
سیستم هوشمند پیش بینی تشخیص بیماری قبلی با استفاده از تکنیک های داده کاوی
چکیده
صنعت مراقبت از سلامتی حجم عظیمی از داده های سلامت را جمع آوری می کند که متاسفانه برای کشف اطلاعات پنهان برای تصمیم گیری موثر مورد بررسی قرار نگرفته است. کشف الگوها و روابط مخفی اغلب ناپدید می شود. تکنیک های پیشرفته داده کاوی می تواند به رفع این مشکل کمک کند. این تحقیق یک نمونه اولیه از سیستم هوشمند پیش بینی بیماری قلبی (IHDPS) را با استفاده از تکنیک های داده کاوری از جمله درخت های تصمیم ، Naïve Bayes و شبکه عصبی ارائه می کند. نتایج نشان می دهد که هر تکنیک دارای قدرت منحصر به فرد خود در تحقیق اهداف ابزارهای تعریف شده کاوش است. سیستم IHDPS می تواند به این پرسش پیچیده پاسخ دهد که " چه اتفاقی رخ می دهد در صورتی که سیستم های متداول تصمیم گیری نتوانند از پرس و جو ها (کوئری ها) پشتیبانی کنند. با استفاده از مشخصات فیزیکی همانند سن، جنسیت، فشار خون و قند خون می تواند احتمال ابتلا به بیماری قلبی را پیش بینی کرد. همچنین ایجاد دانش مهمی همانند الگوها و روابط بین عوامل پزشکی مرتبط با بیماری قلبی را امکان پذیر می سازد. سیستم IHDPS مبتنی بر وب، کاربر پسند، مقیاس پذیر، قابل اطمینان و قابل توسعه است. این سیستم بر روی پلتفورم .NET پیاده سازی می شود.
1. انگیزه
چالش مهمی که سازمان های مراقبت از سلامتی (بیمارستان ها و مراکز بهداشتی) با آن مواجه هستند، تامین خدمات با کیفیت با هزینه های قابل قبول است. خدمات کیفی به مفهوم تشخیص صحیح بیماران و مدیریت موثر درمان است. تصمیم های ضعیف بالینی و پزشکی می تواند منجر به پیامدهای فاجعه باری شود که در نتیجه قابل پذیرش نیستند. همچنین بیمارستان ها می بایست هزینه تست های بالینی را به حداقل برسانند. آن ها می توانند با به کارکیری اطلاعات مناسب مبتنی بر رایانه و/ یا سیستم های پشتیبان تصمیم به این نتایج دست پیدا کنند.
امروزه بیشتر بیمارستان ها برخی انواع سیستم های اطلاعات بیمارستانی را برای مدیریت داده های مراقبت سلامتی یا بیماران خود به کار می گیرند [12]. این سیستم ها به طور معمول حجم عظیمی از داده ها را تولید می کنند به طوری که شکل اعداد، متن، نمودار و تصویر به خود می گیرند. متاسفانه این داده ها به ندرت برای پشتیبانی از تصمیم گیری بالینی مورد استفاده قرار می گیرند. البته ثروتی از اطلاعات پنهان در این داده ها وجود دارد که به طور گسترده مورد استفاده قرار نگرفته است. این مساله پرسش مهمی را ایجاد می کند: " چگونه می توانیم داده ها را به اطلاعات ارزشمندی تبدیل کنیم که به متخصصان مراقبت سلامتی امکان دهد تا تصمیمات هوشمندانه بالینی اخذ کنند؟". این پرسش انگیزه اصلی این تحقیق است.
Abstract
The healthcare industry collects huge amounts of healthcare data which, unfortunately, are not ";mined"; to discover hidden information for effective decision making. Discovery of hidden patterns and relationships often goes unexploited. Advanced data mining techniques can help remedy this situation. This research has developed a prototype Intelligent Heart Disease Prediction System (IHDPS) using data mining techniques, namely, Decision Trees, Naive Bayes and Neural Network. Results show that each technique has its unique strength in realizing the objectives of the defined mining goals. IHDPS can answer complex ";what if"; queries which traditional decision support systems cannot. Using medical profiles such as age, sex, blood pressure and blood sugar it can predict the likelihood of patients getting a heart disease. It enables significant knowledge, e.g. patterns, relationships between medical factors related to heart disease, to be established. IHDPS is Web-based, user-friendly, scalable, reliable and expandable. It is implemented on the .NET platform.
1. Motivation
A major challenge facing healthcare organizations (hospitals, medical centers) is the provision of quality services at affordable costs. Quality service implies diagnosing patients correctly and administering treatments that are effective. Poor clinical decisions can lead to disastrous consequences which are therefore unacceptable. Hospitals must also minimize the cost of clinical tests. They can achieve these results by employing appropriate computer-based information and/or decision support systems.
Most hospitals today employ some sort of hospital information systems to manage their healthcare or patient data [12]. These systems typically generate huge amounts of data which take the form of numbers, text, charts and images. Unfortunately, these data are rarely used to support clinical decision making. There is a wealth of hidden information in these data that is largely untapped. This raises an important question: “How can we turn data into useful information that can enable healthcare practitioners to make intelligent clinical decisions?” This is the main motivation for this research.


(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1. انگیزه
2. بیان مساله
3. اهداف تحقیق
4. مروری بر داده کاوی
5. روش کار
5-1 منبع داده ها
5-2 مدل های کاوش
5-3 اعتبارسنجی اثربخشی مدل
5-4 ارزیابی اهداف کاوش
6. مزیت ها و محدودیت ها
7. نتیجه گیری
منابع
Abstract
1. Motivation
2. Problem statement
3. Research objectives
4. Data mining review
5. Methodology
5.1. Data source
5.2. Mining models
5.3. Validating model effectiveness
5.4. Evaluation of Mining Goals
6. Benefits and limitations
7. Conclusion
8. References
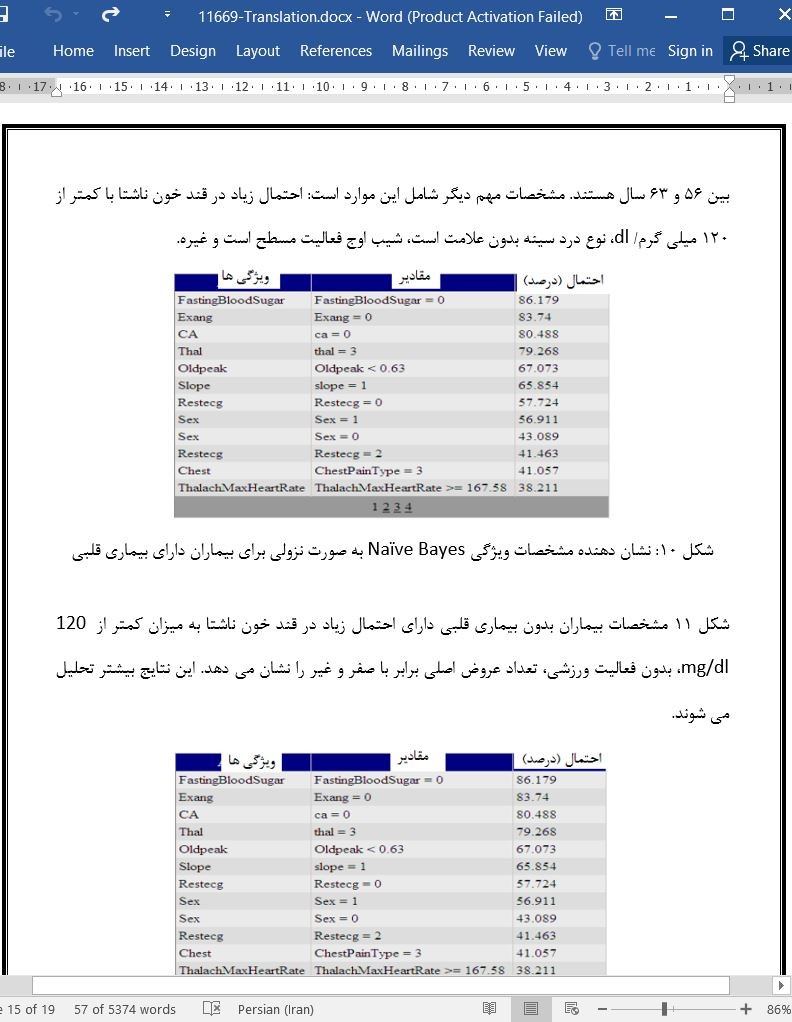
- اصل مقاله انگلیسی با فرمت ورد (word) با قابلیت ویرایش
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه