
سیستم مدیریت داده های شهری: به سمت تحلیل داده های بزرگ برای اینترنت اشیا مبتنی بر محیط شهری هوشمند
چکیده
گسترش مداوم شرایط متنوع شهری حالا با چالش جدیدی با نام پردازش داده های بزرگ رو به رو شده است. درک داده های بسیار حجیم تولید شده در محیط های شهری هوشمند برای تصمیم گیری، یک وظیفه چالش بر انگیز می باشد. تحلیل داده های بزرگ برای به دست آوردن بینش های مناسب در رابطه با داده های حجیم، اهمیت بسیار زیادی دارد. تحلیل داده های بزرگ حالا توجهات زیادی را در زمینه محاسبه و پردازش، سمت خودش جلب کرده است. معماری ارائه شده متشکل از دو ماژول متفاوت می باشد، یعنی ماژول بارگیری داده های بزرگ و ماژول پردازش داده های بزرگ. این مقاله یک معماری مبتنی بر Hadoop را ارائه می کند که برای بارگیری و پردازش داده های بزرگ مورد استفاده قرار می گیرند. عملکرد و کارایی بارگیری داده ها در این مقاله مورد آزمایش قرار می گیرد تا بتوانیم یک روش بهینه را برای بارگیری داده های بزرگ در بستر های توزیع و پردازشی، ارائه کنیم که این بستر ، با نام Hadoop شناخته می شود. برای بررسی کردن نحوه بارگیری داده ها در Hadoop، بارگیری داده ها به صورت مکرر انجام شده و سپس نسبت به تصمیم گیری های مختلف، این شرایط مقایسه می شود. نتایج آزمایشی برای ویژگی های مختلف همراه با داده های دستی و فنی مرتبط با بارگیری داده ها ثبت می شوند تا بتوان کارایی روش پیشنهاد شده را ارزیابی کرد. در طرف دیگر، پردازش به دست آمده با استفاده از چارچوب مدیریت دسته ای YARN با سفارشی سازی های خاص برای زمان بندی پویا نیز بررسی می شود. به علاوه، کارایی راه حل ارائه شده نسبت به پردازش و محاسبات نیز در زمینه خروجی مد نظر، مورد ارزیابی قرار می گیرد.
5. جمع بندی و کارهای آتی
در این مقاله، یک سیستم مدیریت داده های هوشمند شهری مبتنی بر Hadoop ارائه شده است که برای رفع مشکلات تحلیل داده های بزرگ مورد استفاده قرار می گیرد. راه حل ارائه شده به صورت خاص داده های بزرگ در دسته های Hadoop را در نظر دارند. طرح پیشنهاد شده متشکل از بارگذاری داده های بزرگ و ذخیره سازی در سیستم فایل Hadoop و محاسبات و پردازش داده های بزرگ می باشد. بخش اول مسئول انتقال و انتشار داده های بزرگ در Hadoop می باشد. عملکرد بارگذاری داده ها و کارایی آن با استفاده از روش پیشنهاد شده مورد ارزیابی قرار گرفته است که این ارزیابی بر اساس آزمایش های مختلف انجام شد. برای بارگذاری داده های بزرگ بر روی بستر های توزیع شده و پردازشی، یعنی Hadoop، ما این آزمایش ها را طراحی کردیم. به علاوه، بارگذاری داده ها با تصمیم های مختلف به صورت مکرر انجام شده است و تاثیرات هر تغییر ارزیابی شده است. بخش دوم از این تحقیق مرتبط با محاسبات داده ها و پردازش آن ها می باشد. بر خلاف MapReduce معمولی، مدیریت منابع دسته بندی شده بر اساس YARN در این تحقیق برای مدیریت کردن منابع دسته ای و پردازش داده ها با استفاده از الگوریتم MapReduce به صورت مجزا، مورد استفاده قرار گرفته است. Yarn یک روش سفارشی با زمان بندی پویا می باشد. استفاده از چارچوب Hadoop همراه با معماری پیشنهاد شده، با استفاده از مجموعه داده های معتبر مورد ارزیابی قرار گرفت تا اعتبار این روش ارزیابی شود. در نتایج مشخص شد که این روش میتواند برای ساختارهای توسعه شهری و اجتماعی کاربرد بسیار زیادی داشته باشد. به علاوه، روش پیشنهاد شده قابلیت کاربرد آفلاین را دارد زیرا Hadoop قابلیت پردازش آفلاین را ارائه می کند. علاوه بر این، کارایی طرح پیشنهاد شده نسبت به خروجی کار نیز در این مقاله ارائه شده است.
Abstract
The unbroken amplification of a versatile urban setup is challenged by huge Big Data processing. Understanding the voluminous data generated in a smart urban environment for decision making is a challenging task. Big Data analytics is performed to obtain useful insights about the massive data. The existing conventional techniques are not suitable to get a useful insight due to the huge volume of data. Big Data analytics has attracted significant attention in the context of large-scale data computation and processing. This paper presents a Hadoop-based architecture to deal with Big Data loading and processing. The proposed architecture is composed of two different modules, i.e., Big Data loading and Big Data processing. The performance and efficiency of data loading is tested to propose a customized methodology for loading Big Data to a distributed and processing platform, i.e., Hadoop. To examine data ingestion into Hadoop, data loading is performed and compared repeatedly against different decisions. The experimental results are recorded for various attributes along with manual and traditional data loading to highlight the efficiency of our proposed solution. On the other hand, the processing is achieved using YARN cluster management framework with specific customization of dynamic scheduling. In addition, the effectiveness of our proposed solution regarding processing and computation is also highlighted and decorated in the context of throughput.
5. Conclusion and Future
Work In this paper, a Hadoop-based smart urban data management is proposed to deal with the problems in Big Data analytics. The projected solution particularly deals with Big Data loading into Hadoop, cluster management and computation. The proposed scheme comprised of Big Data loading and storage in Hadoop file system and Big Data computation and processing. The first part is responsible for transferring and storing the Big Data in Hadoop. The data loading performance and efficiency is tested using our proposed methodology, based on a variety of experiments, to load the Big Data to a distributed and processing platform, i.e., Hadoop. In addition, data loading is performed and compared with different decisions repeatedly and influenced features are examined. The second part of the research deals with data computation and processing. Unlike traditional MapReduce architecture, YARN-based cluster resource management solution is utilized in this research to manage the cluster resources and process the data using MapReduce algorithm separately. YARN is customized with dynamic scheduling. Using Hadoop framework, the proposed architecture is tested with reliable datasets to verify and reveals that the proposed solution offers precious impending into the society development structures to obtain better architectures. In addition, the proposed solution will be used for OFFLINE application as Hadoop only provides offline processing. Moreover, the effectiveness of our proposed scheme with regard to throughput is also highlighted in this paper.

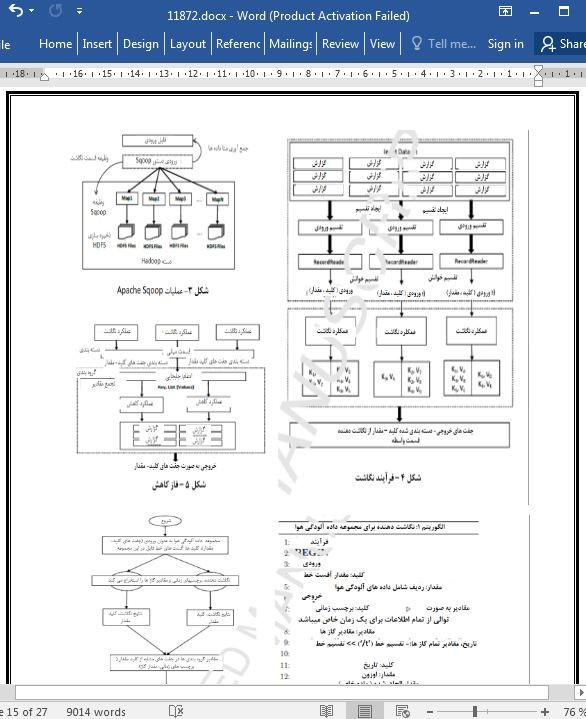

(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1. مقدمه
2. کارهای مربوطه
3. روش های پیشنهاد شده
3.1 سیستم های منابع و جمع آوری داده ها
3.2 بارگذاری و پردازش داده ها
3.3 استفاده از نتایج
4. تحلیل داده ها و نتایج آن
4.1 جزییات اجرا و اطلاعات منبع داده
4.2 بارگذاری و نتایج ترکیب داده ها
4.3 مباحث در رابطه با نتایج الگوریتم MR برای مجموعه داده آلودگی هوا
4.4 خروجی معماری پیشنهادی
5. جمع بندی و کارهای آتی
منابع
Abstract
1. Introduction
2. Related work
3. Proposed methodology
3.1. Source Systems and Data Collection
3.2. Data Loading and Processing
3.3. Results Utilization
4. Data analysis and results
4.1. Implementation Detail and Data Source Information
4.2. Data Loading and Ingestion Results
4.3. Result Discussion on MR Algorithm for Pollution Dataset
4.4. Throughput of Proposed Architecture
5. Conclusion and future work
References
- اصل مقاله انگلیسی با فرمت ورد (word) با قابلیت ویرایش
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه