
شناسایی اسپمرهای اجتماعی از دیدگاه های متعدد
چکیده
شبکه های اجتماعی آنلاین تبدیل به پلتفرم های پرطرفدار برای اسپمرها جهت پخش محتوی و لینک های مخرب شده اند. روش های بهینه سازی موجود نوین اساسا از یک نوع اطلاعات ایجاد شده از سوی کاربر (برای مثال دیدگاه مجزا) جهت یادگیری یک مدل طبقه بندی برای شناسایی اسپمرها استفاده می کنند. به دلیل تنوع و گوناگونی استراتژیهای اسپمرها، رفتار اسپمرها ممکن است به طور کامل تنها به وسیله اطلاعات دیدگاه مجزا شناسایی نشود. برای مقابله با این چالش، ابتدا به لحاظ آماری اهمیت در نظرگیری اطلاعات دیدگاه متعدد را برای مسئولیت تشخیص اسپمر بروی مجموعه داده بزرگ توئییتر در جهان حقیقی تجزیه و تحلیل می کنیم. بر این اساس، یک چارچوب تشخیص اسپمر اجتماعی تعمیم یافته به وسیله ادغام مشترک اطلاعات دیدگاههای متعدد و یک عبارت ساماندهی اجتماعی نوین به یک مدل طبقه بندی پیشنهاد می کنیم. به جهت حفظ تمامیت (کامل بودن) مجموعه داده اصلی و تشخیص اسپمرهای زیاد توسط روش پیشنهادی، یک راهکار ساده برای پوشش داده های ناموجود (از دست رفته) برای هر دیدگاه معرفی می کنیم. نتایج تجربی درباره مجموعه داده توئییتر در جهان حقیقی نشان می-دهند که روش پیشنهادی ما دارای عملکردی بسیار بهتر نسبت به روش های موجود می باشد. واژگان کلیدی: تشخیص اسپمر اجتماعی، یادگیری چنددیدگاهی، عبارت ساماندهی اجتماعی.
1-مقدمه
شبکه های اجتماعی آنلاین (OSNها)، همانند توئییتر و فیسبوک، تبدیل به پلتفرم های پرطرفدار برای انتشار و اشتراک اطلاعات شده اند [1]. متاسفانه، اسپمرهای اجتماعی از مزایای این پلتفرمها برای پخش کلاهبرداریهای فیشینگ ، انتشار محتوی و لینکهای مخرب و پخش اطلاعات مالی(کالایی) سود می برند [2 تا 4]. براساس مطالعه انجام شده توسط نکس گیت [5] ، تعداد اسپم های اجتماعی از ژانویه تا ژولای 2013 برابر با 355 درصد رشد داشته است که بدین معنی است که از هر دویست پیام اجتماعی یکی از آنها اسپم بوده است و 15 درصد تمام پیام های اسپم حاوی URLهای دارای ارتباط (لینک) با وبسایتهای پرخطر می باشند. اسپمرها بسیار پیچیده هستند و نتیجه گرفته شده است که آنها استراتژیهای اسپمینگ را به طور نامنظم تغییر می دهند و تلاش می کنند تا به عنوان کاربران مشروع مخفی شوند. به علاوه، به جهت افزایش تاثیر خود و برای اینکه ناشناخته باقی بمانند، اسپمرها با یکدیگر برای ساخت جوامع (اجتماعات) جنائی تبانی می کنند [6]. رفتار مخرب اسپمرها نه تنها مانع توسعه گسترده OSNها شده است [7] بلکه همچنین امنیت اطلاعات و حریم خصوصی شحصی را تهدید کرده است [8]. بنابراین، ضروری است تا روشهای تشخیص اسپمر کارآمد و نوین برای توسعه سیستم های اجتماعی طراحی کرد.
7- نتیجه گیری
در این مقاله، یک چارچوب تعمیم یافته با سود بردن از مزایای اطلاعات دیدگاههای متعدد برای شناسایی اسپمرهای اجتماعی پیشنهاد کردیم. با تفاوت از روشهای موجود که اطلاعات دیدگاههای مجزا (تک دیدگاهی) استفاده می کنند، روش پیشنهادی MVSDما اطلاعات اجتماعی متعدد را براساس NMFبا مدل طبقه بندی به یک مدل یادگیری ادغام می کند. به علاوه، یک راهکار ساده برای تکمیل داده های ناموجود دیدگاههای مختلف جهت پیش بینی کاربران زیاد و بهبود عملکرد تشخیص اسپمرها معرفی کردیم. نتایج تجربی بروی یک مجموعه داده حقیقی نشان می دهند که MVSDبه عملکرد تشخیص بهتری نسبت به روشهای موجود حتی با تعداد کوچک داده های آموزش دست می یابد.
Abstract
Online social networks have become popular platforms for spammers to spread malicious content and links. Existing state-of-the-art optimization methods mainly use one kind of user-generated information (i.e., single view) to learn a classification model for identifying spammers. Due to the diversity and variability of spammers' strategies, spammers' behavior may not be completely characterized only by single view's information. To tackle this challenge, we first statistically analyze the importance of considering multiple view information for spammer detection task on a large real-world Twitter dataset. Accordingly, we propose a generalized social spammer detection framework by jointly integrating multiple view information and a novel social regularization term into a classification model. To keep the completeness of the original dataset and detect more spammers by the proposed method, we introduce a simple strategy to fill the missing data for each view. Experimental results on a real-world Twitter dataset show that the proposed method outperforms the existing methods significantly.
1. Introduction
Online social networks (OSNs), such as Twitter and Facebook, have become popular platforms to disseminate and share information [1]. Unfortunately, social spammers take advantage of those platforms to spread phishing scams, publish malicious content and links, and promote commodity information [2–4]. According to a study by Nexgate [5], the number of social spam grew more than 355% from January to July of 2013, which means that one in two hundred social messages was a spam, and 15% of all spams contained URLs linking to risky websites. Spammers are so sophisticated and concealed that they change spamming strategies irregularly and try to disguise as legitimate users. Moreover, to increase their influence and be undetected, spammers collude with each other to construct the criminal communities [6]. The malicious behavior of spammers has not only hindered the OSNs' development largely [7], but also threatened information security and personal privacy [8]. Therefore, it is crucial to design effective and novel spammer detection methods for the development of social systems.
7. Conclusion
In this paper, we propose a generalized framework by taking advantage of multiple views' information for social spammer detection. Different from the existing methods that utilize single view's information, the proposed method MVSD integrates multiple social information based on NMF with classification model into a learning model. Moreover, we introduce a simple strategy to complement the missing values of different view to predict more users, thus improving the performance of detection spammers. Experimental results on a real dataset show that MVSD obtains the better detection performance than the existing methods even with a small number of training data.
چکیده
1-مقدمه
2- آنالیز داده ها
2-1- مجموعه داده
2-2- اهمیت اطلاعات دیدگاه متعدد
2-3- اهمیت تکمیل اطلاعات
3- تعریف مسئله
4- یادگیری چنددیدگاهی برای تشخیص اسپمر اجتماعی
4-1- یادگیری چنددیدگاهی
4-2- ساماندهی اجتماعی
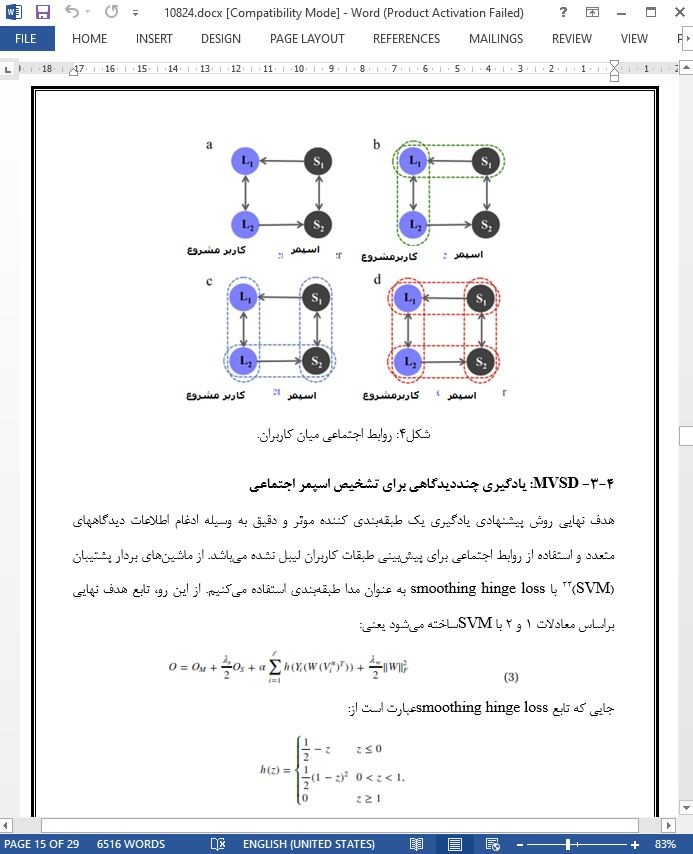
4-3- MVSD: یادگیری چنددیدگاهی برای تشخیص اسپمر اجتماعی
4-4- بهینه سازی
5- آزمایشات
5-1- اصول مبنا و ستاپ تجربی
5-2- ارزیابی عملکرد
5-3- ارزیابی یادگیری چنددیدگاهی
5-4- ارزیابی ساماندهی اجتماعی
5-5- ارزیابی تکمیل اطلاعات
6- کارهای مرتبط
7- نتیجه گیری
ABSTRACT
1. Introduction
2. Data analysis
2.1. Dataset
2.2. Importance of multiple view information
2.3. Significance of information complement
3. Problem definition
4. Multi-view learning for social spammer detection
4.1. Multi-view learning
4.2. Social regularization
4.3. MVSD: multi-view learning for social spammer detection
4.4. Optimization
5. Experiments
5.1. Baselines and experimental setup
5.2. Performance evaluation
5.3. Multi-view learning evaluation
5.4. Social regularization evaluation
5.5. Information complement evaluation
6. Related work
7. Conclusion
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه