
پیش بینی لینک توسط تجزیه ماتریس
چکیده
ما پیشنهاد می کنیم که مسئله پیش بینی لینک در گراف ها، با استفاده از یک رویکرد تجزیه ماتریس تحت نظارت حل شود. این مدل می تواند قابلیت های نهان را از ساختار توپولوژی یک گراف (بدون جهت) یاد بگیرد و نشان داده است که عملکرد بهتری نسبت به نمرات مشهور نظارت نشده دارد. ما نشان می دهیم که چگونه این قابلیت های نهان ممکن است با قابلیت های ضمنی و اضافی مربوط به گره ها و یال ها ترکیب شوند، که در نهایت این ترکیب منجر به بالا رفتن عملکرد خواهد شد و نسبت به استفاده منحصر به فرد از یک نوع قابلیت بهتر است. در نهایت ما یک رویکرد نوین را برای برطرف کردن مسئله عدم تعادل ارائه می کنیم که این مسئله در پیش بینی به وسیله بهینه سازی مستقیم برای یک زیان رتبه بندی، رایج می باشد. مدل ما به وسیله مقیاس ها و گرادیان نزولی تصادفی بهینه سازی می شود. نتایج این رویکرد بر روی چندین پایگاه داده نشان می دهد که مدل ما دارای کارایی می باشد.
1. مسئله پیش بینی لینک
پیش بینی لینک مسئله ای برای پیش بینی کردن حضور یا غیاب یال های بین گره ها در یک گراف می باشد. دو نوع از پیش بینی لینک وجود دارند: (1) ساختاری، به طوری که ورودی یک گراف مشاهده شده جزئی است، و ما می خواهیم وضعیت یال ها را برای جفت های مشاهده نشده گره ها پیش بینی کنیم، و (2) گذرا، که ما دارای یک دنباله از گراف های مشاهده شده در گام های زمانی مختلف به عنوان ورودی هستیم، و هدف ما پیش بینی وضعیت گراف در گام زمانی بعدی است. هر دو مسئله در مثال های کاربردی مانند پیش بینی تعاملات بین جفت های پرتئین ها و سفارش کردن دوستان در یک شبکه اجتماعی، دارای اهمیت هستند. این مطالعه بر روی مسئله پیش بینی لینک ساختاری تمرکز خواهد کرد، و سپس، ما از اصطلاح پیش بینی لینک استفاده می کنیم تا نسخه ساختاری از این مسئله را بیان کنیم.
6. نتیجه گیری
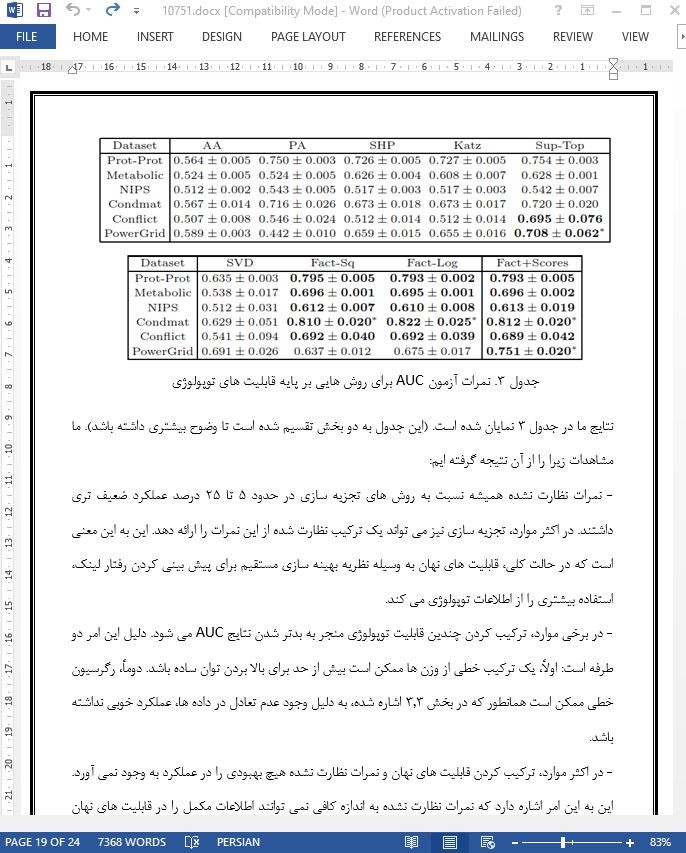
در این مقاله، ما یک مدلی را معرفی کردیم که تجزیه سازی ماتریسی را توسعه می دهد تا مسائل مربوط به پیش بینی لینک ساختاری را در گراف ها (شاید گراف های جهت دار) حل کند. مدل ما قابلیت های نهان را با قابلیت های عینی دیگر برای گره ها و یال ها در این گراف ترکیب می کند. این مدل با استفاده از زیان رتبه بندی اجرا شد تا بتوانیم بر مشکل عدم تعادل در داده که در این گونه داده ها رایج است، چیره شویم. این عمل با استفاده از روش گرادیان نزولی تصادفی نیز صورت گرفت و مقیاس این مدل را توسعه دادیم تا برای گراف های بزرگ نیز قابل استفاده باشد. در عمل، ما پی بردیم که رویکرد قابلیت نهان نسبت به بسیاری از نمرات نظارت نشده مشهور مانند Katz و Adamic-Adar عملکرد بسیار بهتری دارد. ما پی بردیم که این امکان وجود دارد تا قابلیت های نهان را با استفاده از قابلیت های عینی به دست آوریم، که این کار باعث افزایش عملکرد کار می شود. در نهایت، ما مشاهده کردیم که بهینه سازی کردن با استفاده از یک زیان رتبه بندی می تواند عملکرد AUC را به میزان 10 درصد نسبت به استفاده کردن از زیان استاندارد رگرسیونی افزایش دهد. در کل، در این شش مجموعه داده ها که دارای زمینه ها و حوزه های مختلفی بودند، برخی از آن دارای اطلاعات کناری بودند و برخی نبودند، روش پیشنهادی ما (Fact-BLR-Rank موجود در جدول 5 بر روی داده هایی که دارای اطلاعات کناری هستند، و مدل Fact-Rank بر روی دیگر داده ها) دارای عملکرد AUC برابر یا حتی بهتری در بین روش های پیشنهاد شده دیگر در این زمینه می باشد.
Abstract
We propose to solve the link prediction problem in graphs using a supervised matrix factorization approach. The model learns latent features from the topological structure of a (possibly directed) graph, and is shown to make better predictions than popular unsupervised scores. We show how these latent features may be combined with optional explicit features for nodes or edges, which yields better performance than using either type of feature exclusively. Finally, we propose a novel approach to address the class imbalance problem which is common in link prediction by directly optimizing for a ranking loss. Our model is optimized with stochastic gradient descent and scales to large graphs. Results on several datasets show the efficacy of our approach.
1 The Link Prediction Problem
Link prediction is the problem of predicting the presence or absence of edges between nodes of a graph. There are two types of link prediction: (i) structural, where the input is a partially observed graph, and we wish to predict the status of edges for unobserved pairs of nodes, and (ii) temporal, where we have a sequence of fully observed graphs at various time steps as input, and our goal is to predict the graph state at the next time step. Both problems have important practical applications, such as predicting interactions between pairs of proteins and recommending friends in social networks respectively. This document will focus on the structural link prediction problem, and henceforth, we will use the term “link prediction” to refer to the structural version of the problem.
6 Conclusion
In the paper, we proposed a model that extends matrix factorization to solve structural link prediction problems in (possibly directed) graphs. Our model combines latent features with optional explicit features for nodes and edges in the graph. The model is trained with a ranking loss to overcome the imbalance problem that is common in link prediction datasets. Training is performed using stochastic gradient descent, and so the model scales to large graphs. Empirically, we find that the latent feature approach significantly outperforms popular unsupervised scores, such as Adamic-Adar and Katz. We find that it is possible to learn useful latent features on top of explicit features, which can give better performance than either model individually. Finally, we observe that optimizing with a ranking loss can improve AUC performance by around 10% over a standard regression loss. Overall, on six datasets from widely different domains, some possessing side information and others not, our proposed method (FactBLR-Rank from Table 5 on datasets with side information, Fact-Rank on the others) has equal or better AUC performance (within statistical error) than previously proposed methods.
چکیده
1. مسئله پیش بینی لینک
1.1 چالش هایی در پیش بینی لینک
1.2- سهم ما در این مدل
1.3- تعریف مسئله و علامت ها
2. مدل های موجود برای پیش بینی لینک
2.1- آیا روش های موجود می توانند پاسخگوی چالش ها در پیش بینی لینک باشند؟
3- بسط دادن تجزیه ماتریس برای پیش بینی لینک
3.1 – چرا رویکرد تجزیه سازی قابل استفاده است؟
3.2 – ما چگونه می توانیم قابلیت های نهان و ضمنی را با هم ترکیب کنیم؟
3.3- چگونه بر مشکل عدم تعادل غلبه کنیم؟
3.4- مدل نهایی
4- طرح آزمایشی
5. نتایج آزمایش
6. نتیجه گیری
Abstract
1 The Link Prediction Problem
1.1 Challenges in Link Prediction
1.2 Our Contributions
1.3 Problem Definition and Notation
2 Existing Link Prediction Models
2.1 Do Existing Methods Meet the Challenges in Link Prediction?
3 Extending Matrix Factorization for Link Prediction
3.1 Why is the Factorization Approach Appealing?
3.2 How Do We Combine Explicit and Latent Features?
3.3 How Do We Overcome Imbalance?
3.4 The Final Model
4 Experimental Design
5 Experimental Results
6 Conclusion
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه