
زبان شناسی اجتماعی و برنامه نويسی
چكيده
اين مقاله به كاربرد تكنيكهاي يادگيري ماشين در تحليل برنامههاي كامپيوتري، با هدف كسب اطلاعات درباره جنسيت نويسنده ميپردازد. پژوهشهاي موجود اندكي به رابطه ميان زبانشناسي و برنامهنويسي ميپردازند: با اين حال، در بسياري از زمينههايي كه زبان در آن تحليل ميشود، ميتوان اطلاعات مهمي درباره كاربران آن زبان به دست آورد، كه به صفات يا شيوهي كدنويسي مربوط ميشود. در اين پروژه از اجراي متن باز الگوريتمهاي يادگيري ماشين، به طور خاص نزديكترين همسايه (K*) ، درخت تصميم (J48)، و طبقهبندي كننده بيز (Na¨ıve Bayes) استفاده كردهايم. اين الگوريتمها بر روي برنامههاي C++ ، كه با اطلاعات زبانشناسي اجتماعي برنامهنويسان مرتبط بودند، استفاده شدند. هدف ما، طبقهبندي اين برنامهها بر اساس جنسيت نويسندگان آنها بود. همانطور كه از يافتههاي اوليه آشكار است، توانستهايم به دقت 72.3 درصد، حساسيت 72 درصد، و معيار f-measure 71.9 درصد دست بيابيم، كه نشان ميدهد ميتوانيم جنسيت نويسندگان برنامههاي C++ را پيشبيني كنيم.
I. مقدمه و هدف
در زمينهي زبانشناسي اجتماعي، اين يك امر جاافتاده است كه تفاوتهاي فردي در استفاده از زبان درون يك جامعه، ميتوانند بر عوامل اجتماعي تاثير گذاشته، يا نمايانگر آنها باشد. متغيرهاي زبانشناختي، با متغيرهاي جامعهشناختي مانند سن، جايگاه اجتماعي-اقتصادي، جنسيت، نژاد، و ناحيه همبستگي دارند. 1 با اين حال، محققين اندكي از اين تحليل در زمينه برنامهنويسي كامپيوتري استفاده كردهاند. به همين دليل است كه ما به دنبال پاسخ به اين پرسش هستيم: آيا عوامل اجتماعي بر نوشتن برنامههاي C++ تاثير ميگذارند؟ براي پاسخ به اين سوال، اول در اينجا گزارشي از تلاشهايمان براي طبقهبندي برنامههايC++ بر اساس جنسيت برنامهنويسان، ارايه ميكنيم.
VII. نتيجهگيري و پژوهشهاي آتي
در اين پروژه، ما برنامههاي كامپيوتري را بر اساس جنسيت برنامهنويسان طبقه بندي كرديم. از مجموعهدادهاي استفاده كرديم كه متشكل بود از برنامه هاي C++ نوشتهشده توسط برنامه نويسان زن و مرد. سه مدل طبقهبندي ايجاد كرديم: نزديكترين همسايه (K*)، درخت تصميم (J48) و طبقهبندي كنندهي بيز (Naïve Bayes). ما به اين نتيجه رسيديم كه براي مجموعهداده محدودي از برنامههاي C++ ، ميتوان از يادگيري ماشين براي تمييز بين برنامهنويسان زن و مرد استفاده كرد. ما توانستيم به دقت 72.3%، حساسيت 72%، و f-measure 71.9% دست بيابيم، كه نشان ميدهد عوامل اجتماعي مانند جنسيت در استفاده از زبان برنامه نويسي C++ بازنمود پيدا ميكنند.
Abstract
This paper focuses on the use of machine learning techniques for the analysis of computer programs in order to acquire information about an author's gender. There are few existing studies that address the relationship between linguistics and programming; however, in many areas where language is analyzed it is possible to mine important information about the users of that language associated with set of attribute or coding style. In this work we use open source implementations of machine learning algorithms, specifically, nearest neighbor (K*), decision tree (J48), and Bayes classifier (Naïve Bayes). These algorithms were applied to C++ programs which were associated with sociolinguistic information about the program authors. Our goal was to classify the programs according to the gender of the author. As indicated by our initial results we have been able to achieve precision of 72.3%, recall of 72%, and f-measure of 71.9% which demonstrates that we can predict the gender of the authors of C++ programs.
I. INTRODUCTION AND MOTIVATION
IN the field of sociolinguistics it is known that individual differences in the use of a language within a society can affect or reflect social factors. Linguistic variables correlate with social variables such as age, socio-economic status, gender, ethnicity, and region to create sociolinguistic variation [1]. However, very few researchers have applied this analysis to the field of computer programming. We are thus interested in answering the following question: do social factors impact the development of C++ programs? To begin to answer this question here we report on our efforts to categorize C++ programs based on the gender of the programmers.
VII. CONCLUSION AND FUTURE WORK
In this work, we categorized computer programs on the basis of the gender of the computer programmers. We used dataset composed of C++ programs written by male and female programmers. We developed three classification models: nearest neighbor (K∗ ), decision tree (J48), and Bayes classifier (Na¨ıve Bayes). We concluded that for a limited dataset of C++ programs it is possible to utilize machine learning techniques to differentiate between male and female programmers. We are able to achieve 72.3% of precision, 72% of recall, and 71.9% of f-measure which established that social factors such as gender are reflected in the use of the C++ programming language.


(جهت بزرگ نمایی روی عکس کلیک نمایید)
چكيده
I. مقدمه و هدف
II. زمينه
الف. زبانشناسي اجتماعي
ب. يادگيري ماشين
ج. الگوريتمهاي طبقهبندي
د. روش اعتبارسنجي ضربدري
ه. معيارهاي ارزيابي
III. پژوهشهاي مرتبط
الف. زبانشناسي نرمافزاري
ب. تعيين جنسيت
ج. تحليل تاليف
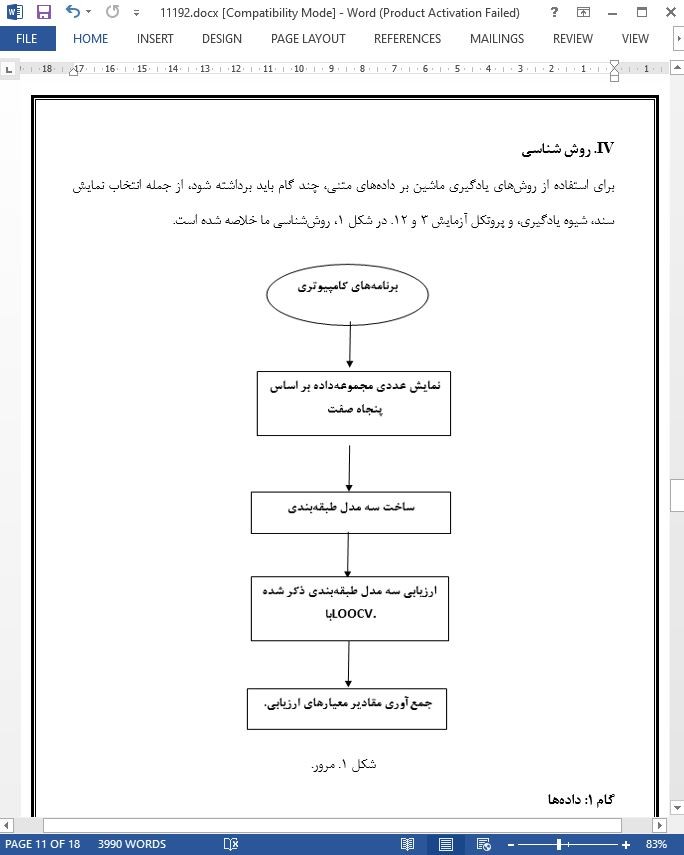
IV. روش شناسي
v. نتايج و بحث
VI. محدوديتها
VII. نتيجهگيري و پژوهشهاي آتي
Abstract
I. INTRODUCTION AND MOTIVATION
II. BACKGROUND
A. Sociolinguistics
B. Machine Learning
C. Classification Algorithms
D. Cross Validation Technique
E. Evaluation Metrics
III. RELATED WORK
A. Software Linguistics
B. Gender Identification
C. Authorship Analysis
IV. METHODOLOGY
V. RESULTS AND DISCUSSION
VI. LIMITATIONS
- اصل مقاله انگلیسی با فرمت ورد (word) با قابلیت ویرایش
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه