
بررسی تحمل خطا در رایانش ابری
چکیده
رایانش ابری باعث تغییرات گسترده در مدل تحویل تکنولوژی اطلاعات در زمینه محصولات و خدمات مختلف شده است. این روش باعث شده نرم افزار ها، بستر ها و منابع زیر ساختی مختلف به صورت سرویس های گسترده در زمان نیاز با استفاده از اینترنت، ایجاد شوند. اما، عملکرد سرویس های رایانش ابری به دلیل آسیب پذیری ذاتی آن ها نسبت به مشکل به دلیل مقیاس های کاری گسترده آن، با مشکلاتی رو به رو می باشد. ما می توانیم از سرویسهای رایانش ابری در بیشترین کارایی شان استفاده کنیم اما شرط لازم برای تحقق این شرایط، بهبود مشکلات مرتبط با پایایی، دسترسی و کارایی موجود در این سیستم ها توسط ارائه دهندگان این سرویس ها می باشد. ازین رو موضوع تحمل خطا در این سیستم ها به یکی از مهم ترین الزام ها برای رسیدن به عملکرد بالا در رایانش ابری تبدیل شده است. این مقاله یک مرور جامع نسبت به مشکلات تحمل خطا در رایانش ابری را بررسی کرده و تاکید ما در این مقاله بر روی مفاهیم خاص، جزییات معماری، جدید ترین تکنیک ها و روش ها می باشد. هدف این مقاله ارائه کردن دیدگاه هایی در رابطه با رویکرد های موجود برای تحمل خطا و همچنین چالش های پیش رومی باشد. این تحقیق، تکنیک های جدید و امید بخشی را ارائه می کند که می توان از آن ها برای رفع مشکلات موجود استفاده کرد و همچنین در نهایت، ما مسیر های تحقیقاتی خوبی را هم برای آینده ارائه می کنیم.
1. مقدمه
رایانش ابری به معنی دسترسی، پیکربندی و دستکاری منابع ( مانند نرم افزار و سخت افزار) از یک مکان راه دور می باشد [1]. R.Buyya و همکارانش [2] رایانش ابری را به صورت یک رایانش توزیع شده و به این صورت تعریف می کنند « یک ابر، نوعی از سیستم های موازی و توزیع شده شامل مجموعه ای از کامپیوتر های به هم متصل و مجازی می باشد که به صورت پویا ترکیب شده و به صورت یک یا چند منع واحد رایانشی بر اساس توافق های سطح خدمات ارائه می شوند که این توافق ها از طریق مذاکره بین ارائه دهنده خدمات و مشتریان، شکل می گیرد».
بر اساس موسسه ملی استاندارد و تکنولوژی (NIST) در ایالات متحده، تعریف سیستم های رایانش ابری به صورت زیر است: «رایانش ابری مدلی برای دسترسی راحت و در زمان نیاز به یک مجموعه مشترک از منابع رایانش قابل پیکربندی می باشد ( مثلا سرویس، شبکه، ذخیره سازی، خدمات و کاربرد های دیگر) که می توان این سیستم ها را خیلی سریع به کاربر ارائه کرده و با کمترین نیاز مدیریتی یا تعامل با ارائه دهنده خدمات، این سرویس ها در زمان اتمام نیاز از دسترس کاربر خارج می شوند» [3].
3. جمع بندی
رایانش ابری ویژگی های مختلفی مانند مقیاس پذیری ، قابلیت ارتجاعی ، در دسترس بودن زیاد و بسیاری موارد دیگر را ارائه می دهد. مدل رایانش ابری صنعت فناوری اطلاعات را تغییر داده است زیرا مزایای بسیاری برای افراد ، محققان ، سازمانها و حتی کشورها به همراه دارد. با وجود مزایای بی شماری ، سیستم ابری همچنان در معرض خرابی است. عدم موفقیت در رایانش ابری به دلیل مقیاس کارکرد اجتناب ناپذیر است. سیاست های تحمل مشکلات معمولاً برای رسیدگی به نقص در محیط ابری اجرا می شود. تکنیک های تحمل عیب به جلوگیری و همچنین تحمل خطاها در سیستم کمک می کند ، که ممکن است به دلیل خرابی سخت افزار یا نرم افزار رخ دهد. انگیزه اصلی به کارگیری تکنیک های تحمل خطا در محاسبات ابری دستیابی به بازیابی خرابی ، قابلیت اطمینان بالا و افزایش در دسترس بودن است.
Abstract
Cloud computing has brought about a transformation in the delivery model of information technology from a product to a service. It has enabled the availability of various software, platforms and infrastructural resources as scalable services on demand over the internet. However, the performance of cloud computing services is hampered due to their inherent vulnerability to failures owing to the scale at which they operate. It is possible to utilize cloud computing services to their maximum potential only if the performance related issues of reliability, availability, and throughput are handled effectively by cloud service providers. Therefore, fault tolerance becomes a critical requirement for achieving high performance in cloud computing. This paper presents a comprehensive overview of fault tolerance-related issues in cloud computing; emphasizing upon the significant concepts, architectural details, and the state-of-art techniques and methods. The objective is to provide insights into the existing fault tolerance approaches as well as challenges yet required to be overcome. The survey enumerates a few promising techniques that may be used for efficient solutions and also, identifies important research directions in this area.
1. Introduction
Cloud computing refers to accessing, configuring and manipulating the resources (such as software and hardware) at a remote location [1]. R. Buyya et al. [2] defined the Cloud computing in terms of distributed computing “A Cloud is a type of parallel and distributed system containing a set of interconnected and virtualized computers that are dynamically provisioned and presented as one or more unified computing resources based on service-level agreements established through negotiation between the service provider and consumers”.
According to the U.S. National Institute of Standards and Technology (NIST) definition: “Cloud computing is a model for enabling convenient, on-demand network access to a shared pool of configurable computing resources (for example servers, networks, storage, services, and applications) that can be quickly provisioned and released with least management effort or service provider interaction" [3].
3. Conclusion
Computing in the cloud provides various features like scalability, elasticity, high availability and many more. The cloud-computing model has changed the IT industry as it brings several benefits to individuals, researchers, organizations, and even countries. Despite providing numerous advantages, the cloud system is still susceptible to failures. Failures are inevitable in cloud computing due to the scale of operation. Fault tolerance policies are commonly implemented to handle faults effectively in the cloud environment. Fault tolerance techniques help in preventing as well as tolerating faults in the system, which may occur either due to hardware or software failure. The main motive to employ fault tolerance techniques in cloud computing is to achieve failure recovery, high reliability and enhance availability.


(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1. مقدمه
2. پیش زمینه رایانش ابری
1.1 زیر ساختارهای رایانش ابری
1.2 مدل های استفاده از سیستمهای ابری
1.3 مدل خدمات ابری
2. رویکرد های تحمل خطا در سیستم های توزیع شده
2.1 تحمل خطا در محیط رایانش توزیع شده
3. رویکرد های تحمیل خطا در رایانش ابری
3.1 مدل سیستم
1.1 رویکرد های کنش گرا
1.2 رویکرد های واکنشی
1.3 دیگر رویکرد های متفرقه برای FT
1.4 ترکیب های تحمل خطا در سیستم های ابری متفرقه و کاربرد های مربوطه
2. جهت های آتی برای تحقیقات
5.1 یادگیری عمقی
5.2 بلاک چین
5.4 تاکید بر روی موضوعات عملکردی
3. جمع بندی
منابع
Abstract
1. Introduction
2. Background of Cloud Computing
1.1. Cloud Computing Infrastructure
1.2. Cloud Deployment Models
1.3. Cloud Service Model
2. Fault Tolerance Approaches in Distributed Systems
2.1. Fault Tolerance in Distributed computing environments
3. Fault tolerance approaches in the cloud computing
3.1. System model
1.1. Proactive approaches
1.2. Reactive approaches
1.3. Other Miscellaneous Approaches used for FT
1.4. Integration of Fault tolerance in miscellaneous Cloud-based and Related Applications
2. Future Directions for Research
5.1 Deep Learning
5.2 Blockchain
5.4 Emphasis on Performance Issues
3. Conclusion
References
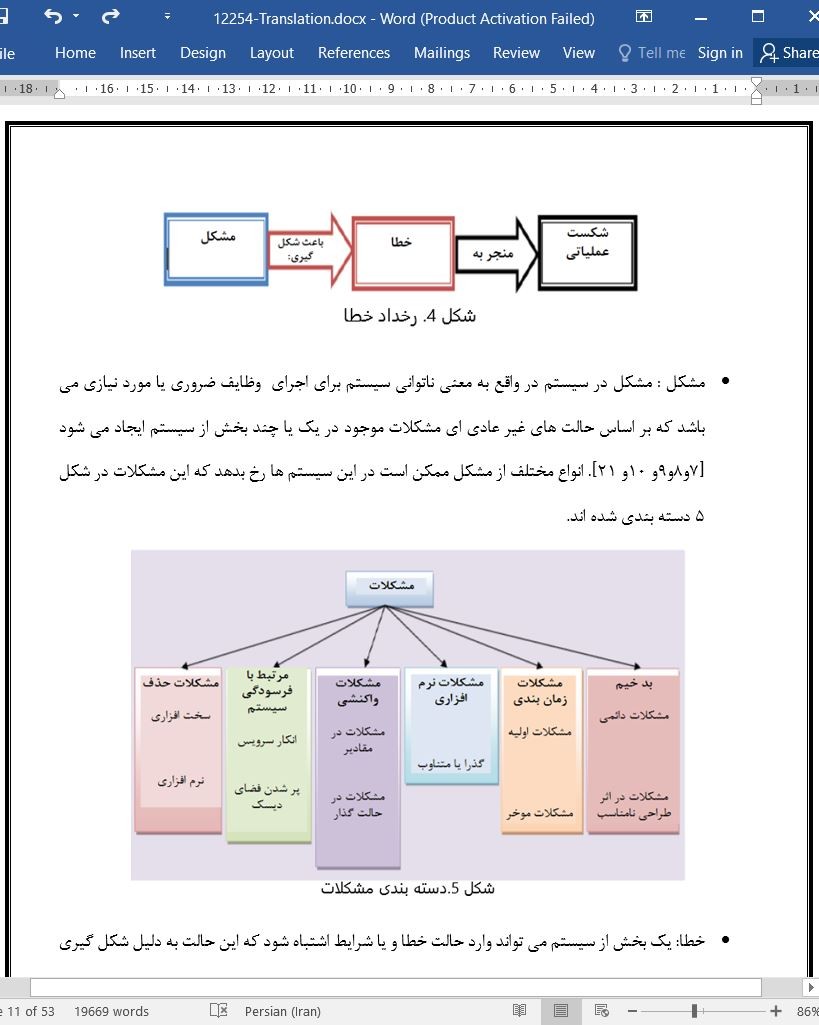
- اصل مقاله انگلیسی با فرمت ورد (word) با قابلیت ویرایش
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه