
چارچوب غنی سازی تحلیل انبار داده با سیستم های پرسش و پاسخ
چکیده
برنامههای هوش تجاری (BI) برای کاربران خود امکان جستجو، درک و تحلیل دادههای موجود در سازمان های آنها را ایجاد میکند تا دانش مفید کسب کرده و بنابراین تصمیمات راهبردی بهتری اخذ نمایند. هسته برنامه BI انبار داده (DW) است که چندین منبع داده ساختاری ناهمگن را در یک مخزن مشترک داده مجتمعسازی میکند. هرچند، توافق مشترکی وجود دارد که نسل بعدی برنامههای BI باید نه تنها داده را از منابع داخلی آن مد نظر داشته باشند، بلکه باید داده های منابع خارجی مختلف را نیز در نظر بگیرند (مثلا Big Data، وبلاگ ها، شبکههای اجتماعی و غیره) که در آن اطلاعات بهروزرسانی مرتبط رقبا میتواند اطلاعات اساسی برای تصمیمگیری درست مهیا نماید. این داده خارجی معمولا از طریق موتورهای جستجوی وب سنتی حاصل میشود که تلاش قابل توجهی از جانب کاربران به منظور تحلیل اطلاعات برگشتی و ورود این اطلاعات به برنامه BI را میطلبد. در این مقاله پیشنهاد مجتمعسازی داده ساختاری داخلی DW با داده غیرساختاری خارجی حاصل از تکنیکهای پرسش و پاسخ (QA) را پیشنهاد میکنیم. این مجتمعسازی از طریق ارائه داده برگشتی DW و سیستمهای QA در داشبورها محقق میشود که به کاربر اجازه میدهد هر دو نوع داده را مدیریت نماید. به علاوه، نتایج QA از طریق مخزن DW جدید به شیوه پایدار نگهداری میشوند تا مقایسه نتایج حاصله با سوالات مختلف یا حتی سوال یکسان با تاریخهای مختلف تسهیل گردد.
1. مقدمه
و انگیزه امروزه اطلاعات دردسترس که اساسا از طریق وب حاصل میشوند، به صورت پیشرونده در حال افزایش هستند. براساس گزارش گروه گارتنر 2011 (گزارش گروه گارتنر، 2011)، حجم اطلاعات در سراسر دنیا به صور سالانه با سرعت حداقل 59 درصد در حال رشد است. بنابراین اطلاعاتی که می تواند به صورت بالقوه توسط شرکت به کار رود به شیوه پیشرونده در حال افزایش است. این اطلاعات از طریق هر کامپیوتری قابل دسترسی است و درصد مهمی از این اطلاعات مثل مواردی که شبکه های اجتماعی (مثلا توئیتر یا فیس بوک ) مهیا میکنند، غیرساختاری و متنی است. دادههای ساختاری از پیش تعیین شده، به خوبی تعریف شده و معمولا توسط برنامههای هوش تجاری (BI) براساس انبار داده (DW) مدیریت میشوند که مخزن دادههای قدیمی جمعآوری شده از پایگاههای داده عملیاتی ناهمگن یک سازمان میباشند. منفعت اصلی سیستم DW این است که بدون توجه به منبع مدل داده مشترکی برای همه دادههای شرکت مورد نظر مهیا می کند تا گزارش و تحلیل دادههای داخلی سازمان را تسهیل نماید. هرچند، توافق گسترده ای در این زمینه وجود دارد که داده داخلی سازمان برای تصمیم گیری درست کافی نیست و این مسئله در بازارهای بسیار پویا و متغیر جاری که در آن اطلاعات از رقبا و مشتریان/کاربران برای این تصمیمات بسیار مقتضی است، برجستهتر جلوه مینماید. بنابراین هدف اصلی ساختارهای DW سنتی این است که نمیتوانند با دادههای غیرساختاری سروکار داشته باشند.
6. نتیجه گیری و تحقیق آینده
در این مقاله چارچوب کاملی با هدف مجتمعسازی داده ساختاری داخلی یک تشکیلات اقتصادی با داده غیرساختاری خارجی را پیشنهاد کردهایم. این چارچوب در سناریوی فروش محصول الکترونیکی تست شده که در آن بخش بازاریابی تشکیلات اقتصادی میخواهد فروش را تحلیل نماید تا مشخصه های محتمل مفید برای تبلیغات جدید را با دسترسی به دادههای خارجی و کسب آنها از رقبای وب کسب نماید. در این سناریوی موردی مزیتهای پیشنهاد ما نشان داده شده است. بویژه مجموعهای از 97799 صفحه وب محصولات الکترونیکی بررسی شده و توسط سیستم پرسش و پاسخ (QA) با یک سوال ویژه به آنها دسترسی یافتهایم. این سوال در سیستم DW با اطلاعات داخلی تشکیلات اقتصادی مطرح شده و اطلاعات گزارششده توسط سیستمهای QA و DW از طریق داشبوردی به کاربر ارائه شده که به تصمیمگیرندگان کمک میکند اعداد داخلی را فورا با اعداد خارجی رقبا مقایسه کرده و بدین وسیله تصمیمات راهبردی سریعی براساس دادههای غنیتر کسب نمایند. به علاوه، نتایج QA از طریق مجموعه DW جدید به روش پایدار ذخیره میشوند تا مقایسه نتایج کسب شده با سوالات مختلف یا حتی سوال مشابه با تاریخهای متفاوت تسهیل گردد.
Abstract
Business Intelligence (BI) applications allow their users to query, understand, and analyze existing data within their organizations in order to acquire useful knowledge, thus making better strategic decisions. The core of BI applications is a Data Warehouse (DW), which integrates several heterogeneous structured data sources in a common repository of data. However, there is a common agreement in that the next generation of BI applications should consider data not only from their internal data sources, but also data from different external sources (e.g. Big Data, blogs, social networks, etc.), where relevant update information from competitors may provide crucial information in order to take the right decisions. This external data is usually obtained through traditional Web search engines, with a significant effort from users in analyzing the returned information and in incorporating this information into the BI application. In this paper, we propose to integrate the DW internal structured data, with the external unstructured data obtained with Question Answering (QA) techniques. The integration is achieved seamlessly through the presentation of the data returned by the DW and the QA systems into dashboards that allow the user to handle both types of data. Moreover, the QA results are stored in a persistent way through a new DW repository in order to facilitate comparison of the obtained results with different questions or even the same question with different dates.
1 Introduction and motivation
Nowadays, the available information, mainly through the Web, is progressively increasing. According to the 2011 Gartner Group report (Gartner Group report 2011), worldwide information volume is growing annually at a minimum rate of 59% annually. Thus, the information that could be potentially used by a company is progressively increasing. This information is accessible from any computer, and an important percentage of this information is unstructured and textual, such as the one generated by Social Networks (e.g. Twitter or Facebook). The structured data is predetermined, well defined, and usually managed by traditional Business Intelligence (BI) applications, based on a Data Warehouse (DW), which is a repository of historical data gathered from the heterogeneous operational databases of an organization (Inmon 2005; Kimball and Ross 2002). The main benefit of a DW system is that it provides a common data model for all the company data of interest regardless of their source, in order to facilitate the report and analysis of the internal data of an organization. However, there is a wide consensus in that the internal data of organizations to take right decisions is not enough, even more in current highly dynamic and changing markets where information from competitors and clients/users is extremely relevant for these decisions. Thus, the main disadvantage of traditional DW architectures is that they cannot deal with unstructured data (Rieger et al. 2000).
6 Conclusions and future research
In this paper, we have proposed a full framework with the aim to integrate the internal structured data of an enterprise, with external unstructured data. This framework has been tested on an Electronic Product Sales scenario, in which the enterprise’s marketing department wants to analyze sales to identify possible features useful for making new promotions by accessing and acquiring external data from the Web competitors. In this case scenario, the advantages of our proposal have been shown. Specifically, a set of 97,799 Web pages of electronic products have been crawled and accessed by a Question Answering (QA) system on a specific question. This question has been also posed to a DW system with the internal information of the enterprise, and the information returned by both the QA and the DW systems has been presented to the user through a dashboard that helps the decision makers to compare instantaneously internal figures with figures from competitors, thereby allowing taking quick strategic decisions based on richer data. Moreover, the QA results are stored in a persistent way through a new DW repository in order to facilitate comparison of the obtained results with different questions or even the same question with different dates.
چکیده
1. مقدمه و انگیزه
2. کار مرتبط
1.2. سهم پیشنهاد ما در کار پیشین
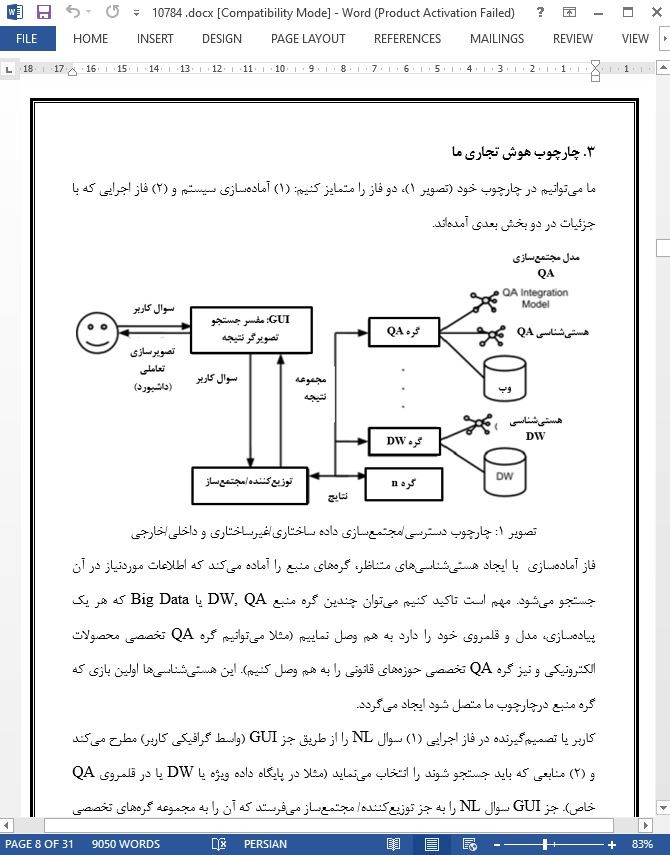
3. چارچوب هوش تجاری ما
1.3. فاز آمادهسازی
2.3. فاز اجرایی
4. سناریوی موردی
1.4. توصیف سناریوی موردی
2.4. استفاده از پیشنهاد ما در سناریوی موردی
5. ارزشیابی
1.5. توصیف سیستم QA
2.5. نتایج آزمایش روی سناریوی فروش محصول الکترونیکی
6. نتیجه گیری و تحقیق آینده
Abstract
1 Introduction and motivation
2 Related work
2.1 Contributions of our proposal to previous work
3 Our business intelligence framework
3.1 Setup phase
3.2 Running phase
4 A case scenario
4.1 The case scenario description
4.2 The application of our proposal on the case scenario
5 Evaluation
5.1 Description of the QA system
5.2 Experiment results on the electronic product sales scenario
6 Conclusions and future research
- اصل مقاله انگلیسی با فرمت ورد (word) با قابلیت ویرایش
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه