسردگی توسط نسخه چینی پرسشنامه سلامت بیمار (PHQ) سنجیده شد. این پرسشنامه در واقع یک ابزار خود گزارش 9 موردی است که بطور گسترده در محیط های بیمارستانی استفاده می شود. هر آیتم بین 0 تا 3 رتبه بندی شده است که اگر کسی نمره 5 یا بالاتر را کسب کند یعنی علائم افسردگی را داراست (کرونکه و همکاران 2010). نمره کل 5 تا 9 نشان دهنده افسردگی خفیف، 10 تا 14 افسردگی متوسط، 15 تا 19 افسردگی متوسط رو به حاد و مقادیر بیشتر مساوی 20 نیز نشانگر افسردگی شدید است (کرونکه و همکاران 2010). نسخه چینی PHQ-9 خصوصیات رضایت روانی را نشان می دهد (آلفا گرونباخ = 89/0) (چن و همکاران 2015، لئونگ و همکاران 2020).
توضیحات: این مقاله انگلیسی در سال 2020 در الزویر چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T4761 ترجمه گردیده است.
مقاله بهینه سازی پیکربندی گیرنده لوله ای مرکزی با نصب محیط متخلخل برای افزایش انتقال حرارت
1. Introduction
Solar power tower system (SPTS) is a primal concentrating solar power, which has many obvious advantages including low average cost and large-scale power generation [1]. The receiver is the key component of the SPTS. There are two main kinds of receivers used to SPTS: volumetric receiver and tubular receiver. The tubular receiver can well bear pressure and high temperature, and is applicable to various heat transfer fluid (HTF), such as water/steam, liquid metal, and molten salt.
The solar flux distribution on the receiver is non-uniform resulting from the concentrating mirror optics. The non-uniform solar flux distribution exists not only in the whole receiver, but also in the single tube. The non-uniform heat flux distribution can cause the un-homogeneity of the temperature field in the receiver tube and flow region. The un-homogeneity of the temperature field may result in a lot of problems including the increase of the local heat loss, plastic deformation, and decomposition of HTF [2]. The heat transfer enhancement is one way to solve the above problems due to its ability to decrease the irreversibility of heat convection [3]. Porous material can effectively enhance the heat convection through rebuilding the velocity field and increasing the effective thermal conductivity of fluid; it has been studied as a great deal for possible use in solar receivers. For example, Reddy et al. [4] investigated the heat transfer enhancement of a parabolic trough receiver tube with porous disc numerically.
1. مقدمه
سیستم برج خورشیدی (SPTS)، انرژی اولیه متمرکز خورشیدی است که دارای مزایای بسیار آشکاری از جمله هزینه تقریباً کم و تولید برق در مقیاس وسیع میباشد [1]. گیرنده (receiver)، مؤلفه اصلی سیستم برج خورشیدی است. برای سیستم برج خورشیدی از دو نوع گیرنده اصلی استفاده میشود: گیرنده حجمی و گیرنده لوله¬ای. گیرنده لوله¬ای میتواند فشار و درجه حرارت بالا را کاملاً تحمل کند و برای بسیاری از سیالات هادی حرارت (HTF) مانند آب/ بخار، فلز مایع و نمک مذاب، قابل استفاده است.
توزیع شار خورشیدی بر روی گیرنده بصورت غیریکنواخت است که ناشی از خواص نوری آینه متمرکزکننده میباشد. شار خورشیدی نه تنها در کل گیرنده بصورت غیریکنواخت توزیع میشود بلکه در هر لوله نیز دارای توزیع غیریکنواخت است. توزیع غیریکنواخت شار حرارتی میتواند باعث ناهمگنی(یکسان نبودن) میدان دمایی گیرنده لوله¬ای و فضای جریان شود. ناهمگنی میدان دمایی ممکن است به مشکلات متعددی از جمله افزایش اتلاف گرمای مکانی، تغییر شکل خمیری، و تجزیه سیالات هادی حرارت بیانجامد [2]. افزایش انتقال حرارت، به¬واسطه توانایی آن در کاهش برگشت ناپذیری همرفت گرمایی، یکی از راههایی است که میتواند مشکلات فوق را حل کند [3]. مواد متخلخل میتوانند از طریق بازسازی میدان سرعت (velocity) و افزایش رسانایی حرارتی سیال موجب افزایش کارآمد انتقال گرما شوند؛ این مسئله به جهت استفاده احتمالی آن در گیرندههای خورشیدی مورد مطالعه قرار گرفته است. به عنوان مثال، ردی و همكاران [4] افزایش انتقال گرما درون یک گیرنده لوله¬ای دارای دیسک متخلخل را بصورت عددی در یک سهمی بررسی کردند.
توضیحات: این مقاله انگلیسی در سال 2015 در الزویر چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T1946 ترجمه گردیده است.
مقاله تأثیر لقاح آزمایشگاهی بر اندومتریوز تهاجمی عمیق
Comment
In our experience IVF was a safe procedure for women with deep invasive endometriosis. Only one woman was admitted to the hospital for a condition of hydronephrosis presumably related to deep invasive endometriosis, corresponding to a rate of 1.2% (considering the whole cohort) or 1.7% (considering exclusively women carrying US detectable lesions). This rate is in line with the expected 2% rate of endometriosis progression of over a 3–6- month period in women not receiving IVF and significantly below the threshold of 8% stated as clinically important in our sample size justification (the upper limits of the 95% CIs were <8% for both calculations). The safety of the procedure is also supported by our secondary analyses, i.e. the absence of relevant effects on symptoms and lesions dimension.
The observed case of endometriosis progression deserves some additional comments. Given the regression of the symptoms with expectant management, the interpretation of this case remains unclear. A ureteral stricture caused by the enlargement of an undetecteddeependometrioticnoduleunder thestimulationeffects of enhanced peripheral estrogens seems unlikely. Indeed, even ifitis plausible that adeepnodule ofthebroadligament couldbemissedat baseline evaluation (this diagnosis can be challenging), it is noteworthy that both the US and the computer tomography done at the time of the complication did not detect ureteral nodules. Moreover, symptoms regressed over a couple of weeks concomitantly to the progressive decrease in the size of the ipsilateral ovary. This observation argues against a rapid growth of a nodule, a condition that is likely to be irreversible. In our opinion, the most plausible explanation is a transient kinking of the ureter course consequent to the local traction of the enlarged and adherent ovary that was firmly adherent to the broad ligament. The growth of the ovary could have caused some tractions on a fibrotic area involving the ovary, the broad ligament and the ureter, actually pulling the ureter and causing a temporary narrowing of the lumen.
تفسیر
با توجه به چیزی که به تجربه دریافته ایم، آی.وی.اف روشی ایمن برای زنان مبتلا به اندومتریوز تهاجمی عمیق به شمار میرفت. تنها یکی از زنان به خاطر ابتلا به بیماری هیدرونفروز (ورم کلیه) که احتمالا ً ناشی از اندومتریوز تهاجمی عمیق بود، در بیمارستان بستری شد و این مورد با میزان 2/1 درصد (با در نظر گرفتن کل گروه) یا 7/1 درصد (با در نظر گرفتن صرفاً زنان حامل ضایعات قابلشناسایی با سونوگرافی) برابری میکرد. این میزان در راستای میزان 2 درصد پیش بینی شده وخامت اندومتریوز طی یک دوره 3 تا 6 ماه در زنانی که آی.وی.اف دریافت نکردهاند، قرار دارد و بسیار پایین تر از آستانه 8 درصد است که در توجیه اندازه نمونه ما به لحاظ بالینی مهم تلقی شده است (حدود بالای 95 درصد CI ها در هر دو محاسبه کمتر از 8 درصد بودند). ایمنی این روش یعنی نبود تأثیرات مرتبط بر علائم بیماری و ابعاد ضایعات نیز تحت حمایت تجزیه و تحلیل های ثانویه ما قرار گرفته است.
مورد مشاهده شده وخامت اندومتریوز نیازمند ارائه توضیحات بیشتری است. تفسیر این مورد با توجه به فروکش کردن علائم از طریق مدیریت مورد انتظار، مشخص نیست. تنگی میزنای به علت بزرگ شدن گرهک های اندومتریوز عمیق ناشناخته تحت اثرات تحریک استروژنهای محیطی تقویت شده بعید به نظر میرسد. در واقع، حتی اگر این امر قابل قبول باشد که گرهک عمیقی از رباط بزرگ ممکن بود در ارزیابی خط پایه از دست برود (این تشخیص میتواند چالش برانگیز باشد)، قابل توجه است که هم سونوگرافی و هم توموگرافی کامپیوتری انجام شده در زمان عارضه، گرهکهای میزنای را تشخیص ندادند. علاوه بر این، علائم طی چند هفته همراه با کاهش تدریجی به اندازه تخمدان همان سمت بدن فروکش کردند. این مشاهده در مقابل رشد سریع یک گرهک مطرح می شود؛ وضعیتی که ممکن است قابل بازگشت نباشد. به نظر ما، معقولترین توجیه، پیچ خوردگی موقتی مسیر میزنای در نتیجه کشش موضعی تخمدان متورم و چسبیده است که به رباط بزرگ محکم چسبیده بود. رشد تخمدان احتمالاً کشش هایی در یک ناحیه مبتلا به فیبروز شامل تخمدان، رباط های بزرگ و میزنای ایجاد کرده است و در واقع با کشیدن میزنای باعث تنگ شدن موقت لومن شده است.
توضیحات: این مقاله انگلیسی در سال 2019 در الزویر (Elsevier) چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T3791 ترجمه گردیده است.
مقاله معماری اینترنت اشیا برای سیستم هوشمند کمکهای اولیه رباتیک در خودروهای سواری
3. IoT Requirements for Robotic First Aid System
Consequent to the literature above, the following requirements have been identified in line with a precursor study on RFA functions [57]. Inclusion or exclusion of some entities will impact the space required by the robot and its weight.
3.1. Navigation and Mapping
The RFA system should be equipped with sensors that allow it to simultaneously localize, map an unknown environment and navigate its work envelop, with no human intervention.
3.2. Human Detection, Tracking and Triag
An unpredictable environment such as that of the vehicle interior following an RTA calls for a sensor system that can distinguish human beings from the other objects. Furthermore, it should be able to identify human body parts and deploy its various first aid tools accordingly. With further development, the system should have the ability to assign degrees of urgency to illness or wounds to decide the order of treatment of the vehicle occupants.
3. الزامات اینترنت اشیا برای سیستم کمکهای اولیه رباتیک
به تبع متون فوق، الزامات ذیل مطابق با مطالعه پیشرو درباره کارکردهای سیستم کمکهای اولیه رباتیک شناسایی شدهاند [57]. شمول یا حذف برخی چیزها بر فضای موردنیاز ربات و وزن آن تاثیر خواهد گذاشت.
3.1. راهبری و نگاشت
سیستم کمکهای اولیه رباتیک باید مجهز به حسگرهایی باشد که امکان موقعیت یابی همزمان، نگاشت محیط ناشناخته و راهبری دامنه حرکتی اش را بدون مداخله انسانی فراهم سازد.
3.2. شناسایی انسان، ردیابی و اولویت بندی بیماران
یک محیط غیرقابل پیشبینی مانند محیط داخل وسیله نقلیه پس از سیستم کمکهای اولیه رباتیک مستلزم نوعی سیستم حسگر است که بتواند انسانها را از سایر اشیا متمایز سازد. علاوه بر این، سیستم حسگر موردنظر باید قادر باشد بخشهای بدن انسان را شناسایی کرده و ابزارهای کمکهای اولیه مختلف خود را مطابق آن به کار بگیرد. با توسعه بیشتر، این سیستم باید بتواند درجه ضرورت بیماری یا جراحات را مشخص کند تا درباره ترتیب درمان سرنشینان خودرو تصمیم گیری نماید.
توضیحات: این مقاله انگلیسی در سال 2019 در الزویر (Elsevier) چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T3791 ترجمه گردیده است.
مقاله بازاریابی ویروسی در شبکههای اجتماعی: چشماندازی اپیدمیولوژیک
4. Numerical Results
Simulations for both the approaches, mean-field analysis and network analysis have been carried out on MATLAB. To understand the effect of population heterogeneity and network topology, random, scale-free and real social networks have been considered in our simulations.
4.1. Simulation of the Deterministic Model
As discussed in Sec. 2.4, system may lead to any one of three possible steady state situations: when only messagefree state exists; when only an endemic state exists; when an endemic as well as a message-free state can exist depending on initial population of different classes. We have shown both the cases where at least one of the steady state is endemic, in Fig. 3(a)-(b) with their respective parameter values.
4.2. Simulation over Model Networks
Same set of parameters have been used to compare the results of deterministic mean-field model with network model. We have carried out our simulation over random network and scale-free network having 1024 nodes and average degree 10. Random network has been created by Erdos-R ¨ enyi model and follows binomial degree distribution ´ which converges to Poisson distribution for very large number of nodes (infinite network). Scale-free network has been generated by Barabasi-Albert preferential attachment model [29] and follows power law degree distribution having ´ power exponent 3.
n case of random network, we obtained similar results as predicted by deterministic model. Using the values of bistable steady state configuration of Fig. 3(b), we similarly observed two stable states in Fig. 3(c), one endemic and one message-free. Steady state value obtained by the simulation is also in agreement with the mean-field approach.
4. نتایج عددی
شبیهسازیهای برای هر دو رویکرد، تجزیه و تحلیل میدان-میانگین و تجزیه و تحلیل شبکه با استفاده از نرمافزار متلب انجام شدهاند. برای شناخت تاثیر ناهمگنی جمعیت و توپولوژی شبکه، شبکههای اجتماعی واقعی، تصادفی و مقیاس-آزاد در شبیهسازیهای ما در نظر گرفته شدهاند.
4.1. شبیهسازی مدل قطعی
همانطور که در بخش ۲.۴ بخث شد، سیستم ممکن است به هیچ کدام از سه وضعیت ممکن حالت پایدار نرسد: هنگامی که تنها حالت بدون پیام وجود دارد؛ هنگامی که تنها یک حالت اندمیک وجود دارد؛ هنگامی که یک حالت اندمیک و همچنین یک حالت بدون پیام میتوانند بسته به جمعیت اولیه ردههای مختلف وجود داشته باشند. ما هر دو حالت را که در آنها حداقل یکی از حالتهای پایدار اندمیک است در شکل ۳آ-ب با مقادیر پارامتر مربوطه آنها نشان دادهایم.
4.2. شبیهسازی روی شبکههای مدل
مجموعه یکسانی از پارامترها برای مقایسه نتایج مدل میدان-میانگین قطعی با مدل شبکه مورد استفاده قرار گرفتهاند. ما شبیهسازی خود رو روی شبکه تصادفی و شبکه مقیاس-آزاد با ۱۰۲۴ گره و متوسط درجه ۱۰ انجام دادیم. شبکه تصادفی توسط مدل اردوس-رینی ایجاد شده است و از توزیع درجه دو جملهای پیروی میکند که به توزیع پواسون برای تعداد بسیار زیادی از گرهها (شبکه نامتناهی) همگرا است. شبکه مقیاس-آزاد توسط مدل اتصال باراباسی-آلبرت [۲۹] تولید شده است و از توزیع درجه قانون توان با نمای توان ۳ پیروی میکند.
در مورد شبکه تصادفی، نتایج یکسان با نتایج پیشبینی شده توسط مدل قطعی را به دست آوردیم. با استفاده از مقادیر پیکردبندی حالت پایدار دوپایا در شکل ۳ب، به طور مشابهی دو حالت پایدار را در شکل ۳سی مشاهده کردیم، یک مقدار حالت پایدار اندمیک و یک مقدار حالت پایدار بدون پیام به دست آمده توسط شبیهسازی نیز سازگار با رویکرد میدان-میانگین است.
توضیحات: این مقاله انگلیسی در سال 2019 در الزویر (Elsevier) چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T1700 ترجمه گردیده است.
مقاله مواد دوستدار محیط زیست برای مفهوم جدید روسازی آسفالت
3. Eco-friendly concept of asphalt pavement
Considering the full pavement structure, the proposed concept of eco-friendly asphalt pavement can be summarized as follows:
- in surface course is the introduction of green bitumen modifier, derived from recovered waste bioethanol production as an alternative to the traditional additives used for bitumen production,
- in binder and base course, bio-fluxing agents allow for the integration of higher percentage of reclaimed asphalt,
- the lower layers (sub-base and subgrade) are mainly composed of materials derived from construction and demolition waste.
3.1. Applications of Construction and Demolition Waste in road construction
C&DW material composition and characterization according to EN 933-11 shows that, in order to obtain high grade recycled aggregates applicable in building products applications, there is a need to sort out a number of contaminant components such as calorific fractions, gypsum and the non-concrete stony fraction
In the actual market there is no complete advanced recycling concept available from input of raw (stony) C&DW to the dispatch of pure high-grade recycled concrete aggregates. Therefore an advanced processing concept was developed under the name “Stone Recycling”. This concept is a flexible solution to rather complex questions on how to obtain pure aggregates from raw C&DW. The Stone Recycling concept is conceived in two major parts, which can be operated separately, or in one line depending on the required outcome and product quality. In order to obtain high-grade recycled aggregates the complete processing concept is needed.
3. مفهوم دوستدار محیط بودن روسازی آسفالت
با در نظر گرفتن ساختار نهایی جاده ها، مفهوم معرفی شده روسازی آسفالت دوستدار محیط زیست به شکل زیر خلاصه می شوند:
- در مقاطع سطحی که مقدمه ای بر معرفی مواد اصلاح شده قیر سبز است و این قیر جدید از تولید بیو اتانول حاصل از ضایعات به عنوان جایگزینی برای مواد افزودنی قدیمی مورد استفاده برای اصلاح پلیمری بدست می آید
- در مواد الیافی و پایه، مواد زیستی امکان ترکیب درصد بیشتری از آسفالت اصلاح شده را فراهم می آورند، - لایه های پایین تر (زیر لایه ها و لایه های سطح پایین تر) عمدتا متشکل از مواد بدست آمده از ضایعات ساختمانی و تخریبی می باشند
3.1. استفاده از ضایعات ساختمانی و تخریبی در ساخت جاده
ساختار مواد C&DW و ویژگیهای بیان شده با توجه به EN 933-11 نشان می دهد که برای بدست آوردن خرده سنگ های بازیافتی مرغوب قابل استفاده در مواد ساختمانی، باید تعدادی از مواد از جمله مواد رنگی، سنگ کچ و مواد سنگی غیر ساختمانی دسته بندی شوند.
در بازار واقعی، مفهوم مناسبی برای بازیافت پیشرفته و کامل از مواد خام (سنگی) C&DW برای استفاده از مواد بتنی بازیافتی شده وجود ندارد، بنابراین، یک مفهوم پیشرفته با نام " بازیافت سنگ" معرفی شد. این مفهوم یک راه حل انعطاف پذیر برای سوالات نسبتا پیچیده در مورد چگونگی داشتن مواد متراکم از C&DW خام می باشد. مفهوم بازیافت سنگ در دو بخش اصلی برداشت می شود که می توانند با توجه به نتایج و کیفیت محصول مورد نظر به صورت مجزا یا در یک خط مورد استفاده قرار بگیرند. برای داشتن مواد متراکم با کیفیت، مفهوم پردازش کامل مورد نیاز است.
توضیحات: این مقاله انگلیسی در سال 2016 در الزویر (Elsevier) چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T1714 ترجمه گردیده است.
مقاله عوامل موثر بر روی ریسک خستگی خلبانان خطوط هوایی
2.2. Fatigue types
2.2.1. Physical fatigue
Fatigue is generally classified as either physical or mental. Sufficient rest is the only remedy for fatigue (Dinges et al., 1996) and an insufficient rest period does not enable a fatigued individual to recover from that fatigue (Dawson and McCulloch, 2005). From the viewpoint of airline pilots, fatigue is related to crew schedules and rest periods. Physical fatigue is caused by more than just one muscle being unable to perform. During physical activity, the onset of muscle fatigue is gradual and depends upon an individual's level of physical fitness, and other factors, including sleep deprivation and overall level of healthiness. Proper rest can reverse this process. A lack of energy in the muscles causes the physical fatigue by reducing the drive originating from the central nervous system or by decreasing the efficiency of the neuromuscular junction (Wesensten et al., 2004).
2.2.2. Mental fatigue
Mental fatigue is a psychobiological state caused by prolonged periods of demanding cognitive activity and characterized by subjective feelings of tiredness and lack of energy (Marcora et al., 2008). It is measured as a reduction in the ability to perform mental tasks. Sleep disruptions, which may induce mental fatigue, decrease cognitive functioning and psychomotor vigilance task (PVT) performance. It is remarkably difficult to understand mental fatigue and the cognitive processes underlying its behavioral manifestations (Curnow, 2002).
Mental fatigue is also defined as a temporary inability to maintain optimal cognitive performance. During any cognitive activity, the symptom of mental fatigue is gradual and depends on an individual's cognitive ability, and also upon other factors, including sleep deprivation and overall health.
2.2 انواع خستگی
2.2.1 خستگی فیزیکی
خستگی به صورت عمومی به عنوان یک حالت فیزیکی و یا روانی توصیف می شود. استراحت کافی تنها درمان برای خستگی می باشد (Dinges et al., 1996) و استراحت کم باعث نمی شود که افراد خسته بتوانند خستگی خودشان را رفع کنند (Dawson and McCulloch, 2005). از نقطه نظر مرتبط با خلبان ها، خستگی مرتبط با زمان بندی خدمه و دوره های استراحت می باشد. خستگی فیزیکی به این خاطر ایجاد می شود که بیش از یک عضله نمی توانند عملکرد خوب خودش ار ارائه کنند. در طول فعالیت های فیزیکی، شروع خستگی عضلانی به صورت تدریجی ایجاد می شود و مبتنی بر سطح آمادگی فیزیکی فرد، و عوامل دیگر شکل می گیرد که این عوامل شامل محروم شدن از خواب و سطح کلی سلامتی فرد می باشد. استراحت کافی می تواند این فرآیند را معکوس کند یعنی خستگی فرد رفع شود. کمبود انرژی در عضلات باعث می شود که خستگی فیزیکی ایجاد شود زیرا عضلات انرژی کافی را از سیستم عصبی مرکزی دریافت نمی کنند و کارایی ارتباطات عصبی عضلانی نیز کاهش پیدا می کند (Wesensten et al., 2004).
2.2.2 خستگی ذهنی
خستگی ذهنی یک حالت روانی فیزیویوژیکی می باشد که در اثر دوره های طولانی از فعالیت های دشوار و بر اساس احساسات ذهنی خستگی و کمبود انرژی، توصیف می شود (Marcora et al., 2008). این حالت خستگی به صورت کاهش در توانایی انجام وظایف ذهنی اندازه گیری می شود. کاهش خواب که می تواند باعث خستگی ذهنی شود، باعث می شود که عملکرد ادراکی و وظایف حرکات ظریف (PVT) دچار مشکل شود. به سختی می توان خستگی ذهنی یک فرد و فرایند های ادراکی زیر لایه ای مرتبط با عدم عملکرد مناسب رفتاری را درک کرد (Curnow, 2002).
خستگی ذهنی همچنین به صورت عدم توانایی موقتی برای حفظ عملکرد ادراکی بهینه نیز توصیف می شود. در طول هر کدام از فعالیت های ادراکی، نشانه های خستگی ذهنی به صورت تدریجی ایجاد می شود و مبتنی بر توانایی های ادراکی فرد و عوامل دیگر می باشد مانند کاهش خواب و سلامت کلی فرد.
توضیحات: این مقاله انگلیسی در سال 2018 در نشریه الزویر (Elsevier) چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T1702 ترجمه گردیده است.
مقاله تکنیک های بهینه تزریق ولتاژ برای حفاظت از بارهای حساس
3. Strategies of voltage sag compensation
Fig. 3 is a schematic representation of the power grid supplying a load that is protected by a DVR. It is depicted in this figure, the complex power flowing through the whole system. The voltage Udvr can be generated by the DVR in three modes which are illustrated in Fig. 4. In the first mode, the applied voltage on the load has the same phase-angle of the pre-dipped grid voltage. This case has the advantage to avoid phase-jumps which can be destructive to sensitive loads. The second operation mode occurs when the voltage correction is performed by applying voltage synchronously during the voltage sag. This scheme requires lower levels of voltages and it is very interesting when the DClink voltage is limited to two levels.
The third operation mode allows the voltage application under a minimum active power value demanded from the controller. This mode can be useful when the DC-link is supplied by accumulators and it can prolong its life-cycle. The third mode for compensating voltage is the main focus of this work. The development of the equation to produce the control reference assuring the minimization of injected active power is as follows. Initially, the equations for active power supplied by the grid and consumed by the load are presented by
3. استراتژی های جبران سازی افت ولتاژ
شکل 3 نمایش شماتیکی از تغذیه باری که توسط یک DVR حفاظت شده، در این شکل، پخش بار مختلط در کل سیستم نشان داده شده است. ولتاژ Udvr می تواند در سه حالتی که در شکل 4 نشان داده شده است، توسط DVR تولید شود. در حالت اول، زاویه فاز ولتاژ اعمال شده بر بار و ولتاژ قبل از افت شبکه، برابر است. مزیت این حالت در این است که جهش های فازی که می توانند برای بارهای حساس خطرناک باشند، اتفاق نمی افتد. عملکرد دوم زمانی اتفاق می افتد که تصحیح ولتاژ توسط اعمال سنکرون ولتاژ در حین افت صورت پذیرد. این طرح به سطوح پایین تری از ولتاژ نیاز دارد و برای زمانی که ولتاژ لینک DC به دو سطح محدود می شود، بسیار جالب است.
عملکرد سوم اعمال ولتاژ پایین تر از مقدار کمینه توان اکتیو مورد نیاز کنترل کننده را مقدور می سازد. این حالت برای زمانی که لینک DC توسط انباره ها تامین می شود، مفید است و طول عمر آن را افزایش می دهد. حالت سوم ولتاژ جبران ساز هدف اصلی این پروژه است. به دست آوردن رابطه ای برای ایجاد مرجع کنترلی که کمینه توان اکتیو تزریقی را تضمین می کند، به صورت زیر است. ابتدا، معادله توان اکتیو تولید شده توسط شبکه و مصرف شده توسط بار به این صورت بیان می شود
توضیحات: این مقاله انگلیسی در سال 2020 در نشریه الزویر (Elsevier) چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T3540 ترجمه گردیده است.
مقاله طبقه بندی شبکه عصبی سیگنال های نوار مغزی برای تشخیص حمله ناگهانی
IV. IMPLIMENTATION
In proposed work data set used with different sampling rate; one with 128Hz and another data set has a sampling rate of 1024Hz. After removal of noise the data was segmented. Feature extraction was done using DWT and statistical features were calculated. Finally data will be given to classifier for classification. Simulation environment used in this paper is MATLAB 2015a.
A. Feature Extraction using DWT
Fast Fourier Transform (FFT) is a strong tool for data analysis. However, it does not represent abrupt changes efficiently. And since EEG is a non-stationary signal it is advantageous to use time-frequency domain technique such as DWT. In simple term wavelets are rapidly decaying waves like oscillation that has zero mean. Scaling and shifting are the two key features of wavelets. Wavelet works on multi-scale basis. This feature of WT allows the decomposition of signal into several scales [3].
DWT can represent a natural signal with fewer coefficients. Key application of DWT is denoising and compression of image and signal. A given signal will pass through two filters. The first filter h[n] is the low pass (discrete mother wavelet) and the second filter g[n] is the high pass (mirror version). The data will be down sampled to get low pass and high pass filter coefficient, i.e approximation (A) and detail coefficient (D) respectively. Approximation coefficient is again decomposed and the procedure will repeat.
4. پیاده سازی
دیتاست در کار پیشنهادی همراه با نرخ های نمونه برداری مختلفی مورد استفاده قرار گرفته است؛ یک دیتاست با فرکانس 128 هرتز و دیتاست دیگری با نرخ نمونه برداری 1024 هرتز به کار گرفته شده است. پس از حذف نویز، داده ها تفکیک می شود. استخراج ویژگی با استفاده از تبدیل DWT انجام شده است و ویژگی های آماری نیز محاسبه شده است. در نهایت داده ها به منظور دسته بندی به طبقه بندی کننده ارائه می شود. محیط شبیه سازی مورد استفاده در این مقاله نرم افزار MATLAN نسخه 2015a است.
A. استخراج ویژگی با استفاده از تبدیل DWT
تبدیل فوریه سریع (FFT) ابزار قدرتمندی برای تحلیل داده ها است. با این حال، تغییرات ناگهانی را به طور موثر نشان نمی دهد. از آنجایی که نوار مغزی یک سیگنال غیر ساکن است، استفاده از تکنیک حوزه زمان- فرکانس همانند DWT سودمند است. به عبارت ساده تر، موجک ها در واقع موج هایی هستند که به سرعت افت می کنند که شبیه نوسانی است که دارای میانگین صفر است. مقیاس دهی و شیفت دهی دو ویژگی اصلی موجک ها هستند. موجک بر مبنای چند مقیاسی کار می کند. این ویژگی به تبدیل DWT اجازه می دهد تا سیگنال را در چند مقیاس تجزیه کند [3].
تبدیل DWT می تواند یک سیگنال طبیعی را با ضرایب کمتری نشان دهد. کاربرد اصلی DWT نویز زدایی و فشرده کردن تصویر و سیگنال است. یک سیگنال داده شده از دو فیلتر عبور می کند. فیلتر اول یعن h[n] یک فیلتر پایین گذر (موجک گسسته مادر) و فلیتر دوم g[n] یک فیلتر بالاگذر (نسخه آینه) است. داده ها برای دستیابی به ضرایب فیلتر پایین گذر و بالاگذر یعنی به ترتیب تقریب (A) . ضریب جزئیات (D) دچار کاهش نمونه ها می شود. مجدداً ضریب تقریب تجزیه شده و این روند ادامه می یابد.
توضیحات: این مقاله انگلیسی در سال 2017 در نشریه ای تریپل ای (IEEE) چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T1723 ترجمه گردیده است.
مقاله نشانگرهای زیستی حالت ردوکس تومور در پاسخ به تلفیق مسیرهای آنتی اکسیدانی گلوتاتیون و تیوردوکسین
Materials and methods
Cell Lines
Human mammary adenocarcinoma (MDA‐MB‐231) and Human cervix squamous cell carcinoma (SiHa) cells (American Type Culture Collection [ATCC]) were grown in Dulbecco’s modified Eagle’s medium (DMEM, Invitrogen, Belgium) with GlutaMAX tm, D‐Glucose 1g/L and sodium pyruvate supplemented with 10 % fetal bovine serum (Invitrogen, Belgium) and 1% (v/v) penicillin‐streptomycin (Invitrogen, Belgium).
In vivo xenografts
Animal studies were undertaken in accordance with Belgian and Université catholique de Louvain ethical committee regulations (agreements number UCL/2010/ MD/001 and UCL/2014/MD/026).
A total of 10^7 MDA‐MB‐231 cells or 107 SiHa cells, amplified in vitro, were collected by trypsinization, washed three times with Hanks balanced salt solution and resuspended in 100 μL of Hanks balanced salt solution. Cells were then implanted by intramuscular injection in the rear legs of NMRI nude mice. After inoculation, tumors were allowed to grow up to 7 mm +/‐ 1 mm in diameter prior to experimentation. Mice were anesthetized by isoflurane inhalation (Forene, Abbot, England) mixed with air in a continuous flow (2 L/min). Physiological temperature was maintained using a warm water blanket connected to a circulating water bath.
Chemicals
The nitroxide probes, mito‐tempo and tempol were purchased from Sigma Aldrich (Diegem, Belgium). Solutions of the nitroxide were prepared at a stock concentration of 300 mM in saline and were then stored at ‐20°C before use. For in vitro experiments, nitroxide was used as a probe at a final concentration of 100 µM added just before recording of EPR spectrum. For in vivo experiments, nitroxide was used as a probe at a concentration of 6mM, mice were given one dose via intratumoral injection with a saline solution of nitroxide and EPR spectra were acquired directly after the injection.
مواد و روش ها
لاین های سلولی
آدنوکارسینومای انسانی(MDA‐MB‐231) و کارسینومای سلول سنگفرشی گردن (SiHa) (محیط کشت نوع آمریکایی {ATCC}) در محیط کشت اصلاح شده ی دالبکو ایگلز (اینویتروژن، بلژیک) به همراه گلوتامکسtm، دی-گلوکز 1گرم بر لیتر و سدیم پیرووات با 10% سرم فتال گاوی(اینویتروژن/بلژیک) و 1% (v/v) پنی سیلین-استرپتومایسین(اینویتروژن-بلژیک).
زنوگرافت در شرایط in vivo
مطالعات جانوری مطابق با قوانین کمیته ی اخلاقی بلژیک و دانشگاه کاتولیک دی لوویان انجام گرفت(شماره موافقت نامه 001/MD/2010/UCL و 026/MD/2014/UCL).
در کل 7^10 سلول 231-MB-MDA یا 107سلول SiHa در شرایط آزمایشگاه تکثیر شدند. که بوسیله ی تریپیسینیزاسیون جمع آوری شدند، سه بار با محلول نمکی متعادل کننده ی هانکس شستشو داده شدند و مجدد در 100میکرولیتر محلول نمکی متعادل کننده ی هانکس غوطه ور شدند. سلول ها بوسیله ی تزریق داخل عضلانی پاهای عقبی موش های برهنه ی NMRI کشت شدند. پس از تزریق، پیش از آزمایش به تومورها اجازه داده شد تا قطر 7میلی متر و با 1میلیمتر خطا رشد کنند. موش ها بوسیله ی استنشاق ایزوفلوران(فورن، آبوت، انگلیس) مخلوط شده در جریان هوای مداوم به میزان 2لیتر در دقیقه بیهوش شدند. دمای فیزیولوژیک با استفاده از روکش آب گرم متصل به تهویه ی حمام آب گرم تعدیل می شد.
شیمیایی
پروب های نیتروکساید، mito-tempo و tempol از شرکت سیگما آلدریچ (دیجم-بلژیک) خریداری شد. محلول های نیتروکساید در غلظت های 300میکرو مولار در نمک تهیه و سپس تا قبل از استفاده در دمای 20-درجه سانتی گراد نگهداری شدند. برای آزمایش در محیط آزمایشگاه، نیتروکساید به عنوان یک پروب در غلظت نهایی100 میکرو مولار قبل از ثبت طیف EPR تهیه گردید. برای شرایط in vivo نیتروکساید به عنوان پروب در غلظت 6میکرومولار استفاده شد. موش ها یک دوز را بوسیله ی تزریق داخل عضلانی با محلول نمکی نیتروکساید دریافت کردند و پس از تزریق سنجش طیف EPR انجام گرفت.
توضیحات: این مقاله انگلیسی در سال 2018 در نشریه تیلور و فرانسیس (Taylor and Francis) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T2638 ترجمه گردیده است.
مقاله آزمایشات خزش – بازیابی – خزش برای تعیین فشار نهایی ژل های سیال دارای ژلاتین و یون +Na
4. Conclusions
We have demonstrated that 3.5 Pa was the highest shear stress which yielded “creep flow” (very slow flow dominated by elastic response) during a creep-recovery-creep test carried out for a fluid gel containing 0.2 wt% gellan gum and 0.22 M Na+ as gel-promoting ion. This was consistent with the response of a solid-like material under creep flow. A slight increase in shear stress up to 3.7 Pa provoked a dramatic change in the rheological response of the fluid gel studied since clear fluid-like behaviour was observed. Therefore, we assigned a value of 3.6 Pa for an apparent, or better, practical yield stress. Above the practical yield stress value, a shear rate close to the steady state value was quickly reached, the elastic recovery was negligible and the viscosity versus time curve illustrated the occurrence of thixotropy with an incomplete recuperation of the initial viscosity after 40 s of recovery. The instability of the viscosity versus time curves after the first creep test at 3.7 Pa was ascribed to the proximity to the yield stress of these fluid gels. Between 4.0 and 6.0 Pa, the response became more stable, but similar to that found at 3.7 Pa. Additionally,the shear rate dependence of viscosity derived from independent creep-recovery-creep tests illustrated a very shear thinning behaviour, with a power law index of 0.3.
The results obtained support the conclusion that the presented creep-recovery-creep test is a good method to determine both the practical yield stress and the inception of non-linear timedependent rheological behaviour of very shear thinning structured materials, such as low-acyl gellan gum fluid gels.
4. نتیجه گیری
ما در این تحقیق بیان کردیم که فشار 3.5 پاسکال بالاترین فشار کششی است که جریان خزش را ایجاد می کند ( جریان خزش جریان بسیار آرامی است که از واکنش ارتجاعی در مدت زمان انجام آزمایش خزش برای ژل سیال دارای 0.2% wt صمغ ژلاتین و 0.22M یون Na+ ایجاد می شود. این مطلب متناسب با واکنش های مواد سیال تحت جریان کشش است. افزایش جزئی در فشار کششی تا 3.7pa باعث ایجاد تغییر در واکنش های ژل مایع مورد بررسی است زیرا رفتار سیال مشاهده می شود. بنابراین، نسیت کشش نزدیک به حالت ثابت به سرعت حاصل می شود و بازیابی ارتجاعی قابل چشم پوشی است و نمودار ویسکوزیته در برابر زمان نشان دهنده همگونی همراه با شکل گیری ناقص ویسکوزیته اولیه بعد از 40 ثانیه از بازیابی است. بی ثباتی در منحنی های ویسکوزیته در مقابل زمان بعد از خزش اول در 3.7pa به مقدار فشار بازده ژل های سیال نزدیک است. در فشار بین 4 و 6 پاسکال، واکنشها پایدار تر می شوند، اما این واکنش ها به واکنش در 3.7 پاسکال شبیه هستند. به علاوه، وابستگی نسیت فشار به ویسکوزیته به دست آمده از آزمایش های خزش – بازیابی و خزش بیانگر رفتار نازک شدن با شاخص قانون قدرت 0.3 می باشد.
نتایج به دست آمده تایید کننده این نتیجه گیری است که آزمایش انجام شده روش خوبی برای تعیین فشار نهایی و رفتار غیر خطی وابسته به زمان ساختارهای نازک مثل ژل های سیال ژلاتینی است.
توضیحات: این مقاله انگلیسی در سال 2016 در نشریه الزویر (Elsevier) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T1714 ترجمه گردیده است.
مقاله هوش مصنوعی در قلب و عروق
How do artificail intelligence and machine learning relate to statistics ?
Physicians have long needed to identify, quantify, and interpret relationships among variables to improve patient care. AI and machine learning comprise a variety of methods that allow computers to do just this, by algorithmically learning efficient representations of data. Here, we use the terms “artificial intelligence” and “machine learning” more or less synonymously, although more precisely machine learning can be understood as a set of techniques to enable AI. The difference between classical machine learning and classical statistics is less one of methodology than one of intent and culture. The primary focus of statistics is to conduct inference about sample or population parameters, whereas machine learning focuses on algorithmically representing data structure and making predictions or classifications. These 2 ambitions are often intertwined. Thus, we do not place a definite boundary between classical statistics and machine learning methods and instead view them as analogous but often applied to answer different questions.
Why does cardiology need artficial intelligence ?
AI emerged because more familiar algorithms can often be improved on for real-world tasks. Consider the case of logistic regression. To enable statistical inference such as estimation of coefficients and p values, this model requires a number of strong assumptions (e.g., independence of observations and no multicollinearity among variables). When logistic regression is used for other purposes, the assumptions that enable statistical inference may be unrelated to the goal and can hinder the model’s performance. In contrast, machine learning algorithms are typically used without making as many assumptions of the underlying data. Although this approach hinders the possibility for traditional statistical inference, it results in algorithms that generally are more accurate for prediction and classification. Thus, cardiovascular medicine can benefit from the incorporation of AI and machine learning.
هوش مصنوعی و یادگیری ماشینی چه ارتباطی با آمار دارند؟
متخصص ها از مدت ها مجبور بوده که روابط بین متغیر های مختلف را شناسایی ، کمی سازی و تفسیر کنند تا بتوانند خدمات درمانی به بیماران را بهبود بخشند. AI و یادگیری ماشینی ، روش های مختلف را ایجاد می کنند که به کامپیوتر ها این امکان را می دهد تا این کارها را با استفاده از روش های موثر یادگیری الگوریتمی و با استفاده از داده ها، نشان دهند. در این قسمت، ما از عبارت هوش مصنوعی و یادگیری ماشینی استفاده می کنیم که تقریبا یک معنی دارند اما در حقیقت، یادگیری ماشین به صورت دقیق مجموعه ای از تکنیک هایی هستند که باعث می شوند ما بتوانیم از AI استفاده کنیم. تفاوت های بین یادگیری کلاسیک ماشینی و روش های آماری کلاسیک بیشتر شبیه یک روش می باشد نه یک مفهوم و فرهنگ علمی. تمرکز اصلی آمار اجرا کردن اسنتاج در رابطه با نمونه ها و یا پارامتر های جمعیتی می باشد در حالی که یادگیری ماشینی متمرکز بر روی نمایه الگوریتمی داده ها و پیش بینی کردن و یا دسته بندی کردن می باشد. ازین رو، ما مرز خاصی بین آمار کلاسیک و یادگیری ماشینی قائل نمی شویم و به جای آن، ما به صورت مشابه از این عبارات استفاده می کنیم اما گاهی برای پاسخ دادن به سوالات مختلف مورد استفاده قرار می گیرد.
چرا علم قلب شناسی باید از هوش مصنوعی استفاده کند؟
AI به این دلیل ظهور کرده است که الگوریتم های آشنا را می توان برای وظایف دنیای واقعی، بهبود داد. مثلا مورد رگرسیون لجستیک را در نظر بگیرید. برای این که بتوانیم قابلیت استنتاج های آماری مانند تخمین ضرایب و مقادیر P را ایجاد کنیم، این مدل نیازمند فرضیاتی قوی می باشد ( مثلا، استقلال از ناظر و عدم همبستگی بین متغیر های مختلف). زمانی که رگرسیون لجستیک برای اهداف دیگر مورد استفاده قرار می گیرد، این فرضیات که باعث می شود بتوانیم استنتاج آماری را انجام دهیم، گاهی باعث می شود که ما از هدف خودمان دور شویم و باعث می شود که عملکرد مدل را کاهش می دهد. در مقابل، الگوریتم های یادگیری ماشینی معمولا بدون فرضیات مرتبط با داده های زیرلایه های مورد استفاده قرار می گیرد. با وجود این که این روش باعث کاهش احتمال استنتاج های متداول می شود، اما باعث شکل گیری الگوریتمی می شود که معمولا برای پیش بینی و دسته بندی دقت بالاتری دارد. ازین رو پزشکی قلب و عروق می تواند از کاربرد های هوش مصنوعی و یادگیری ماشینی، بهره ببرد.
توضیحات: این مقاله انگلیسی در سال 2018 در نشریه الزویر (Elsevier) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T1702 ترجمه گردیده است.
مقاله بهبود تجزیه و تحلیل یادگیری عمیق احساسات با روش های کلی در کاربردهای اجتماعی
7. Conclusions and future work
This paper proposes several models where classic hand-crafted features are combined with automatically extracted embedding features, as well as the ensemble of analyzers that learn from these varied features. In order to classify these different approaches, we propose a taxonomy of ensembles of classifiers and features that is based on two dimensions. Furthermore, with the aim of evaluating the proposed models, a deep learning baseline is defined, and the classification performances of several ensembles are compared to the performance of the baseline. With the intention of conducting a comparative experimental study, six public datasets are used for the evaluation of all the models, as well as six public sentiment classifiers. Finally, we conduct an statistical analysis in order to empirically verify that combining information from varied features and/or analyzers is an adequate way to surpass the sentiment classification performance.
The second question was whether the sentiment analysis performance of a deep classifier can be leveraged when using the proposed ensemble of classifiers and features models. Observing the scores table and the Friedman ranks (Table 5), we see that the proposed models generally improve the performance of the baseline. This indicates that the combination of information from diverse sources such as surface features, generic and affect word vectors effectively improves the classifier’s results in sentiment analysis tasks.
There were three main research questions that drove this work. The first question was whether there is a framework to characterize existing approaches in relation to the ensemble of traditional and deep techniques in sentiment analysis. To the best of our knowledge, our proposal of a taxonomy and the resulting implementations is the first work to tackle this problem for sentiment analysis.
7 .نتیجه گیری ها و تحقیقات آینده
این تحقیق چندین مدل ارائه کرده است که در آنها ویژگی های دستی با ویژگی های استخراج شده اتوماتیک و همچنین مجموعه ای از تحلیل گرهای حاصل از ویژگی های مختلف ترکیب شده اند.برای دسته بندی این روش های مختلف، لیست واژگان مجموعه شاخص ها و ویژگی ها را بر اساس دو ویژگی معرفی کردیم.به علاوه، با هدف ارزیابی مدل های مطرح شده، مبنای یادگیری عمقی تعریف شده است و عملکردهای دسته بندی مجموعه های متعدد با عملکرد پایه مقایسه شده اند. با هدف انجام یک تحقیق تجربی قیاسی، 6 مجموعه اطلاعات برای ارزیابی تمام مدل ها همراه با 6 شاخص ارزیابی احساسات مورد استفاده قرار گرفته است. در نهایت، ما یک تحلیل آماری انجام دادیم تا تایید کنیم که ترکیب اطلاعات به دست آمده از ویژگی های تعریف شده و تحلیل آنها روش موثری برای افزایش عملکرد شاخص احساسات می باشد.
سوال دوم این است که آیا تحلیل احساسات و عملکرد آن برای شاخص های قدیمی می تواند با استفاده از مجموعه شاخص ها و مدل ها انجام شود. با مشاهده جدول نمرات و رتبه های فریدمن ( جدول5) مشاهده میکنیم که مدل های مطرح شده باعث ارتقای عملکرد پایه می شوند. این مطلب بیانگر این است که ترکیب اطلاعات حاصل از منابع مختلف مثل ویژگی های سطحی – عمومی و بردارهای تاثیر کلمه می توانند باعث ارتقا نتایج تحلیل احساسات شوند.
3 سوال مهم تحقیقی در این مقاله مطرح شده اند. سوال اول این است که آیا چارچوبی برای توصیف روش های موجود در ارتباط با مجموعه تکنیک های قدیمی و مدرن در تحلیل احساسات وجود دارد. تا جایی که می دانیم، فرضیه ما از لیست واژگان و کاربرد نهایی آنها اولین تحقیق برای بیان این مسئله در تحلیل احساسات است.
توضیحات: این مقاله انگلیسی در سال 2017 در الزویر (Elsevier) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T1714 ترجمه گردیده است.
مقاله کارآفرینی، اقتصاد نهادی، و رشد اقتصادی: چشماندازی از اکوسیستم
5 Empirical results
We first estimate a model which only includes our (first difference) measures of the log of capital and labor in column (1) of Table 3. Next, we introduce the full system version of the logged GEI index, estimated in column (2). Finally, we investigate the separate effects of agency and institutions, in which the components making up the GEI index—the individual system (entrepreneurs) index and the institutional system index—enter the equation independently in columns (3) and (4).
We observe in Table 3 that the effect of log capital and labor always comes as positive and highly significant. The estimated coefficient on GEI is positive and statistically significant at the 5% level in column (2), the institutional component is mildly significant at the 10% level in column (3), and the entrepreneurial component is also mildly significant at the 10% level.
The comparison of the GEI ecosystem variable as against the individual components is non-nested, so we apply a Davidson-MacKinnon (1981, 1993) J-test to choose between them as better representations of the data. We find that the inclusion of the predicted values from GEI equation into the components specification leaves the institutional components insignificant at the 10% level, but applying the reverse does not eliminate the significance of the GEI index at the 5% level.
5 نتایج تجربی
ابتدا مدلی را برآورد میکنیم که تنها شامل معیارهای ما (اولین تفاضل) از لگاریتم سرمایه و کار در ستون 1 از جدول 3 است. سپس نسخه سیستم کامل شاخص GEI لگاریتمی براورد شده در ستون 2 را معرفی میکنیم. در نهایت، به بررسی اثرات جداگانه نمایندگی و سازمانها میپردازیم – شاخص (کارافرینان) سیستم فردی و شاخص سیستم سازمانی – معادله را به صورت مستقل در ستونهای 4 و 4 وارد میکنیم.
در جدول 3 مشاهده میکنیم که تاثیر لگاریتم سرمایه و کار همیشه مثبت و معنادار است. ضریب براورد شده GEI مثبت و به لحاظ آماری در سطح 5 درصد در ستون 2 معنادار است، مولفه سازمانی به طور خفیفی در سطح 10 درصد در ستون 3 معنادار است، و مولفه کارآفرینی نیز به طور خفیفی در سطح 10 درصد معنادار است.
مقایسه متغیر اکوسیستم GEI در برابر مولفههای فردی، غیر آشیانهای (غیر تو در تو) است، بنابراین ما از J-آزمون دیویدسون-مککینون (1981-1993) برای انتخاب نمایندگان بهتر دادهها بین آنها استفاده میکنیم. کشف میکنیم که گنجاندن مقادیر پیشبینی شده از معادله GEI در مشخصات مولفهها، مولفههای سازمانی را در سطح 10 درصد غیرمعنادار میسازد. اما اِعمال عکس آن، معناداری شاخص GEI در سطح 5 درصد را حذف نمیکند.
توضیحات: این مقاله انگلیسی در سال 2018 در اسپرینگر (Springer) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T1700 ترجمه گردیده است.
مقاله شهرهای ابتکاری هوشمند: تاثیر سیاست های شهر هوشمند بر نوآوری شهری
5. Do Smart City policies make cities more innovative? Results of propensity score matching estimates
5.1. Baseline estimates
This section discusses the results of empirically testing the relation between Smart City policies and urban innovation. The impact of SC policies on innovation can be manifold; consequently, we verify such impact on four different patent counts indicators, discussed in Section 3.
Results are presented as follows. Table 3 shows Probit estimates of the determinants of adopting Smart City policies (Eq. (1)). This represents the first stage of the PSM procedure. Table 4 shows instead the outcome of the PSM procedure proper. We estimate the impact of SC policies on urban innovation by looking at the average treatment effects on the treated for different urban innovation measures, viz. total patents, high-tech patents, ICT patents, and Smart City patents.
Results shown in Table 3 provide a few hints on the real determinants of SC policy adoption within the black box of urban smartness. In Caragliu and Del Bo (2016), an aggregate indicator of urban smartness is found to be positively associated with the probability to invest in SC policies. Table 3 hints at a positive role of intangible features (human and social capital) in increasing the likelihood that cities engage in Smart City policies. The infrastructure and e-government/natural resources components provide instead a more blurred picture. Taken together, these two results suggest that context conditions within each urban area still crucially matter in driving cities towards engaging in challenging policy programs.
5. آیا سیاست های شهر هوشمند سبب نوآوری بیشتر در شهرها می شود؟ نتایج حاصل از تخمین های مربوط به تطبیق امتیاز تمایل
5-1 تخمین های پایه ای
این بخش درباره نتایج حاصل از تست تجربی رابطه بین سیاست های شهر هوشمند و نوآوری شهری بحث می کند. تاثیر سیاست های SC بر نوآوری چندگانه است؛ در نتیجه، ما چنین تاثیری را براساس چهار نشانگر متفاوت شمارش اختراع که در بخش 3 بحث شده است تایید می کنیم.
نتایج به این صورت ارائه شده است. جدول 3 تخمین های Probit مربوط به عوامل تعیین کننده پذیرش سیاست های شهرهای هوشمند را نشان می دهد (رابطه 1). این جدول اولین مرحله از روند PSM را نشان می دهد. جدول 4 نتیجه حاصل از روند مناسب PSM را ارائه می کند. ما تاثیر سیاست های sC بر نوآوری شهری را با بررسی اثرات متوسط به کارگیری بر شهرهای اعمال شده برای معیارهای مختلف نوآوری شهری یعنی تعداد کل اختراعات، اختراعات با فناوری بالا، اختراعات ICT و اختراعات شهر هوشمند تخمین می زنیم.
نتایج نشان داده شده در جدول 3 نکاتی را درباره عوامل تعیین کننده واقعی پذیرش سیاست SC در جعبه سیاه هوشمندی شهری ارائه می کند. در مقاله Caragliu و Del Bo (2016)، مشخص شده است که شاخص کل هوشمندی شهری ارتباط مثبتی با احتمال سرمایه گذاری در سیاست های SC دارد. جدول 3 به نقش مثبت ویژگی های نامشهود (سرمایه انسانی و اجتماعی) در افزایش احتمال مشارکت شهرها در سیاست های شهر هوشمند اشاره دارد. مولفه های زیرساخت و دولت الکترونیک/ منابع طبیعی تصویر نامشخص تری را راائه می کند. به طور کلی، این دو نتیجه پیشنهاد می دهند که شرایط زمینه ای در هر منطقه شهری در تحریک شهرها به سوی مشارکت در تغییر برنامه های سیاستی از اهمیت زیادی برخوردار است.
توضیحات: این مقاله انگلیسی در سال 2019 در الزویر (Elsevier) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T1723 ترجمه گردیده است.
مقاله پهباد زیرآبی با دوربین پانورامیک جهت شناسایی خودکار ماهی بر اساس یادگیری عمیق
V. Conclusion
This paper presented an underwater drone equipped with fisheye lenses and with the function of a 360-degree panoramic camera for taking panoramic images by using an image generation algorithm. The 360-degree panoramic image generation and the underwater drone were developed with open-source software; the compute modules were extended on a Raspberry Pi compute module. We implemented an automatic underwater drone and conducted experiments in a lake. The 360-degree panoramic images were generated correctly. The experimental results showed that almost all fish species were recognized with a recognition rate higher than 85% with AlexNet and GoogLeNet (AlexNet achieved 87%). The recognition time for 115 images was 6 seconds. Hence, AlexNet may be used in a real-time application with high accuracy. In the future, we aim to improve the underwater drone to a practical level.
5- نتیجهگیری
این پژوهش یک پهباد زیرآبی را ارائه داده است که مجهز به عدسیهای چشم ماهی و کارکرد یک دوربین پانورامیک 360 درجه برای ایجاد کردن تصاویر پانورامیک با استفاده از یک الگوریتم تولید کردن تصویر بوده است. تولید کردن تصویر پانورامیک 360 درجه و پهباد زیرآبی با استفاده از سختافزار متنباز توسعه داده شده است؛ ماژولهای محاسباتی بر روی یک ماژول محاسباتی Raspberry Pi گسترش داده شده است. ما یک پهباد زیرآبی خودکار را پیادهسازی کردهایم و نتایج را در یک دریاچه بهدست آوردهایم. تصاویر پانورامیک 360 بهصورت صحیح تولید شدهاند. نتایج آزمایشگاهی نشان میدهد که تقریبا همهی گونههای ماهی با نرخ تشخیص بیش از 85% با استفاده از AlexNet و GoogLeNet (در AlexNet، 87% تشخیص بهدست آمده است) تشخیص داده شدهاند. زمان تشخیص برای 115 تصویر، 6 ثانیه طول کشیده است. پس ممکن است AlexNet به دلیل دقت بالا برای کاربرد در زمان واقعی استفاده گردد. ما در آینده قصد داریم جهت بهبود پهباد زیرآبی، از آن در سطح عملی استفاده کنیم.
توضیحات: این مقاله انگلیسی در سال 2018 در نشریه آی تریپل ای (IEEE) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T1726 ترجمه گردیده است.
مقاله شش چالش در مدل سازی سیاست های بهداشت همگانی
Abstract
The World Health Organisation’s definition of public health refers to all organized measures to prevent disease, promote health, and prolong life among the population as a whole (World Health Organization, 2014). Mathematical modelling plays an increasingly important role in helping to guide the most high impact and cost-effective means of achieving these goals. Public health programmes are usually implemented over a long period of time with broad benefits to many in the community. Clinical trials are seldom large enough to capture these effects. Observational data may be used to evaluate a programme after it is underway, but have limited value in helping to predict the future impact of a proposed policy. Furthermore, public health practitioners are often required to respond to new threats, for which there is little or no previous data on which to assess the threat. Computational and mathematical models can help to assess potential threats and impacts early in the process, and later aid in interpreting data from complex and multifactorial systems. As such, these models can be critical tools in guiding public health action. However, there are a number of challenges in achieving a successful interface between modelling and public health. Here, we discuss some of these challenges.
چکیده
به طور کلی، تمامی اقدامات سازمان یافته برای جلوگیری از بیماری، ارتقاء سلامت و افزایش طول عمر در میان جمعیت، تعریفی است که سازمان بهداشت جهانی در مورد بهداشت همگانی ارائه کرده است (سازمان بهداشت جهانی، 2014). مدل سازی ریاضیاتی نقش مهمی را در یافتن مناسب ترین و مقرون به صرفه ترین روش ها برای دستیابی به اهداف فوق ایفاء می کند. به طور معمول، برنامه های بهداشت همگانی را در بلند مدت اجرا می کنند. این برنامه ها برای بیشتر مردم جامعه، منافع زیادی دارند. به ندرت اتفاق می افتد که کارآزمایی های بالینی آنقدر بزرگ باشند که اثرات این منافع را به درستی بیان کنند. می توان داده های مبتی بر مشاهده را برای ارزیابی برنامه ای استفاده کرد که شروع شده است، اما برای پیش بینی تأثیری که در آینده سیاست پیشنهادی خواهد داشت، ارزش کمی دارند. علاوه بر این، اغلب، کارورزان بهداشت همگانی می بایست به تهدیدات جدیدی پاسخ دهند که در خصوص آنها اطلاعات چندانی موجود نیست یا اطلاعات قبلی در مورد آنها برای ارزیابی تهدید وجود نداشته است. مدل های محاسباتی و ریاضیاتی می توانند در امر ارزیابی تهدیدات و تأثیرات احتمالی در ابتدای این فرآیند و سپس در تفسیر داده های سیستم های پیچیده و چندعاملی کمک کنند. به همین ترتیب، این مدل ها می توانند ابزار مهمی برای هدایت فعالیت بهداشت همگانی باشند. با این حال، به منظور دستیابی به ارتباطی موفق بین طراحی و بهداشت همگانی، چندین چالش وجود دارد. در اینجا، برخی از آنها را مطرح می کنیم.
توضیحات: این مقاله انگلیسی در سال 2015 در نشریه الزویر (Elsevier) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T1834 ترجمه گردیده است.
مقاله مکان یابی توزیع شده در شبکههای حسگر بیسیم
2.1. Generic approach
From the known localization algorithms specifically proposed for sensor networks, we selected the three approaches that meet the basic requirements for self-organization, robustness, and energy-efficiency:
• Ad-hoc positioning by Niculescu and Nath [10],
• N-hop multilateration by Savvides et al. [12], and
• Robust positioning by Savarese et al. [11].
The other approaches often include a central processing element (e.g., convex optimization by Doherty et al. [9]), rely on an external infrastructure (e.g., GPS-less by Bulusu et al. [6]), or induce too much communication (e.g., GPS-free by Capkun et al. [7]). The three selected algorithms are fully distributed and use local broadcast for communication with immediate neighbors. This last feature allows them to be executed before any multihop routing is in place, hence, they can support efficient location-based routing schemes like GAF [16].
Although the three algorithms were developed independently, we found that they share a common structure. We were able to identify the following generic, three-phase approach 1 for determining the individual node positions:
1. Determine the distances between unknowns and anchor nodes
2. Derive for each node a position from its anchor distances.
3. Refine the node positions using information about the range (distance) to, and positions of, neighboring nodes.

2.1. رویکرد عمومی
از الگوریتمهای مکانیابی شناخته شده که به ویژه برای شبکههای حسگر ارائه شدهاند، سه رویکرد را انتخاب میکنیم که الزامات اساسی برای خود-سازماندهی، نیرومندی و انرژی به صرفگی را محقق میسازند.
• موقعیتیابی تک کاره که توسط نیکولسکو و ناث [10] ارائه شده است.
• مالتی لتریشن N-هاپ که توسط ساویدز و همکاران [12] ارائه شده است.
• موقعیتیابی نیرومند که توسط ساوارس و همکاران [11] ارائه شده است.
رویکردهای دیگر اغلب شامل یک عنصر پردازش مرکزی هستند (به عنوان مثال، «بهینهسازی محدب» ارائه شده توسط دوهرتی و همکاران [9])، بر زیرساخت خارجی تکیه دارند (به عنوان مثال، «GPS-less» ارائه شده توسط بالاسو و همکاران [6])، یا ارتباطات بسیار زیادی را القا میکنند (به عنوان مثال، «GPS-free» ارائه شده توسط کاپکان و همکاران [7]). سه الگوریتم انتخاب شده دارای توزیع کامل هستند و از پراکندگی محلی برای ارتباط با همسایگان بلاواسطه استفاده میکنند. این ویژگی آخر، اجرای آنها را قبل از این که هر گونه مسیریابی چند-مرحلهای در محل قرار گیرد، ممکن میسازد، از اینرو، آنها میتوانند از طرحوارههای کارامد مسیریابی مبتنی بر محل، مانند GAF 16، پشتیبانی کنند.
اگر چه سه الگوریتم به صورت مستقل ایجاد شدند، کشف کردیم که آنها ساختار مشترکی دارند. قادر به شناسایی رویکرد عمومی سه مرحلهای زیر برای تعیین موقعیتهای گره فردی بودیم:
1. تعیین فواصل بین گرههای نامعلوم و گرههای لنگر.
2. به دست آوردن یک موقعیت برای هر گره از فواصل لنگر آن.
3. اصلاح موقعیتهای گره با استفاده اطلاعات درباره دامنه (فاصله) تا گرههای همسایه و موقعیتهای گرههای همسایه.
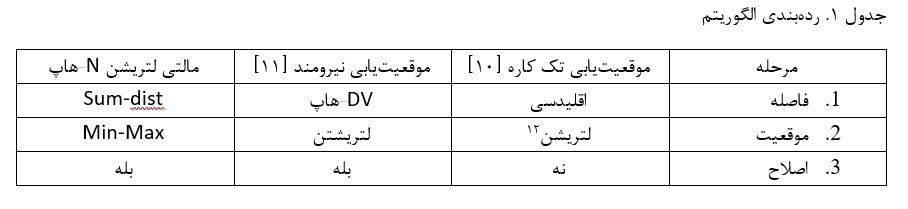
توضیحات: این مقاله انگلیسی در سال 2011 در نشریه الزویر (Elsevier) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T1700 ترجمه گردیده است.
مقاله مدلسازی ازدحام شبکه با استفاده از زنجیرههای مارکوف دو متغیرهی زمان- پیوسته
I. Introduction
Computer simulation is often used to evaluate the performance of network protocols and applications. The validity of network performance evaluation depends heavily on the accuracy to which the relevant network behaviors are represented by the simulation model. Ideally, the simulation model should abstract the salient features of the network that impact the performance of the protocol or application to be evaluated. Just as importantly, the simulation model should be sufficiently simple so that performance results can be obtained in a reasonable amount of time or even in real-time.
In [21], a continuous-time finite-state bivariate Markov chain was proposed as a model to simulate packet delays and losses in a computer network. One of the processes of the bivariate Markov chain, the underlying process, is not observable, while the other process, the observable process, represents the degree of congestion observed along a network path at any given time. More precisely, the observable state represents either a delay value or a “packet loss” condition due to severe congestion along the path. The observation samples can be obtained by employing a sequence of probes sent from a source to a destination host in a live network. The training data could also be obtained from a realistic network emulation environment such as Dummynet [6] or NIST Net [7] or a relatively detailed network simulator environment such as ns2 [11] or OPNET [9]. The probes measure round-trip delays between the source and destination, which are then quantized and mapped to the set of observable states of the bivariate Markov chain. Packet loss may be viewed as “infinite” delay and represented by a specially designated observable state.
1- مقدمه
شبیهسازی کامپیوتر اغلب برای ارزیابی عمکلرد پروتکلها و کاربردهای شبکه مورد استفاده قرار میگیرد. صحت ارزیابی عملکرد شبکه بهشدت بر روی دقت رفتارهای شبکهی مرتبط که بهوسیلهی مدل شبیهسازی بیان شده است، بستگی دارد. در یک وضعیت مطلوب، مدل شبیهسازی باید ویژگیهای برجستهی شبکه که بر عملکرد پروتکل یا کاربردهای ارزیابی شده تأثیر میگذارد را خلاصه کند. همانطور که حائز اهمیت است، مدل شبیهسازی باید بهاندازهی کافی ساده باشد تا نتایج عملکرد بتواند در یک مقدار معقول زمان یا رویداد در زمان واقعی بهدست آید.
در مرجع 21، زنجیرهی مارکوف دو متغیرهی حالت محدود زمان- پیوسته بهعنوان یک مدل جهت شبیهسازی تأخیرها و تلفات بسته در یک شبکهی کامپیوتری ارائه شده است. یکی از فرآیندهای زنجیرهی مارکوف دو متغیره یعنی فرآیند اساسی مشاهده نشده است، در حالیکه دیگر فرآیند، یعنی فرآیند مشهود بیانگر درجهی ازدحام مشاهده شده در راستای یک مسیر شبکه در هر زمان مشخص بوده است. حالت مشهود بهصورت دقیقتر نشاندهندهی یک مقدار تأخیر یا یک شرایط اتلاف شبکه بهدلیل ازدحام شدید در راستای مسیر بوده است. نمونههای مشاهده شده میتواند با بهکار بردن یک توالی از پروبهای فرستاده شده از یک منبع به یک مقصد میزبان در یک شبکهی مؤثر بهدست آید. همچنین دادههای آموزشی میتواند از طریق یک محیط ارزیابی شبکهی واقعی مانند (Dummynet (6 یا (NIST Net (7 یا از طریق یک محیط شبیهساز شبکهی با جزئیات نسبی مانند (ns-2 (11 یا (OPNET (9 بهدست آید. پروبها، تأخیر را در یک دور رفت و برگشت بین منبع و مقصد اندازهگیری میکنند که در این حالت مجموعهای از حالتهای مشاهده شدهی زنجیرهی مارکوف دو متغیره، پلهای و نگاشته میشوند. تلفات بسته ممکن است بهعنوان تأخیر نامحدود مشاهده شوند و به وسیلهی یک حالت مشهود که بهصورت ویژه تعیین شدهاند، نشان داده شوند.
توضیحات: این مقاله انگلیسی در سال 2011 در نشریه آی تریپل ای (IEEE) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T1726 ترجمه گردیده است.
مقاله تحلیل استراتژی های استقرار در زنجیره تامین معکوس
3. Disposition strategies in reverse supply chain
Based on green supply chain and reverse supply chain literatures, the current research on reverse logistics processes focus on product disposition options. Also known as product recovery options, Skinner et al. (2008) describe that right management of product disposition is a strategic move that paves the way towards superior performance. In analyzing reverse logistics among automobile, electronics and appliances manufacturers, Kumar and Putnam (2008) supported the existence of potential profit within recycled and remanufactured product through reuse services. Reuse services include equipment leasing where rents are generated from services rendered by a typical product.Careful considerations are required when selecting product disposition options for reprocessing returns received from downstream supply chains. Thierry et al. (1995) revealed that repair, refurbishing, remanufacturing, cannibalization and recycling are various operations to reduce the amount of waste that are landfilled or incinerated. Among the factors that are taken into consideration when evaluating the destiny of products bound to be reprocessed is the depth of disassembly (Thierry et al., 1995), impact to the environment (Gehinet al., 2008), age and condition of the returned product (Guide et al., 2000), quality of recovered product compared to original specification (Ijomah et al., 2007), destination of used products in secondary market (Rogerset al.,2010) and cost and profit structure of this green initiative. The type of product disposition depends on several key decisions such as cost and value of recovery, level of product sophistication and market value of products (Fernandez et al., 2008). Based on a review of reverse logistics and environment related literatures, adopted product disposition options are outlined in the figure 2 below.
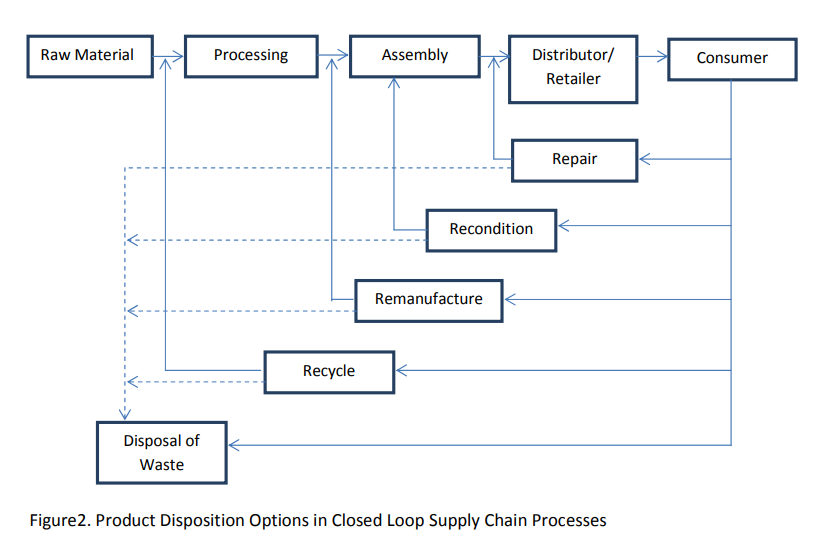
3. استراتژی استقرار در زنجیره تامین معکوس
بر اساس مقالات مرتبط با زنجیره تامین معکوس و زنجیره تامین سبز، تحقیقات فعلی در رابطه با فرایند های تدارکات معکوس متمرکز بر روی گزینه های استقرار محصولات می باشد. همچنین این فرایند که به عنوان گزینه بازیافت محصولات تعریف می شود و Skinner و همکارانش ( 2008) توصیف می کنند که مدیریت مناسب استقرار محصولات یک حرکت راهبردی است که مسیر را به سمت عملکرد برتر هموار می کند. در تحلیل تدارکات معکوس در میان تولید کننده های خودرو، الکترونیک و وسایل خانگی ، کومار و پوتنام ( 2008) ، بیان می کنند که استفاده از محصولات باز تولید شده و بازیافت شده از طریق خدمات استفاده مجدد ، می تواند منجر به شکل گیری ارزش برای سازمان ها شود. خدمات استفاده مجدد شامل اجازه تجهیزاتی می باشد که اجاره ها از خدماتی به دست می آید که با استفاده از یک محصول معمولی عرضه می شود. ملاحظات دقیقی در زمان انتخاب گزینه های استقرار برای بازدهی فرآوری مجدد که از زنجیره های تامین پایین دستی به دست می آید ، باید در نظر گرفته شود. Thierry و همکارانش ( 1995) ، نشان دادند که تعمیرات، تولید مجدد، نوسازی ، قطعه قطعه سازی و بازیافت روش های مختلف عملیاتی برای کاهش مقادیر زباله ای می باشد که در زمین دفن شده یا امحا می شود. در میان عواملی که در زمان ارزیابی مقصد محصولاتی که قرار است دوباره فرآوری شوند در نظر گرفته می شود، عمق تجزیه محصول ( Thierry et al., 1995)، تاثیر بر روی محیط زیست ( Gehinet al., 2008) ، سن کالا و شرایط محصولات بازگشت داده شده (Guide et al., 2000) ، کیفیت محصولات بازیابی شده در مقایسه با مشخصات اصلی (Ijomah et al., 2007) ، مقصد محصولات استفاده شده در بازار ثانویه (Rogerset al.,2010) و هزینه و ساختار سود این فعالیت سبز ( سازگار با محیط زیست) می باشد. نوع استقرار محصولات مبتنی بر تصمیم گیری های مختلف کلیدی مانند هزینه و ارزش بازیافت، سطح پیچیدگی محصولات و ارزش بازاری محصولات می باشد ( Fernandez et al., 2008). بر اساس مرور مقاله های تدارکات معکوس و مقالات مرتبط با محیط زیست، گزینه های مورد استفاده در استقرار محصولات در شکل 2 در قسمت زیر به صورت کلی نشان داده شده است.
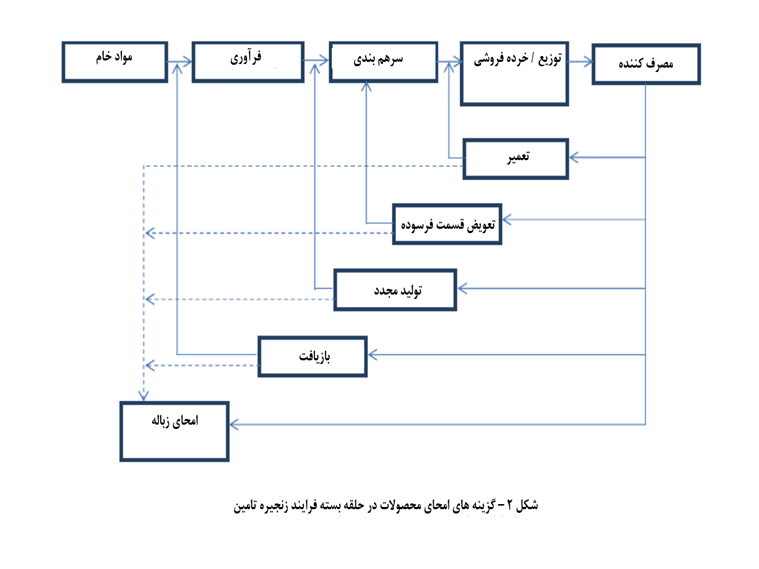
توضیحات: این مقاله انگلیسی در سال 2018 در نشریه امرالد (EmeraldInsight) چاپ شده و در سال 1399 در سایت ای ترجمه توسط مترجم کد T1702 ترجمه گردیده است.
مقاله مطالعه شیوه های متداول حسابداری با کتاب های درسی حسابداری مقدماتی
6. Discussion
6.1. Contextual influences
Any discussion relating to the source and capture of accounting data is incomplete if the context in which an accounting information system operates is not fully understood. Three of the texts acknowledge that the production of financial accounting reports is now a secondary information reporting function and that accounting systems are part of a much larger information system for big organisations, which affects how, where and when data is captured. However, the explanations are superficial and there is no explanation of the functionality or operation of the larger system or the relationship of the accounting system to the larger system. When texts refer to small business software such as MYOB, Quickbooks or Xero, they fail to acknowledge some of the ERP functionality is now present in small business software, for example processing quotations, and sales and purchase orders. Nor do they acknowledge the hundreds of applications which interface with small business software, or application program interfaces (APIs) which facilitate the exchange of data between software packages to achieve ERP functionality.
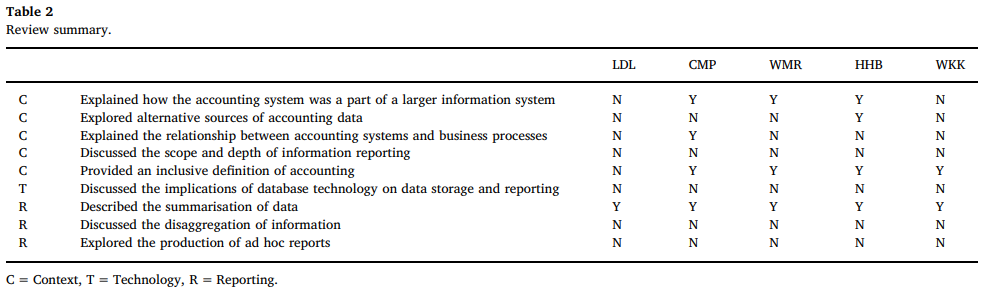
6. تشریح مطالب
6.1. عوامل بافتی تأثیرگذار
اگر بافتی که در آن سیستم اطلاعات حسابداری اجرا می شود را به طور کامل نشناسیم هر گونه بحث در مورد منبع و ثبت داده های حسابداری ناقص خواهد بود. نویسنده گان در سه کتاب درسی اذعان می کنند که ایجاد گزارش حسابداری مالی در حال حاضر تابع گزارش اطلاعات ثانویه است و اینکه سیستم های حسابداری بخشی از سیستم اطلاعاتی بسیار بزرگ تر برای سازمان های بزرگ هستند که بر چگونگی، زمان و مکان ثبت داده ها اثر می گذارد. با این حال، توضیحات آنها سطحی هستند و هیچ توضیحی در خصوص عملکرد و یا عملیات سیستم بزرگتر و یا رابطه ی سیستم حسابداری با سیستم بزرگتر داده نشده است. هنگامی که کتاب های درسی به نرم افزار کسب و کار کوچک از قبیل MYOB، Quickbooks و یا Xero ارجاع می دهند، در شناخت برخی از کارآرایی هایERP ناکام می مانند مثل پردازش قیمت ها و سفارشات خرید و فروش که در حال حاضر در نرم افزار کسب و کار کوچک ارائه می شود. آن کتاب ها به برنامه های کاربردی بیشمار و مشترک با نرم افزار کسب و کار کوچک و نیز رابط های برنامه ی کاربردی (APIs) اشاره نمی کنند. رابط های برنامه ی کاربردی عمل انتقال داده ها بین بسته های نرم افزار به منظور رسیدن به کارآیی ERP را آسان می کنند.
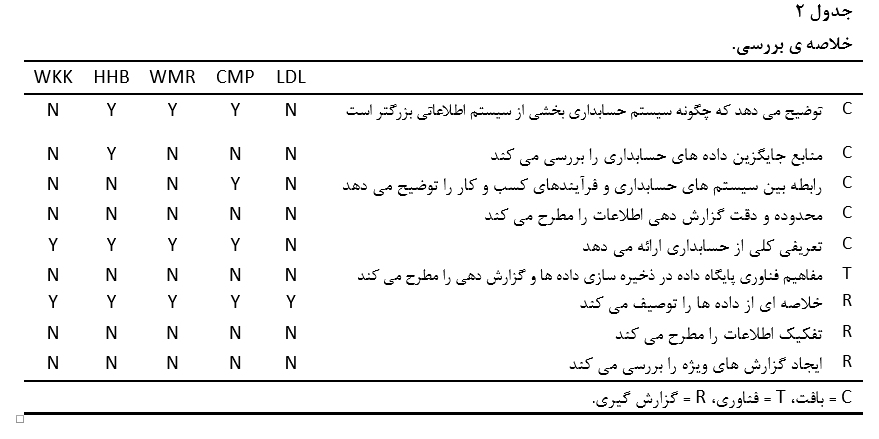
توضیحات: این مقاله انگلیسی در سال 2017 در نشریه الزویر (Elsevier) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T1834 ترجمه گردیده است.
مقاله اثرات خشک کردن انجمادی و پاششی بر ترکیبات فرّار شیر الاغ و پایداری پروتئین های آب پنیر
3. Results and discussion
3.1. Profile of DM volatile compounds
The profile of volatile compounds was determined on DM samples A (fresh milk), A2, A3 (milk stored at 20 °C for 48 and 72 h, respectively), B (freeze-dried milk) and C (spray-dried milk) in order to determine for the first time, the volatile fingerprint of fresh donkey milk and of DM subjected to the accelerated shelf-life test (samples A2 and A3) and to the freeze-drying and spray-drying processes (samples B and C, respectively).
It is well known that the flavor of fresh milk is due to the presence of sulphur and carbonyl compounds and other molecules such as alcohols and free fatty acids. A large contribution to milk flavor is given by volatile compounds which derive largely from milk fats. However, the composition of these volatile molecules that characterizes the flavor of fresh milk, changes after heat treatments or light exposures (Skibsted, 2000). For this reason, some particular volatile compounds have been used to identify milk freshness and to predict its shelf-life (Valero, Villamiel, Miralles, Sanz, & Martınez-Castro, 2001).
Regarding the composition of the aroma of DM samples, the averaged results of HS-SPME-GC-MS analysis are detailed in Table 1 that outlines also the aroma molecular fingerprint of each analyzed samples and the odor type of each molecule (Dunkel et al., 2009).
3. نتایج و بحث
3.1. مشخصات ترکیبات فرّار DM
مشخصات ترکیبات فرار بر روی نمونه های DM A (شیر تازه)، A2، A3 (شیر ذخیره شده در دمای 20 درجه سانتیگراد به ترتیب به مدت 48 و 72 ساعت)، B (شیر خشک شده انجمادی) و C (شیر خشک شده پاششی) تعیین شد تا برای اولین بار اثر انگشت فرار شیر تازه الاغ و DM تحت آزمایش عمر نگهداری تسریع شده (نمونههای A2 و A3) و فرآیندهای خشک کردن انجمادی و پاششی (به ترتیب نمونههای B و C) مشخص شود.
مشخص شده است که طعم شیر تازه ناشی از وجود ترکیبات گوگرد و کربونیل و سایر مولکول ها مانند الکل ها و اسیدهای چرب آزاد می باشد. ترکیبات فراری که عمدتاً در چربی شیر وجود دارند سهم بزرگی در طعم شیر دارند. با این حال، ترکیب این مولکول های فرار که طعم شیر تازه بخاطر وجود آنهاست، پس از عملیات حرارتی یا قرار گرفتن در معرض نور تغییر می کند (Skibsted، 2000). به همین دلیل، از برخی از ترکیبات فرار خاص برای شناسایی تازگی شیر و پیش بینی ماندگاری آن استفاده شده است (Valero، Villamiel، Miralles، Sanz، و Martınez-Castro، 2001).
در خصوص ترکیب عطر نمونه های DM، نتایج میانگین آنالیز HS-SPME-GC-MS در جدول 1 به تفصیل آورده شده است که اثر انگشت مولکولی عطر هر نمونه تجزیه و تحلیل شده و نوع بوی هر مولکول را نیز مشخص می کند (Dunkel و همکاران، 2009).
توضیحات: این مقاله انگلیسی در سال 2018 در الزویر چاپ شده و سال 1401 در سایت ای ترجمه توسط مترجم کد T1706 با کیفیت عالی ترجمه گردیده است.
مقاله چه چالشی برای یادگیری عمیق در تشخیص بدون محدودیت چهره وجود دارد؟
I. INTRODUCTION
Deep learning (DL) [1], [2] has recently become dominant in a wide variety of biometrics problems and many other artificial intelligence (AI) areas. One of the greatest successes of DL has been in face recognition (FR) where the accuracies have been improved greatly over the traditional methods [3], [4], [5], [6], [7], [8], [9], [10], [11], [12], [13], [14], [15]. We raise a question: Can deep learning really solve the face recognition problem? Or, can we say that, given the great success of DL, the face recognition problem has been solved or almost solved?
To answer this question, and get a better understanding of the performance of DL methods in FR, we perform an empirical study with designed experiments accordingly.
In face recognition, it is well-known that the hard problem is unconstrained face matching, in which we believe that the face image quality variations are probably the biggest issue that makes the problem hard. Based on this view, our conjecture is that the face image quality issue may still be a grand challenge even for the recently developed DL methods.
In FR with traditional features, it is well-known that the face image quality has a big influence on recognition accuracy; In DL features, however, a large dataset with face images of different quality for each subject, is used to train the deep models. Will the quality still be an issue?
In our empirical study, we design the face recognition experiments with matching across different face image qualities, which is seldom done in an explicit way in previous face recognition approaches. In practice, however, one can meet the cross-quality face matching problem frequently. For example, in the FBI’s interstate photo system (IPS), millions This was partly supported by a NSF-CITeR grant and a WV HEPC grant. of mugshot photos could be matched to face images collected from social media web sites where the wild photos may have a wide variety of qualities.
I. مقدمه
یادگیری عمیق (DL) [1,2] اخیراً در انواع مختلفی از مشکلات زیست سنجی و بسیاری از حیطه های دیگر هوش مصنوعی (AI) غالب بوده است. یکی از بزرگترین موفقیت های یادگیری عمیق (DL) در تشخیص چهره (FR) است که دقت آن نسبت به روشهای سنتی خیلی بهتر است [3,4,5,6,7,8,9,10,11,12,13,14,15]. ما یک سوال را مطرح می سازیم: آیا یادگیری عمیق واقعاً می تواند مشکل تشخیص چهره را حل کند؟ یا اینکه آیا می توانیم بگوییم که با توجه به موفقیت زیاد یادگیری عمیق (DL)، آیا مشکل تشخیص چهره حل یا تقریباً حل شده است؟ برای پاسخ دادن به این سوال و درک بهتر عملکرد روشهای یادگیری عمیق (DL) در تشخیص چهره (FR)، یک مطالعه تجربی را بر روی آزمایشات طراحی شده متناظر انجام می دهیم.
در تشخیص چهره، به خوبی اثبات شده است که مشکل سخت، تطابق بدون محدودیت چهره است که به نظر ما در آن، تغییرات کیفیت عکس چهره احتمالاً بزرگترین مشکلی است که سبب دشوار شدن این مشکل می گردد. بر اساس این دیدگاه، حدس ما این است که مشکل کیفیت عکس چهره حتی برای روشهای یادگیری عمیق (DL) که اخیراً توسعه داده شده اند، نیز هنوز یک چالش بزرگ خواهد بود.
اثبات شده است که در تشخیص چهره (FR) یا ویژگی های سنتی، کیفیت عکس چهره تأثیر زیادی بر روی دقت تشخیص دارد؛ با این حال در ویژگی های یادگیری عمیق (DL)، مجموعه داده بزرگی با عکس های چهره با کیفیت های مختلف برای هر موضوع برای آموزش دادن مدل های عمیق مورد استفاده قرار می گیرد. آیا کیفیت هنوز هم یک مشکل به حساب می آید؟
ما در مطالعه تجربی خود، آزمایشات تشخیص چهره را با تطابق در بین کیفیت های مختلف عکس چهره طراحی می کنیم که این کار در رویکردهای قبلی تشخیص چهره، بندرت به یک شیوه واضح انجام شده است. البته در عمل غالباً می توانیم مشکل تطابق چهره با کیفیت های مختلف را برطرف کنیم. به عنوان مثال در سیستم عکس بین ایالتی (IPS) سازمان FBI، میلیون ها عکس چهره را می توان با عکس های چهره جمع آوری شده از وبسایت های رسانه های اجتماعی تطبیق داد و این در حالی است که این عکس ها می توانند کیفیت های مختلفی داشته باشند.
توضیحات: این مقاله انگلیسی در سال 2018 در آی تریپل ای چاپ شده و سال 1401 در سایت ای ترجمه توسط مترجم کد T2383 با کیفیت عالی ترجمه گردیده است.
مقاله تأثیر Covid-19 بر فعالیت های اقتصاد اشتراکی
3. Methods
3.1. Research setting
This study has a global setting, so it is not attached to any particular region. It considers events, incidences, and decisions associated with the Covid-19 in the global SE sector. This study is explorative with a qualitative approach. Our data collection focuses on capturing the state of the SE amid the pandemic based on secondary data sources, which are widely used for high-quality research (Johnston, 2017). Indeed, secondary data is perhaps more appropriate for this study, because first-hand data could not provide comprehensive knowledge about the Covid-19’s effect on the SE. Secondary data has been widely used in a range of disciplines, including strategic orientation (Shortell and Zajac, 1990), microfinancing (Zhao and Wry, 2016), tourism injury problems (Bentley and Page, 2008), sustainable tourism (Pereira and Mykletun, 2012), and management reaction to hotel performance (Xie et al., 2014), and it has several benefits for academic studies (Houston, 2004). It shows the real decisions being made by real decision-makers, having been collected in a less obstructive manner and not influenced by the biases of self-reporting. The biases related to the key informant sampling approach can therefore be avoided. Recent studies based on online comments to a newspaper article about the SE present a vivid exemplification of the importance of such data for studies (Cheng and Foley, 2018; Cheng et al., 2019).
3. روش ها
3.1. شرایط تحقیق
این مطالعه یک مجموعه جهانی است، بنابراین به منطقه خاصی تعلق ندارد. در اینجا رویدادها، وقایع و تصمیمات مرتبط با Covid-19 در بخش جهانی SE بررسی میشود. این مطالعه اکتشافی بوده و دارای رویکرد کیفی است. جمع آوری دادههای ما بر درک وضعیت SE در میان پاندمی بر اساس منابع ثانویه دادهها متمرکز است، که به طور گستردهای برای تحقیقات با کیفیت بالا استفاده میشود (Johnston، 2017). در واقع، دادههای ثانویه شاید برای این مطالعه مناسبتر باشند، زیرا دادههای دست اول نمیتوانند اطلاعات کافی در مورد تأثیر Covid-19 بر SE را ارائه دهند. دادههای ثانویه به طور گستردهای در طیف وسیعی از منابع ، از جمله جهت گیری استراتژیک (Shortell و Zajac، 1990)، سرمایهگذاری خرد (Zhao و Wry، 2016)، مشکلات آسیبهای گردشگری (Bentley و Page، 2008)، گردشگری پایدار (Pereira و Mykletun، 2012) و واکنش مدیریت به عملکرد هتل استفاده شده است (Xie و همکاران، 2014)، و مزایای زیادی برای مطالعات آکادمیک در بر دارد (Houston، 2004). این دادهها نشان میدهند تصمیمات واقعی که توسط تصمیم گیرندگان واقعی گرفته میشود، به روشی آزادانهتر جمع آوری شدهاند و تحت تأثیر سوگیریهای خود گزارشگری قرار ندارند. بنابراین میتوان از سوگیریهای مربوط به رویکرد نمونه گیری مطلع کلیدی اجتناب کرد. مطالعات اخیر بر اساس نظرات آنلاین برای یک مقاله روزنامه در مورد SE نمونه بارزی از اهمیت این دادهها برای مطالعات را ارائه میدهد (Cheng و Foley، 2018؛ Cheng و همکاران، 2019).
توضیحات: این مقاله انگلیسی در سال 2021 در الزویر چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T1706 با کیفیت تخصصی ویژه ترجمه گردیده است.
مقاله سنجش ابعاد چند وجهی نقدینگی در بازارهای مالی: مرور مطالعات پیشین
5. Discussion
The liquidity of an asset or a financial market is a concept that encompasses different facets or aspects and is difficult to measure with a single measure. The literature emphasizes that there are five different aspects that characterize liquidity, namely, breadth, depth, immediacy, resilience, and tightness. Some authors point out the pitfalls of using one single measure or proxy when it comes to measuring liquidity (Bernstein, 1987). There are multiple measures proposed from high-frequency data, called liquidity measures, and others that only require low-frequency data, called liquidity proxies. There is no consensus on which measure is best suited to measure the liquidity of an asset or market, or even to decide which is best when it comes to showing one of the facets of liquidity. In fact, new liquidity measures are appearing in recent papers.
In any case, liquidity is a crucial issue for researchers, practitioners and policymakers. For researchers, liquidity measures are a topic of study or simply a necessary tool for financial asset valuation proposals. The choice between different liquidity measures is often made arbitrarily. It is difficult to propose a measure among the existing ones as the most appropriate for any proposal globally. Certainly, the selection of the liquidity measures depends on the research question. Existing papers obtain different results depending on the asset analyzed, the database available and even the frequency of observations. For example, recent empirical evidence shows that there are many liquidity proxies that are able to measure liquidity as accurately as liquidity measures in the US corporate bond market (Schestag et al., 2016) and in the US stock market (Fong et al., 2017). Therefore, the lack of high-frequency data is not a drawback in order to assess the degree of liquidity. These results are of interest to researchers, in the sense that they can avoid intensive data processing and cleansing procedures that many large databases require for being processing
5. بحث
نقدینگی یک دارایی یا یک بازار مالی، مفهومی است که جنبه ها یا وجوه مختلفی را شامل می گردد و ارزیابی آن با یک ابزار سنجش منفرد، دشوار است. مطالعات بر این موضوع تأکید دارد که پنج جنبه مختلف وجود دارد که نقدینگی را توصیف می کنند: عرض، عمق، فوریت، قابلیت ارتجاع، و فشردگی. برخی از مؤلفان به دام های (خطرات غیرمنتظره) استفاده از یک ابزار سنجش منفرد در هنگام ارزیابی نقدینگی اشاره می کنند (برن اشتاین 1987). ابزارهای سنجش متعددی از داده هایی با فراوانی بالا پیشنهاد شده اند که ابزارهای سنجش نقدینگی نامیده می شوند؛ و ابزارهای سنجش دیگری نیز وجود دارند که فقط مستلزم داده هایی با فراوانی کم هستند و نماینده های نقدینگی نامیده می شوند. هیچ همرایی در این باره وجود ندارد که کدام ابزار سنجش، برای ارزیابی نقدینگی یک دارایی یا یک بازار مناسب تر است، یا حتی توسط آن بتوانیم تصمیم بگیریم که کدام ابزار سنجش یکی از جنبه های نقدینگی را به بهترین شکل نشان می دهد. در حقیقت ابزارهای سنجش جدید نقدینگی در مقالات جدید ظاهر شده اند.
در هر صورت، نقدینگی مسئله مهمی برای محققان، متخصصان و سیاست گذاران است. برای محققان، ابزارهای سنجش نقدینگی موضوعی برای مطالعه، یا صرفاً یک ابزار ضروری برای پیشنهادات ارزشگذاری دارایی مالی هستند. انتخاب بین ابزارهای سنجش مختلف نقدینگی اغلب به صورت قراردادی است. پیشنهاد یک ابزار سنجش در بین ابزارهای سنجش موجود کار دشواری است، به طوری که این ابزار سنجش برای هر پیشنهاد جهانی مناسب ترین گزینه باشد. مسلماً انتخاب ابزارهای سنجش نقدینگی به سوال تحقیق بستگی دارد. مقالات موجود بسته به دارایی تحلیل شده، پایگاه داده موجود و حتی فراوانی مشاهدات، نتایج مختلفی را بدست می آورند. به عنوان مثال شواهد تجربی اخیر نشان میدهد که نماینده های نقدینگی بسیاری وجود دارند که می توانند نقدینگی را با همان دقت ابزارهای سنجش نقدینگی در بازار اوراق قرضه شرکتهای آمریکایی (اسکی استاگ و همکارانش 2016) و در بازار سهام ایالات متحده (فانگ و همکارانش 2017) ارزیابی کنند. بنابراین فقدان داده هایی با فراوانی بالا، در ارزیابی درجه نقدینگی یک عیب به شمار نمی آید. این نتایج مورد توجه محققان هستند، از این لحاظ که می توانند از پردازش شدید داده ها و روندهای تنظیفی اجتناب کنند که بسیاری از پایگاه داده های بزرگ برای پردازش به آنها نیاز دارند.
توضیحات: این مقاله انگلیسی در سال 2020 در الزویر چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T2383 با کیفیت عالی ترجمه گردیده است.
مقاله یک روش بهبودیافته برای آنالیز اواپراتورهای فین دار و لولهای حاوی مبرد مخلوط زئوتروپ با سوء توزیع جریان هوا
3. Model verification
3.1. Refrigerant supply loop
The refrigerant loop consists of a compressor, an oil separator, a shell and tube type condenser, a receiver, a flow meter, capillary tubes, an evaporator, and an accumulator, as shown in Fig. 5. Discharged oil and refrigerant from the compressor passes through the oil separator, and only high pressure and temperature refrigerant flows into the shell and tube condenser. The cooling water loops consist of a constant water bath, a pump, a by-pass loop, and a motor driven micro-valve.
These are used to control the sub-cooling of the refrigerant at the inlet of the distributor. A mass flow meter measures the mass flow rate of the refrigerant liquid. A receiver and sight glass are used to reserve and check the liquid refrigerant. The supplementary temperature control loop controls the refrigerant temperature at the distributor inlet. The temperature and pressure are measured at the distributor inlet to determine the amount of sub-cooling and the properties of the refrigerant. The temperature is measured using a Pt 100 RTD inserted through the copper tube wall. The pressure is detected by a digital pressure gauge with a range of 0–5 MPa. The thermodynamic quality at the inlet of test evaporator is calculated, including the amount of sub-cooling and assuming an adiabatic process in the capillary tubes. After the test section, the refrigerant is returned to the compressor through a supplementary heater and an accumulator. The refrigerant temperature and pressure are measured at the outlet of the evaporator in the same manner as at the inlet of distributor, except that the digital pressure gauge has a range of 0–1.5 MPa.
3. تأیید مدل
3.1. حلقه عرضه مبرد
حلقه مبرد همانطور که در شکل 5 نشان داده شده، متشکل از یک کمپرسور، یک تفکیک کننده روغن، یک کاندنسور نوع پوسته و لوله، یک گیرنده، یک فلومتر، لولههای کاپیلاری، یک اواپراتور، و یک اکومولاتور است. روغن تخلیه شده و مبرد از طریق تفکیک کننده روغن از کمپرسور عبور میکند و تنها مبرد پرفشار و دارای حرارت بالا در کاندنسور لوله و پوسته جریان پیدا میکند. حلقههای آب خنک کننده متشکل از یک حمام آب ثابت، یک پمپ، یک حلقه میان گذر و یک شیر سوزنی موتوری میباشد.
اینها برای کنترل خنک کنندگی مبرد در ورودی توزیع کننده استفاده میشوند. فلومتر جرمی، میزان جریان جرمی سیال مبرد را اندازه گیری میکند. از یک گیرنده و شیشه اندازه گیری برای ذخیره و کنترل مبرد مایع استفاده میشود. حلقه مکمل کنترل دما، دمای مبرد را در ورودی توزیع کننده کنترل میکند. دما و فشار در ورودی توزیع كننده اندازه گیری میشوند تا میزان سرمایش تابع و ویژگیهای مبرد مشخص شوند. دما با استفاده از Pt 100ΩRTD که از طریق جداره لوله مسی وارد شده، اندازه گیری میشود. فشار توسط یک فشار سنج دیجیتال با طیف 0-5 MPa مشخص میشود. کیفیت ترمودینامیکی از جمله میزان زیرخنک سازی با در نظر گرفتن فرایند آدیاباتیک در لولههای کاپیلاری، در ورودی اواپراتور آزمایشی محاسبه میشود. بعد از بخش آزمایشی، مبرد از طریق هیتر مکمل و یک اکومالاتور به کمپرسور برمی گردد. درجه حرارت و فشار مبرد در خروجی اواپراتور همانند ورودی توزیع کننده اندازه گیری میشود، به استثنای اینکه فشارسنج دیجیتال دارای طیف 0-1.5 MPa است.
توضیحات: این مقاله انگلیسی در سال 2003 در الزویر چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T1706 با کیفیت عالی ترجمه گردیده است.
مقاله مرور جامع مطالعه و توسعه سیستم های خودترمیمی مبتنی بر میکروکپسول برای سازه های بتنی در دانشگاه شنژن
4.4. Evaluation of a Microcapsule Based Self-Resilience System
The behavior and performance of the microcapsule based self-resilience system have to be evaluated through effective and meaningful ways (either experimentally or numerically). Up to now, various techniques have been applied to appraise the obtained system with success to some extent. In addition to the traditional macro test methods (for determination of mechanical and transport properties of concrete) [26,46–48], the more advanced technology, such as the X-ray computed tomography (XCT) and the image analysis technique, has been adopted in the evaluation process [49].
The whole healing process and healing effect of a microcapsule based self-healing system in concrete was monitored and qualitatively as well as quantitatively evaluated by means of XCT and an image analysis technique. The experimental procedures are illustrated in Figure 21A. A microscopic compression testing instrument was integrated into the XCT system to obtain a real-time compressive loading. Sample 1 and Sample 2 were put in the built-in loading device and pre-loaded with 1100 N and 900 N, respectively. As shown in Figure 22A, microcapsules are broken by the formation of cracks (working mechanism of a physical trigger) and healing materials are released from microcapsules. Then, the samples with initial cracks were cured in different curing conditions, in which Sample 1 was submerged and Sample 2 was cured in a standard curing condition (95% RH, ±20). XCT was applied to monitor the variation of inner microstructures at different healing times (see Figure 21B). Based on the raw data measured by XCT, the reconstruction of the inner microstructure was carried out by means of an image analysis technique.
4.4 ارزیابی یک سیستم خودترمیمی مبتنی بر میکروکپسول
رفتار و عملکرد سیستم خودترمیمی (خودارتجاعی) مبتنی بر میکروکپسول را باید به راه های مؤثر و معنی داری (به صورت تجربی یا عددی) ارزیابی کنیم. تاکنون تکنیک های مختلفی برای ارزیابی سیستم بدست آمده تا حدودی با موفقیت اعمال شده است. علاوه بر روشهای آزمایش سنتی ماکرو (برای تعیین خواص مکانیکی و حمل و نقل بتن) [26,46-48]، تکنولوژی های پیشرفته تری – همچون توموگرافی رایانه ای با اشعه ایکس (XCT) و تکنیک تحلیل تصویر – در فرآیند ارزیابی اتخاذ شده است [49].
فرآیند ترمیم کلی و تأثیر ترمیمی یک سیستم خودترمیمی مبتنی بر میکروکپسول در بتن مورد نظارت قرار گرفت و با استفاده از XCT و یک تکنیک تحلیل تصویر به صورت کیفی و کمّی ارزیابی شد. روشهای تجربی را در شکل 21A نشان داده ایم. یک ابزار آزمون تراکم میکروسکوپی را به سیستم XCT اضافه کردیم تا یک بارگذاری تراکمی بلادرنگ را ممکن سازیم. نمونه 1 و نمونه 2 را در دستگاه بارگذاری پیش ساخته قرار دادیم و بترتیب پیش بارگذاری های 1100 N و 900 N را روی آنها اعمال کردیم. همانطور که در شکل 22A نشان داده شده است، میکروکپسول ها با شکل گیری ترک ها شکسته شدند (مکانیزم کاری یک محرک فیزیکی) و مواد ترمیمی از میکروکپسول ها آزاد شدند. سپس نمونه های دارای ترک های اولیه را در شرایط عمل آوری مختلف عمل آوردیم، که نمونه 1 را در آب غوطه ور ساختیم و نمونه 2 را در یک شرایط عمل آوری استاندارد (95% RH, ±20) عمل آوردیم. XCT برای نظارت تغییرات ریزساختارهای داخلی در زمان های ترمیم مختلف اعمال شد (به شکل 21B نگاه کنید). بر اساس داده های خام ارزیابی شده با XCT، بازسازی ریزساختار داخلی با استفاده از یک تکنیک تحلیل تصویر انجام شد.
توضیحات: این مقاله انگلیسی در سال 2017 در نشریه mdpi چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T2383 با کیفیت عالی ترجمه گردیده است.
مقاله شبیه سازی زنجیره تأمین سبز اراضی بر اساس پویایی سیستم و بهینه سازی سیاست ها
3.1. Energy subsystem
Grain is not only an important component of energy subsystem but also the most fundamental expression of man-earth relationship. It includes two parts, grain production and grain utilization. In energy subsystem, we take grain per-unit-area yield as core variable and grain total yield is decided by both grain per-unit-area yield and sowing area of grain crop. Total population and grain consumption level per capita decide the total grain demand; total yield and demand of final grain together decide the supply and demand ratio of grain. Fig. 2 is a causal graph that only qualitatively expresses relationships among variables and reflects influences of positive and negative feedback. Only after establishing causal graphs of every subsystem can numerical relationship among variables be effectively and quantitatively analyzed.
3.2. Economy subsystem
In economy subsystem, total industrial output value and effective irrigation area of farmland are taken as core variables. Judging from industrial level, the higher the total industrial output value, the better the economic development and the more the industrial water consumption. Similarly, effective irrigation area of farmland decides the agricultural water consumption. Changes of industrial water consumption and agricultural water consumption will make the total water demand change and finally affect the supply and demand ratio of water resource. Causal relationship is showed in Fig. 3.
3.3. Technology subsystem
In agricultural production and utilization, technological progress is mainly reflected in the improvement of efficiency of labor force to land use. Therefore, to land green supply chain, population will directly influence the degree of technological content of land. This shows that we can take population as the substitute index for technological factor and combine it with other subsystems. Here we take total population as a core variable and divide it into urban population and rural population. Suppose that urban and rural household domestic water consumption is a fixed value, number of both urban and rural population will decide the total domestic water consumption together and further influence the water demand and water supply-demand ratio in the whole system.
3.1 سیستم فرعی انرژی
بذر نه تنها مؤلفه مهمی از سیستم فرعی انرژی است بلکه اساسی ترین جلوه از رابطه انسان و زمین نیز می باشد. بذر دارای دو بخش «تولید بذر، و استفاده از بذر» است. ما در سیستم فرعی انرژی، بازده بذر در هر واحد مساحت را بعنوان متغیر اصلی در نظر می گیریم و بازده کلی بذر توسط دو مؤلفه «بازده بذر در هر واحد مساحت» و «مساحت بذرافشانی محصول» تعیین می شود. جمعیت کلی و سطح مصرف سرانه بذر، تقاضای کلی بذر را تعیین می کنند؛ بازده کلی و تقاضای بذر نهایی نیز با هم، نسبت عرضه و تقاضای بذر را تعیین می کنند. شکل 2 یک نمودار سببی را نشان میدهد که روابط بین متغیرها را فقط بصورت کیفی نشان میدهد و تأثیرات بازخوردهای مثبت و منفی را منعکس می سازد. فقط بعد از ترسیم نمودارهای سببی هر سیستم فرعی، روابط عددی بین متغیرها را می توانیم بصورت مؤثر و کمی تحلیل کنیم.
3.2 سیستم فرعی اقتصاد
در سیستم فرعی اقتصاد، مقدار خروجی صنعتی کلی و مساحت آبیاری مؤثر زمین های کشاورزی بعنوان متغیرهای اصلی در نظر گرفته میشوند. اگر از سطح صنعتی قضاوت کنیم، هر چه مقدار خروجی صنعتی کلی بیشتر باشد توسعه اقتصادی بهتر، و مصرف آب صنعتی بیشتر خواهد بود. همچنین مساحت آبیاری مؤثر زمین کشاورزی تعیین کننده مصرف آب کشاورزی است. تغییرات مصرف آب صنعتی و مصرف آب کشاورزی، تغییر تقاضای کلی آب را نشان میدهد و در نهایت بر روی نسبت عرضه و تقاضا منابع آب تأثیر خواهد گذاشت. رابطه سببی در شکل 3 نشان داده شده است.
3.3 سیستم فرعی تکنولوژی
در تولید و بهره برداری کشاورزی، پیشرفت تکنولوژیکی عمدتاً تحت در بهبود کارایی نیروی کار برای کاربری زمین منعکس می شود. بنابراین برای زنجیره تأمین سبز اراضی، جمعیت تأثیر مستقیمی روی درجه محتوای تکنولوژیکی اراضی خواهد گذاشت. این نشان میدهد که ما می توانیم جمعیت را بصورت یک شاخص جایگزین برای عامل تکنولوژیکی در نظر بگیریم و آنرا با سیستم فرعی های دیگر ترکیب کنیم. ما در اینجا جمعیت کلی را بصورت یک متغیر اصلی در نظر می گیریم و آنرا به جمعیت شهری و جمعیت روستایی تقسیم می کنیم. فرض کنید که مصرف آب داخلی خانوارهای شهری و روستایی یک مقدار ثابت باشد، پس تعداد هر دو جمعیت شهری و روستایی تعیین کننده مصرف آب داخلی کلی خواهد بود و بر تقاضای آب و نسبت عرضه-تقاضای آب در سیستم کلی تأثیر خواهد گذاشت.
توضیحات: این مقاله انگلیسی در سال 2019 در الزویر (Elsevier) چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T2383 با کیفیت عالی ترجمه گردیده است.
مقاله اثر صادرات بر انتخاب های بدهی مالی SME ها (شرکت هایی با اندازه های کوچک و متوسط)
1. Introduction
Over the past decades, considerable effort has been devoted to enhancing our understanding of the complexity of corporate financing decisions. To date, studies on corporate capital structure and debt maturity choices have mainly focused on firm characteristics and industry determinants (De Jong, Kabir, & Nguyen, 2008; Titman & Wessels, 1988), as well as on the influence of the national culture, legislation and other country characteristics (Demirgüç-Kunt & Maksimovic, 1999; Fan, Titman, & Twite, 2012). Studies investigating the relationship between internationalization and corporate financing policy, however, are much more limited and are mostly confined to large, stock exchange quoted firms. One of the main insights of this literature is that multinational corporations (MNCs) have lower longterm debt ratios and higher short-term debt ratios than those of comparable domestic corporations (DCs) (Burgman, 1996; Doukas & Pantzalis, 2003; Fatemi, 1988). This leverage differential between MNCs and DCs is explained by the fact that the positive effect of geographic sales diversification on long-term debt financing is offset by the increased risk stemming from exchange rate exposure and unforeseen political events. Furthermore, due to their operational complexity, MNCs are more informationally opaque, which increases the agency costs of debt.
To mitigate the problems associated with a riskier borrower profile and agency conflicts, loan maturities are shortened (Barclay & Smith, 1995; Myers, 1977). Building on these studies, the aim of this article is to advance the current literature by empirically investigating the impact of exporting on the corporate financing decisions of another important class of exporters, viz., small and mediumsized enterprises (SMEs). Since SMEs cannot substitute short-term and long-term debt financing as easily as large companies - due to difficulties in obtaining long-term debt financing from financial institutions (Ortiz-Molina & Penas, 2008) - the mechanism through which export activities affect SME financing policies may very well be different from what is demonstrated in the MNC literature. According to the World Trade Organization (WTO), access to financial resources to support export activities is a key concern for SMEs since, besides the one-time upfront sunk costs (e.g., costs related to compliance with foreign market regulations and preparatory market research), exporting requires substantial ongoing investment in working capital, as export activities considerably lengthen the cash conversion cycle of the firm (e.g., through longer shipment periods and the administrative burden associated with trading internationally) (WTO, 2016). Hence, understanding how exporting SMEs cope with these financing needs may yield useful insights for exporters, banks and policy makers.
1. مقدمه
در دهه های گذشته تلاش های زیادی برای افزایش درک ما از پیچیدگی تصمیمات مالی سازمانی انجام شده است. تاکنون مطالعاتی در مورد ساختار سرمایه سازمانی و انتخاب های سررسید بدهی عمدتاً بر خصوصیات شرکت و عوامل تعیین کننده صنعت (دی جانگ، کبیر، و نگوئن 2008؛ تیتمن و وِسلز 1988)، و همچنین بر تأثیر فرهنگ ملی، قانونگذاری و سایر خصوصیات کشور (دمیرگوچ-کانت و ماکسی موویک 1999؛ فَن، تیتمن و توایت 2012) متمرکز بوده اند. با اینحال مطالعاتی که رابطه بین بین المللی شدن و سیاست مالی سازمانی را بررسی کرده اند خیلی محدودتر هستند و غالباً به شرکت های بزرگ، با قیمت بالای بورس اوراق بهادار محدود می گردند. یکی از بینش های اصلی این مقالات این است که شرکتهای چند ملیتی (MNC) در مقایسه با شرکت های داخلی مشابه (DC)، نسبت بدهی بلند مدت کمتر، و نسبت بدهی کوتاه مدت بیشتری دارند (برگمَن 1996؛ دوکاس و پانزالیس 2003؛ فاطمی 1988). این تفاوت بهره گیری بین MNC ها و DC ها با این حقیقت توضیح داده می شود که تأثیر مثبت تنوع فروش جغرافیایی بر تأمین مالی بلند مدت از محل استقراض توسط افزایش ریسک ناشی از نمایش نرخ ارز و رویدادهای سیاسی پیش بینی نشده جبران می شود. بعلاوه MNC ها بعلت پیچیدگی عملیاتی خود از لحاظ اطلاعاتی، مبهم تر (ناشفاف تر) هستند و این سبب افزایش هزینه های نمایندگی بدهی ها می گردد.
برای کاهش مشکلات همراه با یک خصوصیات استقراض مخاطره آمیزتر و ناسازگاری های نمایندگی، سررسید وام ها کوتاه تر می گردد (بارکلی و اسمیت 1995؛ مایرز 1977). مطالعه حاضر بر مبنای این مطالعات نوشته شده است و هدف آن توسعه مقالات جاری از طریق «بررسی تأثیر صادرات بر روی تصمیمات مالی سازمانی طبقه مهم دیگری از صادرکنندگان (یعنی SME ها)» است. چون SME ها – بعلت مشکلاتی که در بدست آوردن تأمین مالی بلند مدت از محل استقراض از مؤسسات مالی دارند – به آسانی شرکت های بزرگ، نمی توانند جایگزین تأمین مالی بلند مدت از محل استقراض گردند (اورتیز-مونیلا و پناس 2008)، بنابراین مکانیزم تأثیرگذاری فعالیت های صادرات بر سیاست های مالی SME میتواند با آنچه که در مقالات MNC اثبات شده است متفاوت باشد. طبق سازمان تجارت جهانی (WTO)، دسترسی به منابع مالی برای پشتیبانی از فعالیت های صادراتی، یکی از نگرانی های مهم برای SME ها است چون صادرات علاوه بر هزینه های از دست رفته آشکار قبلی (بعنوان مثال هزینه های مربوط به پیروی از مقررات بازارهای خارجی و تحقیقات مقدماتی بازار)، نیازمند سرمایه گذاری مداوم قابل توجهی در سرمایه در گردش (سرمایه جاری) نیز می باشد چون فعالیت های صادرات، طول چرخه تبدیل پول نقد شرکت را (بعنوان مثال از طریق دوره های حمل طولانی تر و مسئولیت اجرایی همراه با تجارت بین المللی) تا حد زیادی افزایش میدهد (WTO, 2016). بنابراین درک اینکه SME های صادرکننده چطور این نیازهای مالی را برآورده می کنند میتواند بینش های سودمندی را برای صادرکنندگان، بانک ها و سیاست گذاران ایجاد کند.
توضیحات: این مقاله انگلیسی در سال 2019 در نشریه الزویر (Elsevier) چاپ شده و سال 1400 در سایت ای ترجمه توسط مترجم کد T2383 با کیفیت عالی ترجمه گردیده است.
مقاله رابطه بین خشونت خانگی علیه زنان و ریسک خودکشی
Data collection
The data were collected between March 2017 and November 2017. The data were collected by the research through face-to-face interview with the married women, registered at Family Health Centers, during home visits. It took approximately 15-20 minutes to apply the data collection form. Questions that women do not understand are explained without adding any comment.
The ethical principles of the study
In order to conduct the study, approval was obtained from the Ethics Committee of the Inönü University Faculty of Health Sciences (2017 / 19-7) and legal permissions were obtained from the related institutions. The women included in the study were informed about the purpose of the study and their questions were answered. The women were informed about that the information they provide would be confidential, not be used elsewhere and that they have the right to withdraw from the study anytime they want.
Assessment of the Study data
The data obtained from the study were evaluated by using SPSS 18 statistical package program. Percentage distribution, arithmetic mean, t-test in independent groups and Correlation were used to assess the data.
Results
It was found that 39.3% of the women who participated in the study were in the age range of 29-39 years, 26.7% were married for 18-23 years, 40.1% had 3 or more children, 56.7% ACCEPTED MANUSCRIPT were married with arranged marriage, 57.9% had middle income level and husbands of 38.9% of them were in the age range of 29-39 years (Table 1).
جمع آوری دادهها
دادهها بین ماههای مارس و نوامبر 2017 جمع آوری شدند. دادهها با استفاده از تحقیق از طریق مصاحبه رو در رو با زنان متأهل ثبت نام شده در مراکز بهداشت خانواده در طی بازدید از خانه جمع آوری شدند. تکمیل فرم جمع آوری دادهها تقریباً 15-20 دقیقه طول میکشید. سوالاتی که زنان متوجه نمیشدند بدون اضافه کردن هیچ نظری توضیح داده میشد.
اصول اخلاقی مطالعه
اجرای این مطالعه توسط کمیته اخلاقی Inönü از دانشکده علوم بهداشت و سلامت مورد تأیید قرار گرفت (2017/ 19-7) و مجوزهای قانونی آن نیز از مؤسسات مربوطه اخذ شد. زنان شامل در این مطالعه با آگاهی از هدف مطالعه به سؤالات پاسخ دادند. به آنها این اطمینان داده شد که اطلاعات ارائه شده توسط آنها محرمانه بماند و در هیچ جای دیگری مورد استفاده قرار نگیرد و هر زمان هم که بخواهند این حق را دارند که از این مطالعه صرف نظر کنند.
ارزیابی دادههای مطالعه
دادههای به دست آمده از این مطالعه با استفاده از برنامه فشرده آماری SPSS 18 مورد ارزیابی قرار گرفت. از توزیع درصدی، میانگین عددی، آزمون تی در گروههای مستقل و همبستگی برای ارزیابی دادهها استفاده شد.
نتایج
مشخص شد که 39.3 درصد از زنانی که در این مطالعه شرکت داشتند دارای محدوده سنی بین 29 تا 39 سال بودند، 26.7 % از آنها به مدت 18-23 سال متأهل بودند، 40.1 % دارای سه فرزند و یا بیشتر بودند، 56.7 % به شیوه سنتی ازدواج کرده بودند، 57.9 % دارای سطح درآمد متوسطی بودند و سن شوهران 38.9 % از آنها بین 29 تا 39 سال بود (جدول 1).
توضیحات: این مقاله انگلیسی در سال 2018 در نشریه الزویر (Elsevier) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T1706 با کیفیت عالی ترجمه گردیده است.
مقاله حذف رسوب از مخازن انرژی آبی جریان رودخانه ای توسط تخلیه هیدرولیک
Abstract
The concept of sustainable development is gaining popularity and hydroelectric projects designed and operated on this concept require sediment management as prime design criteria. Drawdown flushing is being practised in such projects for sediment management. Investigations using hydraulic models are required for the projects to address the site-specific design concerns. In the present study, simulations conducted using hydraulic model for sediment removal by drawdown flushing of the reservoir of Punatsangchhu hydroelectric project, Bhutan, is presented. The experiments on 1:100 geometrically similar scale model indicated that flushing is effective in maintaining the power intake area clear of sediment deposition. Deposition from the upstream reaches could not be flushed hydraulically. Furthermore, based on wide range of experimental data from hydraulic model studies, empirical equations have been developed for predicting the quantity of sediment that can be flushed from the reservoirs. The present equations have been developed including more parameters than those used in equations already available in literature. Two equations have been developed for different riverbed slope ranges with steep slope (0.005–0.04) and moderate slope (0.001–0.005). The equations developed were validated against different sets of data and it indicated that the predictions could be made within reasonable accuracy. These equations can be effectively used for hydraulic design of sediment removal from run-of-the-river hydropower reservoirs.
چکیده
محبوبیت مفهوم توسعه پایدار رو به افزایش است و پروژه های هیدروالکتریک طراحی شده و اجرا شده درباره این مفهوم نیازمند مدیریت رسوب (بعنوان یک معیار اصلی طراحی) هستند. تخلیه فرونشینی برای مدیریت رسوب در چنین پروژه هایی اجرا میشود. بررسی ها با استفاده از مدلهای هیدرولیک برای پروژه ها لازم هستند تا نگرانی های طراحی مختص به سایت را برطرف کنند. در مطالعه حاضر شبیه سازی هایی معرفی شده است که از مدل هیدرولیک برای حذف رسوب توسط تخلیه فرونشینی مخازن پروژه هیدروالکتریک پونات سانگچو (واقع در بوتان ) استفاده کرده اند. آزمایشات انجام شده بر روی مدل مقیاس 1:100 هندسی مشابه نشان میدهد که تخلیه (شستشو توسط جریان آب) در حفظ منطقه آبگیر نیروگاه خالی از ته نشینی رسوب، مؤثر است. ته نشینی از بالادست جریان رودخانه را نمی توان بصورت هیدرولیکی تخلیه کرد. بعلاوه بر اساس دامنه وسیعی از داده های تجربی از مطالعات مدل هیدرولیک، معادلات تجربی برای پیش بینی کمیت رسوبی که از ذخایر (مخازن) تخلیه میشود توسعه داده شده اند. معادلات حاضری که توسعه داده شده اند نسبت به معادلات استفاده شده در معادلات بیان شده در مقالات موجود دارای پارامترهای بیشتری هستند. دو معادله برای دامنه های مختلف شیب بستر رودخانه با شیب تند (0.005-0.04) و شیب متوسط (0.001-0.005) توسعه داده شده است. معادلات توسعه یافته بر اساس مجموعه داده های مختلف اعتباریابی شدند و مشخص شد که پیش بینی هایی را میتوان با دقت قابل قبول انجام داد. این معادلات را میتوان بصورت مؤثر برای طراحی هیدرولیک حذف رسوب از ذخایر انرژی آبی جریان رودخانه مورد استفاده قرار داد.
توضیحات: این مقاله انگلیسی در سال 2019 در تیلور و فرانسیس (Taylor and Francis) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T2383 با کیفیت عالی ترجمه گردیده است.
مقاله تأثیر هوش هیجانی بر قضاوت حسابرس
2 | Literature Review and development of hypothesis
2.1 | Audit pressures
A significant body of evidence suggests that audit pressures can lead to dysfunctional behavior. According to DeZoort and Lord (1997), pressure serves as an antecedent to individual stress responses and influences outcomes by providing situational incentives for a specific judgment or decision. Thus, pressure is a major dimension of occupational stress (Larson, 2004). This study investigated the effects of two types of pressure: time budget pressure and client pressure.
2.1.1 | Time budget pressure
Time budget pressure is “a chronic, pervasive type of pressure that arises from limitations on the resources allocable to perform a task” (DeZoort & Lord, 1997, p. 53). It occurs when auditors are assigned limited hours to complete audit procedures. As meeting time budgets is a critical element of auditors' performance evaluations, time budget pressure is a major factor affecting auditors' behavior in both developed and developing countries (Shapeero, Koh, & Killough, 2003). Participants in an Australian auditor experiment in Coram et al. (2003) admitted accepting questionable audit evidence to speed audit testing under time budget pressure. In a subsequent study, Coram et al. (2004) indicated that, in addition to accepting questionable evidence, auditors under high time budget pressure failed to test all items in a selected sample when the level of misstatement risk was low.
2. مروری بر مقالات و ایجاد فرضیهها
2.1. فشارهای حسابرسی
مجموعۀ قابل توجهی از شواهد نشان میدهد که فشارهای حسابرسی میتواند منجر به رفتار ناکارآمدی شود. به گفتۀ DeZoort و Lord (1997)، فشارها مقدمهای برای واکنشهای فردی نسبت به استرس هستند و بر نتایج ارائه شده توسط انگیزههای موقعیتی برای تصمیمات یا قضاوتهای خاص تأثیر میگذارند. بنابراین، فشار بعد مهمی از استرس شغلی است (Larson، 2004). این مطالعه تاثیرات دو نوع فشار را مورد بررسی قرار میدهد: فشار بودجه زمانی و فشار مشتری.
2.1.1. فشار بودجه زمانی
فشار بودجه زمانی، " نوعی فشار مزمن و فراگیر است که از محدودیتهای منابع قابل تخصیص به انجام یک کار ناشی میشود" (DeZoort & Lord، 1997، ص 53). این فشار در زمانی اتفاق می افتد که حسابرسان ساعات محدودی را به انجام روندهای حسابرسی تخصیص میدهند. از آنجاییکه برآورده ساختن شرایط بودجه زمانی یک عامل حیاتی برای ارزیابیهای عملکرد حسابرسان است، فشار بودجه زمانی عامل اصلی تاثیرگذار بر رفتار حسابرسان هم در کشورهای توسعه یافته و هم کشورهای در حال توسعه است (Shapeero، Koh & Killough، 2003). شرکت کنندگان در آزمایش یک حسابرس استرالیایی در مطالعه Coram و همکاران (2003) به پذیرش شواهد حسابرسی مشکوک برای تسریع بررسی حسابرسی تحت فشار بودجه زمانی اقرار کردند. در مطالعه بعدی، Coram و همکاران (2004) نشان دادند که علاوه بر پذیرش شواهد مشکوک، حسابرسان تحت فشار بالای بودجه زمانی نتوانستند همه آیتمها را در زمانیکه میزان ریسک تحریف پایین بود در نمونه انتخابی بررسی کنند.
توضیحات: این مقاله انگلیسی در سال 2015 در نشریه وایلی (Wiley) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T1706 با کیفیت عالی ترجمه گردیده است.
مقاله جایگاه اخلاق و مسئولیت اجتماعی به عنوان ابزاری استراتژیک در تعهد عاطفی کارکنان
Introduction
Globally, small and medium-sized enterprises (SMEs) are recognized for their substantive role in promoting economic development and growth for sustainable development. SMEs contribute to the economic development through jobs creation, increasing income levels and equalizing income distribution. According to The World Bank (2015), SMEs contribute approximately 45 percent of total employment and up to 33 percent of national gross domestic product in emerging economies. A recent study conducted in Malaysia revealed that SMEs dominate Malaysian economy in a similar manner. In 2015, SMECorpration reported that SMEs contributed 65.5 percent of total employment and 17.6 percent of total exports of Malaysia. Despite its significant importance in Malaysia economy, SMEs face multiple challenges. Ahmad and Seet (2009) mentioned that the estimated failure rate of Malaysian SMEs is as high as 60 percent. This indicates that SMEs in Malaysia are in the critical stage and face serious obstacles to stay competitive. To mitigate these challenges, several suggestions are put forth including the incorporation of ethics and social responsibility to increase competitiveness and sustainability.
This research paper is organized into six parts. After this introduction section, relevance literature reviews are presented, followed by research model and hypotheses development. The fourth section discusses the research methodology operationalized to carry out the study. The fifth section shows the research findings before the ending conclusion and implication.
مقدمه
در سطح جهانی، نقش ماهوی شرکت های کوچک و متوسط (SME) در ترویج توسعه اقتصادی و رشد توسعه پایدار به رسمیت شناخته شده است. در واقع، SME ها از طریق ایجاد شغل، افزایش سطح درآمد و یکسان سازی توزيع درآمد به توسعه اقتصادی کمک می کنند. به گفته بانک جهانی (2015)، SME ها در تقریباً 45 درصد کل اشتغال و تا 33 درصد تولید ناخالص داخلی در اقتصادهای نوظهور سهم دارند. یک مطالعه اخیر در مالزی نشان داد که SME ها به شیوه ای مشابه بر اقتصاد مالزی تسط دارند. در سال 2015، SMECorpration گزارش داد که SME ها 65.5 درصد کل اشتغال و 17.6 درصد کل صادرات مالزی را در اختیار دارند. به رغم اهمیت قابل توجه آن در اقتصاد مالزی، SME ها با چالش های متعددی مواجه هستند. احمد و سیت (2009) یادآور شدند که نرخ برآورد شده شکست SME های مالزی تا 60 درصد است. این امر نشان می دهد که SMEs در مالزی در مرحله بحرانی قرار داشته و با موانع جدی برای حفظ رقابت مواجه هستند. برای مقابله با این چالش ها، پیشنهادات متعددی از جمله گنجاندن اخلاق و مسئولیت اجتماعی برای افزایش رقابت و پایداری مطرح شده اند.
مقاله پژوهشی حاضر در شش بخش سازماندهی شده است. پس از بخش مقدمه، بررسی ادبیات مربوطه و در پی آن مدل تحقیق و توسعه فرضیات ارائه شده اند. بخش چهارم به بحث درباره روش عملیاتی تحقیق صورت گرفته در مطالعه حاضر می پردازد. بخش پنجم یافته های تحقیق را قبل از نتیجه گیری پایانی و پیامدهای آن نشان می دهد.
توضیحات: این مقاله انگلیسی در سال 2017 در نشریه امرالد (EmeraldInsight) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T1721 با کیفیت عالی ترجمه گردیده است.
مقاله نظریه سازمانی محاسباتی
Elements in the environment
What exists within the simulation environment? This is a fundamental choice that should be driven by theory. Because organizations are goal-driven entities, organizational learning models usually include some representation of agents, knowledge, and tasks. Although an organization, as a whole, may be said to have some particular piece of information, that information may not be where it can be usefully applied (as defined by tasks). Thus, one common method of evaluating simulated organizational performance is through examining the agreement between three networks (although they may not be represented, explicitly, as networks by the modelers). These three networks are the knowledge network (who knows what), the assignment network (who should do what), and the requirements network (what knowledge is needed for what), as shown in Figure 3.
Not all organizational models include explicit representations of these three objects, but their presence is often implied in the theoretical descriptions of the model.
Agents
Usually, agents are representations of humans, but some simulations allow the set of entities to include nonhuman objects, such as IT systems, and may also include entities at different levels of granularity, an agent representing a single individual may interact with an agent representing a team of individuals. Entities that can affect their own state or the state of others have agency. We refer to these entities as agents. Entities without agency will usually be referred to as objects. Agents may act on objects, but objects do not act directly on agents, although their presence may alter the actions chosen by an agent.
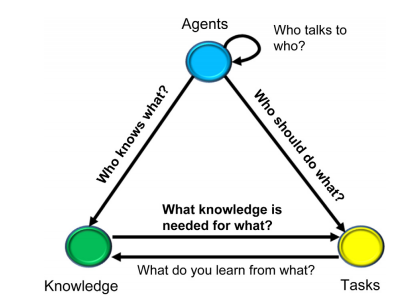 Figure 3 Three common objects within an organizational model are agents, knowledge, and tasks.
Figure 3 Three common objects within an organizational model are agents, knowledge, and tasks.
Agents have bounded rationality, limited access to the state of the larger world in which they inhabit. There are various limitations that can be prescribed to these agents, usually based on the larger theory of interest and drawn from human limitations. Agents may be only able to access state for things they can directly observe. They may forget knowledge they acquired earlier. They may have a limited number of refinement cycles before a decision must be made. Their perception of state may be error prone. Agents should have one or more of these limitations to be useful in a multiagent simulation.
عناصر محیطی
چه چیزی در محیط شبیه سازی وجود دارد؟ این یک انتخاب اساسی است که باید بر اساس نظریه باشد. از آنجاییکه سازمانها واحدهای هدف محوری هستند، مدلهای یادگیری سازمانی بطور معمول شامل برخی بازنماییهای عوامل، دانش و وظایف میباشند. هر چند که یک سازمان به طور کل ممکن است دارای برخی از اطلاعات خاص باشد، اما آن اطلاعات ممکن است در جایی نباشد (همانطور که توسط وظایف تعریف شده) که بتواند بطور سودمندی بکار برده شود. بنابراین، یک روش معمول برای ارزیابی عملکرد سازمانی شبیه سازی شده، از طریق بررسی توافق بین سه شبکه میباشد ( هر چند که آنها ممکن است صراحتاً توسط طراحان به عنوان شبکه نشان داده نشوند). همانطور که در شکل 3 نشان داده شده، این سه شبکه ، عبارتند از شبکه دانش (چه کسی چه چیزی را میداند)، شبکه تخصیص (چه کسی باید چه کاری را انجام دهد)، و شبکه الزامات (چه دانشی برای چه چیزی مورد نیاز است).
همه مدلهای سازمانی شامل بازنماییهای واضحی از این سه هدف نیستند، اما وجود آنها اغلب در توصیفات نظری مدل نشان داده شده است.
عوامل
بطور معمول، این عوامل توصیفی از انسان هستند، اما برخی از محدودیتها وجود دارند که به مجموعه واحدها اجازه میدهند موارد غیرانسانی مانند سیستمهای IT را شامل کنند و ممکن است همچنین شامل واحدهایی در سطوح و درجات مختلف باشند، یک عامل که نشاندهنده یک فرد واحد است ممکن است با عاملی که نشاندهنده تیمی از افراد است تعامل داشته باشد. واحدهایی که میتوانند بر وضعیت خود یا وضعیت دیگران تأثیر بگذارند، دارای سازمان هستند. ما به این واحدها، عامل می گوییم. واحدهایی که بدون سازمان هستند بطور معمول به عنوان اشیاء به آنها اشاره میشود. این عوامل ممکن است به عنوان شیئ عمل کنند اما اشیاء مستقیماً بر آنها تأثیر نمیگذارند، هر چند که وجود آنها ممکن است اقدامات انتخابی توسط یک عامل را تغییر دهد.
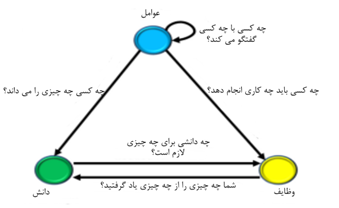
شکل 3. سه چیز عادی در یک مدل سازمانی، عبارتند از عوامل، دانش و وظایف.
این عوامل از منطق محدودی برخوردارند، و دسترسی محدودی به موقعیت جهان بزرگتری که در آن ساکن هستند دارند. محدودیتهای مختلفی وجود دارند که میتوانند به این عوامل نسبت داده شوند که بطور معمول بر مبنای نظریه بزرگتر هستند و از محدودیتهای انسانی برگرفته شدهاند. عوامل ممکن است تنها قادر باشند که به موقعیت اشیاءی که مستقیماً میبینند دسترسی داشته باشند. آنها ممکن است دانشی که قبلاً آموختهاند را فراموش کنند. آنها ممکن است دارای تعداد محدودی از سیکلهای پردازش قبل از اتخاذ یک تصمیم باشند. درک آنها از وضعیت ممکن است درست نباشد. عوامل دارای یک یا چند مورد از این محدودیتها هستند که میتواند در یک شبیه سازی چندعاملی سودمند باشد.
توضیحات: این مقاله انگلیسی در سال 2015 در نشریه الزویر (Elsevier) چاپ شده و سال 1399 در سایت ای ترجمه توسط مترجم کد T1706 با کیفیت عالی ترجمه گردیده است.