
داده کاوی و مورد کاربرد مدلسازی در صنعت بانکداری
چکیده
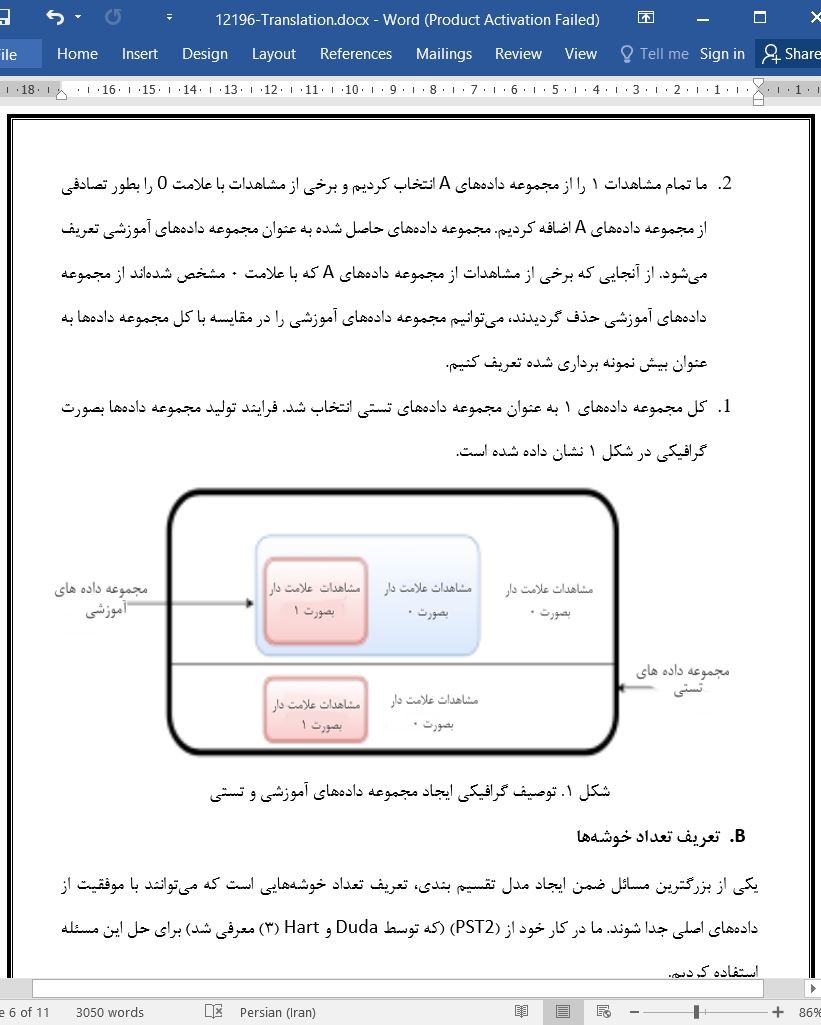
صنعت بانکداری بسیار رقابتی بوده و این بازار فی نفسه در سالهای اخیر بسیار اشباع شده است. به همین دلیل، لازم است که همه مؤسسات بانکی از تمامی اطلاعات موجود برای دستیابی به نوعی از مزیت رقابتی استفاده کنند. در این مقاله ما نشان میدهیم که این امکان وجود دارد که با استفاده از ابزارهای تحلیلی و داده کاوی و بخصوص خوشه بندی (Kمیانگین)، بینش بیشتری در مورد مشتریان خدمات بانکی حاصل کنیم. بخصوص، نشان میدهیم که میتوانیم گروهی از مشتریان را که تمایل بیشتری به خرید وام مسکن دارند تعریف کنیم.
1. مقدمه
در بانکداری خرد، ارائه خدمات متناسب با اولویتهای هر مشتری به دلیل مسائلی که در رابطه با وقت و هزینه وجود دارد، امکانپذیر نیست. این بدین معنی است که وجود برخی از سطوح استانداردسازی لازم است. بده و بستانهای بین یک سرویس استانداردتر و یک سرویس انفرادیتر را میتوان با طبقه بندی مشتریان طبق ویژگیهای ذاتی چندبعدی شخصیت، آسانتر کرد (1). شرکتها در تلاشند تا مشتریان خود را با شناسایی گروههایی از افراد با ساختارهای مورد نیاز دسته بندی کنند، بطوریکه در حد امکان در هر گروه یکسان باشند ولی گروهها تفاوت قابل توجهی با یکدیگر داشته باشند (2). این دسته بندی را میتوان با فن آوریهای داده کاوی انجام داد. به لحاظ تعریف، داده کاوی به روند کشف الگوها در مجموعه دادههای بزرگ گفته میشود که شامل روشهایی است که یادگیری ماشین، آمار و سیستمهای پایگاه دادهها با هم تلاقی پیدا میکنند.
6. نتایج
مقالات متعددی مانند (7)، (8) بر مدلسازی رفتار مشتری با استفاده از تقسیم بندی، تمرکز دارند. در (7)، دادههای داد و ستدهای تلفنی بانک مورد تجزیه و تحلیل قرار گرفت و روش طبقه بندی به عنوان یک کار پیش پردازش برای ایجاد مجموع دادههای آموزشی کم نمونه برداری شده مورد استفاده قرار گرفت که پس از آن به عنوان ورودی برای تکنیکهای مختلف مدلسازی بکار برده شد. از سوی دیگر، مقاله (8) مدل پاسخ مشتری را نشان میدهد که با پیش بینیهای تصادفی و الگوریتم کم نمونه برداری که اطلاعات جمعیت شناختی مشتری، جزئیات تماس و دادههای اجتماعی – اقتصادی آنها را مورد تحلیل قرار میدهد، تأیید شده است.
Abstract
Banking industry is very competitive and the market itself has become very saturated in the recent years. Because of this, it is vital for every banking institution to use all available information in order to gain some sort of competitive advantage. In this paper we will demonstrate that it is possible to gain more insight about banking service clients by using data mining and analysis tools, more specifically by using K-Means clustering. Specifically, we will demonstrate that we can define a group of customers that are more prone to purchase housing loan.
I. INTRODUCTION
IN retail banking, a service tailored to the preferences of each customer is not possible because of time and cost issues. This implies that some degree of standardization is necessary. The trade-off between a more standardized and a more individual service can be made easier by a classification of customers according to multi-dimensional intrinsic characteristics of personality [1]. Companies are trying to segment their customers by identifying groups of persons with need structures that are as homogeneous as possible within each group and significantly heterogeneous between groups [2]. This segmentation can be done by using the data mining technologies. By definition, data mining is the process of discovering patterns in large datasets involving methods at the intersection of machine learning, statistics, and database systems.
VI. CONCLUSION
There are several papers that focus on the client behavior modeling using segmentation, such as [7], [8]. In [7] bank telemarketing data was analyzed and classification method was used as pre-processing activity in order to create under sampled training dataset that was later used as input for various modeling techniques. On the other hand, paper [8] presents customer response model supported by random forests and under sampling algorithm that analyze client demographic information, contact details and socio-economic data.


(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1. مقدمه
2. جمع آوری دادهها
3. انتخاب متغیر
4. خوشه بندی دادهها
A پیش پردازش
B تعریف تعداد خوشهها
C تعریف مرکز ثقل
5. نتایج
6. نتایج
منابع
Abstract
1. INTRODUCTION
2. DATA COLLECTION
3. VARIABLE SELECTION
4. DATA CLUSTERIZATION
A. Pre-processing
B. Defining the number of clusters
C. Defining the centroids
5. RESULTS
6. CONCLUSION
REFERENCES
- اصل مقاله انگلیسی با فرمت ورد (word) با قابلیت ویرایش
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه