
تکنیک های کلان داده برای سنجش خطر بانک داری اعتباری در وام های سهام مسکن
چکیده
امروزه حجم دیتابیس هایی که موسسات مالی مدیریت می کنند به قدری بزرگ است که رسیدگی به این مسئله واجب شده و راهکار این مسئله را می توان در تکنیک های کلان داده ای که روی دیتاست های مالی حجیم برای بخش بندی گروه های خطر اعمال می شود یافت. در این مقاله، وجود دیتاست های بزرگ از طریق توسعه ی برخی آزمایشات مونت کارلو با استفاده از تکنیک ها و الگوریتم های شناخته شده پیگیری می شود. علاوه بر این، یک مدل ترکیبی خطی (LLM) به عنوان یک کمک جدید افزایشی برای محاسبه ی خطر اعتبار موسسات مالی پیاده می-شود. این آزمایشات رایانشی با ترکیب های متعددی از اندازه ها و شکل های دیتاست توسعه می یابند تا گستره ی وسیعی از موارد را پوشش دهیم. نتایج نشان می دهند که دیتاست های بزرگ نیازمند تکنیک ها و الگوریتم های کلان داده ای هستند که تخمین کننده های سریع تر و تک مبنایی نشان دهند. کلان داده می تواند به استخراج ارزش داده ها کمک کرده و در نتیجه تصمیمات بهتری را می توان بدون مولفه ی زمان اجرا، اتخاذ کرد. از طریق این تکنیک ها، موسسات مالی هنگام پیش بینی این که کدام مشتریان در پرداخت های خود موفق خواهند بود، با خطر کمتری مواجه خواهند بود. متعاقبا، افراد بیشتری می توانند به وام های اعتباری دسترسی داشته باشند.
1. مقدمه
هر سیستم امتیازدهی اعتباری که امکان ارزیابی خودکار خطرات مربوط به عملیات بانک داری را فراهم کند، امتیازدهی اعتبار نامیده می شود. این خطر ممکن است به مشتریان و مشخصه های اعتباری متعددی وابسته باشد، مانند پرداخت بدهی، نوع اعتبار، سررسید، مقدار وام و سایر ویژگی های ذاتی در عملیات های مالی. یک سیستم عینی برای تایید اعتبار، نیازمند وابستگی بر نظر آنالیزورها نمی باشد.
5. نتیجه گیری
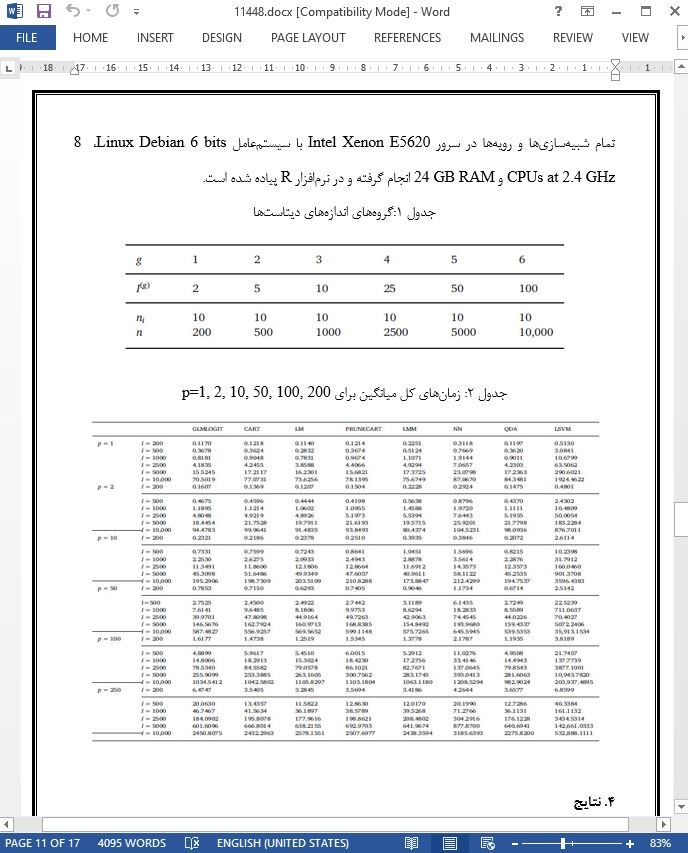
در این آزمایش پژوهشی، قصد ایجاد فایل هایی بود که بتوانند وام ها را برای هر شعبه ی بانکی، بدون وابستگی به یک کشور یا موسسه ی خاص نمایش دهند. به همین منظور، دیتاست های تصادفی از N=2000 تا N=10,000 رکورد و از p=1 تا p=250 متغیر توضیحی را شبیه سازی کردیم.
هشت روش ارائه شد: QDA، CART، PRUNECART، LM، LMM، LSVM، GLMLOGIT و NN. برای هر روش، مقیاس های کارآمدی و بازده محاسبه شد. موثرترین روش ها GLMLOGIT و LMM هستند. LM، LMM و GLMLOGIT بیشترین بازده رایانشی را دارند و بعد از آن ها، QDA و CART قرار دارند. برای دیتاست های بزرگ، LMM کم ترین زمان را صرف می کند و GLMLOGIT نیز برای دیتاست های کوچک کم ترین زمان را دارد.
Abstract
Nowadays, the volume of databases that financial companies manage is so great that it has become necessary to address this problem, and the solution to this can be found in Big Data techniques applied to massive financial datasets for segmenting risk groups. In this paper, the presence of large datasets is approached through the development of some Monte Carlo experiments using known techniques and algorithms. In addition, a linear mixed model (LMM) has been implemented as a new incremental contribution to calculate the credit risk of financial companies. These computational experiments are developed with several combinations of dataset sizes and forms to cover a wide variety of cases. Results reveal that large datasets need Big Data techniques and algorithms that yield faster and unbiased estimators. Big Data can help to extract the value of data and thus better decisions can be made without the runtime component. Through these techniques, there would be less risk for financial companies when predicting which clients will be successful in their payments. Consequently, more people could have access to credit loans.
1. Introduction
Any credit rating system that enables the automatic assessment of the risk associated to a banking operation is called credit scoring. This risk may depend on several customer and credit characteristics, such as solvency, type of credit, maturity, loan amount, and other features inherent in financial operations. It is an objective system for approving credit that does not depend on the analyst's discretion.
In the 1960s, coinciding with the massive demand for credit cards, financial companies began applying credit scoring techniques as a means of assessing their exposure to risk insolvency (Altman, 1998). At the same time, the United States also began to develop and apply credit scoring techniques to assess credit risk assessment and to estimate the probability of default (Escalona Cortés, 2011).
5. Conclusions
In this research experiment, the intention was to make files that can represent loans for any bank branch, without depending on a specific country or particular institution. For this reason, we simulated random datasets from N = 2000 to N = 100,000 records and from p = 1 to p = 250 explanatory variables.
Eight methods were proposed: QDA, CART, PRUNECART, LM, LMM, LSVM, GLMLOGIT, and NN. For each method, measures of effectiveness and efficiency were calculated. The most effective methods are GLMLOGIT and LMM. LM, LMM, and GLMLOGIT are the most computationally efficient methods, followed by QDA and CART. For large datasets, LMM takes less elapsed time, and so does GLMLOGIT for short datasets.


(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1. مقدمه
2. مدل ها
3. آزمایشات شبیه سازی
4. نتایج
5. نتیجه گیری
ABSTRACT
1. Introduction
2. The models
3. Simulation experiments
4. Results
5. Conclusions
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه