
مطالعات تجربی یک رویکرد پیش پردازش داده دو مرحله ای برای پیش بینی خطای نرم افزار
چکیده
پیش بینی خطای نرم افزار یک اقدام ارزشمند در اطمینان از کیفیت نرم افزار می باشد تا به بهترین شکل منابع آزمایش محدود را تخصیص دهد. طبقه بندی یکی از روش های موثر برای پیش بینی خطای نرم افزار می باشد. مدل های طبقه بندی براساس مجموعه داده های به دست آمده به وسیله کاوش مخازن داده گذشته نرم افزار آموزش داده شده اند. در این مقاله، ما یک رویکرد پردازش داده دو مرحله ای نوین پیشنهاد کردیم که انتخاب ویژگی و کاهش نمونه را شامل می شود. خصوصا، در مرحله انتخاب ویژگی، ما در ابتدا آنالیر ارتباط را اجرا می کنیم و سپس یک روش خوشه بندی مبتنی بر آستانه به نام الگوریتم خوشه بندی مبتنی بر آستانه نوین را برای اجرای کنترل افزونگی پیشنهاد می¬کنیم. در مرحله کاهش نمونه، زیرنمونه گیری برای حفظ تعادل بین نمونه¬های معیوب و غیرمعیوب به کار گرفته شده است. در مطالعات تجربی، ما مجموعه داده ها را از پروژه های نرم افزاری جهان حقیقی همانند ناسا و Eclipse انتخاب کردیم. سپس ما رویکرد خود را با برخی روشهای پایه مقایسه کردیم و فاکتورهای تاثیرگذار بیشتر در رویکرد ما مورد بررسی قرار گرفتند. نتیجه نهایی اثربخشی (کارایی) رویکرد ما را نشان می دهد و یک راهنمایی برای رسیدن به پیش پردازش داده مقرون به صرفه در هنگام استفاده از رویکرد دو مرحله ای ما فراهم می کند.
1-مقدمه
پیش بینی خطای نرم افزار (SFP) یک موضوع تحقیق داغ در قلمرو مهندسی نرم افزار می باشد (1 تا 17). این می¬تواند منابع آزمون (آزمایش) محدود را به طور موثر به وسیله پیش بینی استعداد خطای ماژولهای نرم افزار تخصیص دهد. طبقه بندی یکی از روشهای غالبا استفاده شده برای پیش بینی خطای نرم افزار می باشد. مسئولیت اصلی آن، طبقه بندی ماژولها، ارائه شده توسط یک مجموعه از متریکهای نرم افزار، به دو کلاس می باشد: مستعد خطا (FP) یا غیرمستعد خطا (NFP). برای یک مدل طبقه بندی خاص، طبقه بندی کننده باید از قبل براساس داده های آموزش به دست آمده از کاوش مخازن داده پیشین نرم افزار (تاریخچه نرم افزار) همانند تغییر لوگها در مدیریت پیکربندی نرم افزار، گزارش باگها (اشکالات) در سیستم ردیابی باگ و ایمیل های توسعه دهندگان، آموزش داده شود.
6- نتیجه گیری
در این مطالعه، ما رویکرد پیش پردازش داده دو مرحله ای را ارائه می کنیم، که شامل هر دو انتخاب ویژگی و کاهش نمونه می باشد، تا کیفیت مجموعه داده های نرم افزار استفاده شده توسط مدلهای طبقه بندی برای پیش بینی خطای نرم افزار، بهبود دهیم. در مرحله انتخاب ویژگی، ما یک الگوریتم نوین پیشنهاد می کنیم که شامل هر دو آنالیز ارتباط و کنترل افزونگی می باشد. در مرحله کاهش نمونه، ما زیرنمونه گیری تصادفی را برای حفظ تعادل بین نمونه های معیوب و غیرمعیوب به کار می بریم. ما به طور سیستماتیک آزمایشهایی را براساس مجموعه داده های Eclipse و ناسا طراحی می کنیم و رویکرد خود را با دیگر روشهای پیش پردازش داده به طور رایج استفاده شده مقایسه می کنیم. نتایج پتانسیل رویکرد ما در ارتقاء عملکرد پیش بینی طبقه بندی کننده های ساخته شده بعد از آن را نشان می دهند.
Abstract
Software fault prediction is a valuable exercise in software quality assurance to best allocate limited testing resources. Classification is one of the effective methods for software fault prediction. The classification models are trained based on the datasets obtained by mining software historical repositories. However, the performance of the models depends on the quality of datasets. In this paper, we propose a novel two-stage data preprocessing approach which incorporates both feature selection and instance reduction. Specifically, in the feature selection stage, we first perform relevance analysis, and then propose a threshold-based clustering method, called novel threshold-based clustering algorithm, to conduct redundancy control. In the instance reduction stage, we apply random under-sampling to keep the balance between the faulty and non-faulty instances. In empirical studies, we chose datasets from real-world software projects, such as Eclipse and NASA. Then we compared our approach with some classical baseline methods, and further investigated the influencing factors in our approach. The final results demonstrate the effectiveness of our approach, and provide a guideline for achieving cost-effective data preprocessing when using our two-stage approach.
I. INTRODUCTION
SOFTWARE fault prediction (SFP) is a hot research topic in the domain of software engineering [1]–[17]. It can allocate the limited test resources effectively by predicting the fault proneness of software modules. Classification is one of the prevalent methods used for software fault prediction. Its main task is to categorize modules, represented by a set of software metrics, into two classes: fault-prone (FP), or non-fault-prone (NFP). For a specific classification model, the classifier should be trained in advance based on the training data obtained by mining historical software repositories, such as change logs in software configuration management, bug reports in bug tracking systems, and the e-mails of developers.
VI. CONCLUSION
In this paper, we provide a two-stage data preprocessing approach, which incorporates both feature selection and instance reduction, to improve the quality of software datasets used by classification models for software fault prediction. In the feature selection stage, we propose a novel algorithm which involves both relevance analysis and redundancy control. In the instance reduction stage, we apply random under-sampling to keep the balance between the faulty and non-faulty instances. We systematically design experiments based on the Eclipse and NASA datasets, and compare our approach to other commonly used data preprocessing methods. The results demonstrate the potential of our approach in enhancing the prediction performance of the classifiers built thereafter.


(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1-مقدمه
2- کار مرتبط
3- رویکرد پیش پردازش داده دو مرحله ای
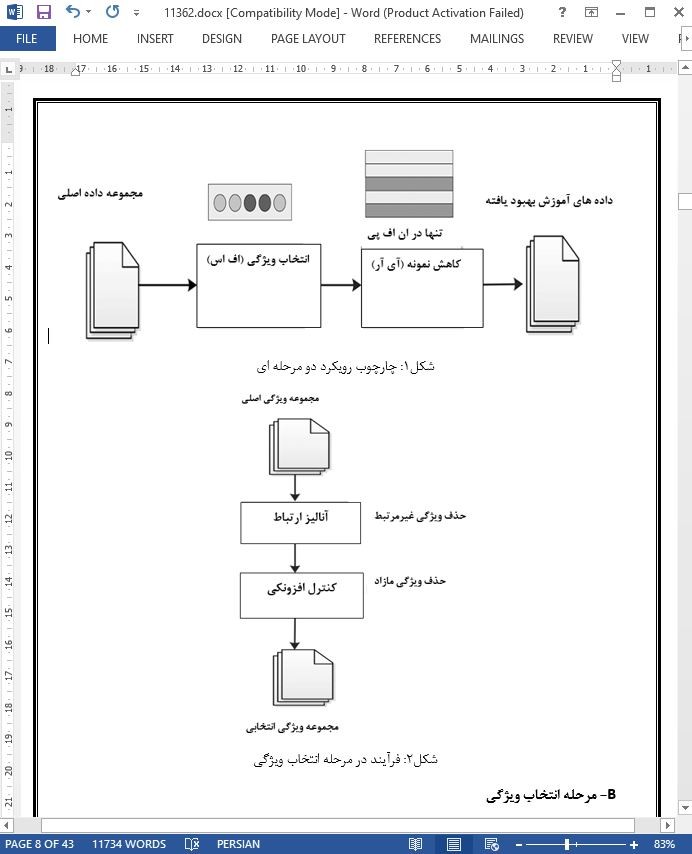
A-چارچوب رویکرد ما
B- مرحله انتخاب ویژگی
C- مرحله کاهش نمونه
4- راه اندازی آزمایش
A-سوالات تحقیق
B- مجموعه های داده
D- سنجش عملکرد
5- آنالیز نتایج
A-RQ1: طرح بهینه¬ی رویکرد
B-RQ2: کارایی رویکرد دو مرحله ای
C-RQ3: کارایی NTC
D-RQ4: کارایی ابزارهای کاهش نمونه
E- RQ5: تاثیر خصوصیات مجموعه داده
F- بحث
G- تهدیدها برای اعتبار
6- نتیجه گیری
Abstract
I. INTRODUCTION
II. RELATED WORK
III. THE TWO-STAGE DATA PREPROCESSING APPROACH
A. The Framework of Our Approach
B. The Feature Selection Stage
C. The Instance Reduction Stage
IV. EXPERIMENTAL SETUP
A. Research Questions
B. Datasets
C. The Experimental Design
D. The Performance Measure
V. RESULT ANALYSIS
A. RQ1: The Optimal Scheme of the Approach
B. RQ2: Effectiveness of the Two-Stage Approach
C. RQ3: The Effectiveness of NTC
D. RQ4: The Effectiveness of Instance Reduction Facilities
E. RQ5: The Impact of the Dataset Properties
F. Discussion
G. Threats to Validity
VI. CONCLUSION
- اصل مقاله انگلیسی با فرمت ورد (word) با قابلیت ویرایش
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه