
به سوی طبقه بندی داده های اینترنت اشیا از طریق ویژگی های معنایی
چکیده
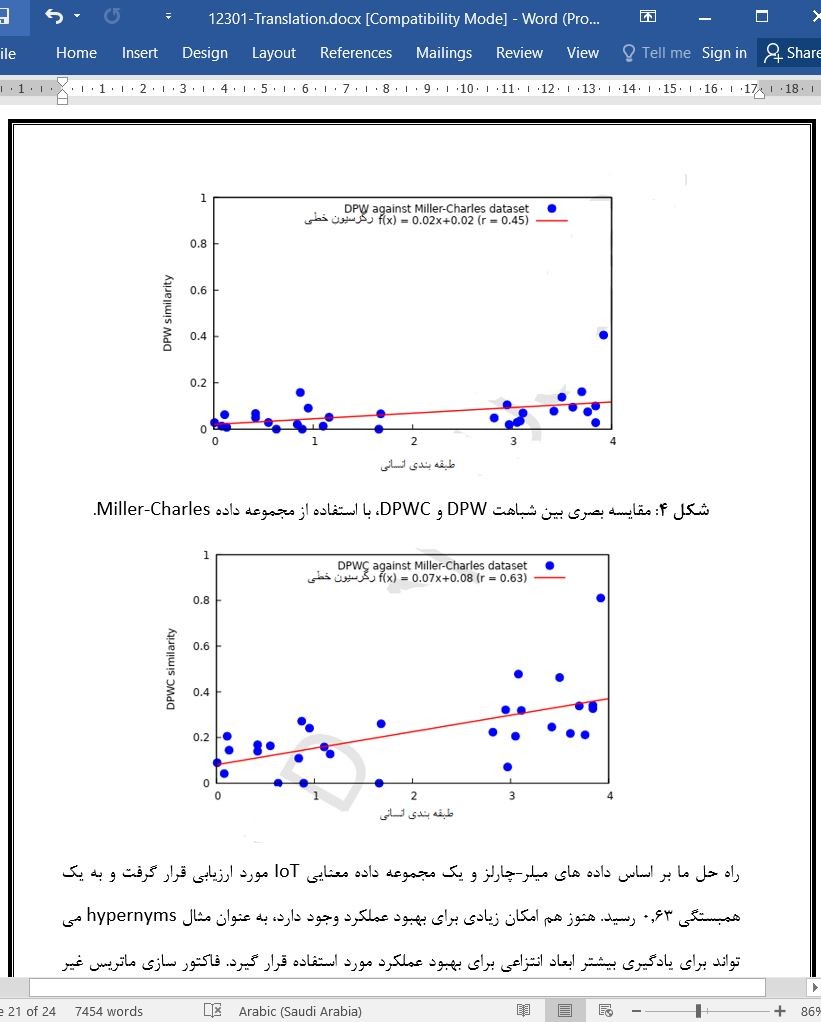
جهان تکنولوژیک با استفاده ازترکیب میلیاردها دستگاه سنجش کوچک، جمع آوری و به اشتراک گذاری مقادیر زیادی اطلاعات متنوع رشد کرده است. با افزایش تعداد چنین دستگاه ها، به طور فزاینده ای مدیریت تمام این منابع داده جدید دشوار می شود. در حال حاضر هیچ روش یکنواخت برای نشان دادن، به اشتراک گذاری و درک اطلاعات اشیا وجود ندارد و این موضوع منجر به سیلوهای اطلاعاتی می شود که مانع اجرای سناریوهای IoT / M2M پیچیده می شوند. سناریوهای IoT / M2M تنها در زمانی که دستگاه ها کار می کنند و با حداقل مداخله ی انسانی یاد می گیرند به توانایی بالقوه خود دست می یابند. در این مقاله محدودیت های ذخیره سازی فعلی و راه حل های تحلیلی را مورد بحث قرار می دهیم، وهمچنین مزایای رویکرد معناشناسی برای سازمان دهی زمینه و توسعه دادن مدل بدون ناظر برای دسته بندی خودکار کلمات. راه حل ما بر اساس داده های میلر-چارلز و یک مجموعه داده معنایی IoT(اینترنت اشیا) از یک پلاتفرم عمومیIoT به دست آمده و به یک همبستگی 0.63 رسید.
1. مقدمه
ظهور اینترنت اشیا (IoT) باعث شد تا تعداد بیشتری از دستگاه ها به قابلیت سنجش و پردازش مجهز شوند. این امر به آنها اجازه می دهد تا با یکدیگر و حتی با خدمات در اینترنت ارتباط برقرار کنند تا یک هدف مشخص را انجام دهند. جزء اصلی این چشم اندازارتباطات، ارتباطات ماشین به ماشین است. M2M به طور کلی به فناوری اطلاعات و ارتباطات می پردازد که قادر به اندازه گیری، تحویل، هضم و واکنش بر اطلاعات خود به طور مستقل است، یعنی با هیچ یا حداقل تعامل انسان.
8. نتیجه گیری
تعداد دستگاه های IoT در یک مرحله پایدار افزایش می یابد. هر یک از آنها مقادیر عظیمی از داده های متنوع را تولید می کند. با این وجود، هر دستگاه / تولید اطلاعات متنی را با ساختارهای مختلف به اشتراک می گذارد، مانع از تعامل متقابل در سناریوهای IoT و M2M می شود.
در این مقاله محدودیت های ذخیره سازی متداول و ابزارهای تحلیلی را مورد بحث قرار داده ایم و به مزایای مدل زمینه سازمانی پایین تا بالا اشاره کردیم. ما همچنین درباره رویکردهای معنایی که به طور خاص برای سناریوهای IoT / M2M طراحی شده اند، بحث کردیم. مدل معنایی ما برای حمایت از دسته بندی کلمه چندگانه گسترش یافت و یک روش یادگیری بدون ناظر جدید طراحی شد. پروفایل های توزیع شده استخراج شده از سرویس های وب ممکن است شامل ابعاد زیاد و معنا های مختلفی از کلمه مورد نظر (معنای تلفیقی) باشد. این مسائل باعث کاهش دقت و پتانسیل این مدل می شود. روش یادگیری ما این مسائل را از طریق فیلترهای کاهش ابعاد و دسته بندی به حداقل می رساند.
Abstract
The technological world has grown by incorporating billions of small sensing devices, collecting and sharing huge amounts of diversified data. As the number of such devices grows, it becomes increasingly difficult to manage all these new data sources. Currently there is no uniform way to represent, share, and understand IoT data, leading to information silos that hinder the realization of complex IoT/M2M scenarios. IoT/M2M scenarios will only achieve their full potential when the devices work and learn together with minimal human intervention. In this paper we discuss the limitations of current storage and analytical solutions, point the advantages of semantic approaches for context organization and extend our unsupervised model to learn word categories automatically. Our solution was evaluated against Miller–Charles dataset and a IoT semantic dataset extracted from a popular IoT platform, achieving a correlation of 0.63.
1. Introduction
With the advent of the Internet of Things (IoT) [1], an increasing number of devices has been equipped with sensing and processing capabilities. These allow them to communicate with each other, and even with services on the Internet, to accomplish a given objective. A major component of this connectivity landscape is machine-to-machine communications [2]. M2M generally refers to information and communication technologies able to measure, deliver, digest and react upon information autonomously, i.e. with none or minimal human interaction.
8. Conclusions
The number of IoT devices is increasing at a steady step. Each one of them generates massive amounts of diverse data. However, each device/manufactures share context information with different structure, hindering interoperability in IoT and M2M scenarios.
In this paper we discussed the limitations of conventional storage and analytical tools, and pointed out the advantages of bottom-up context organization model. We also discussed semantic approaches specifically designed for IoT/M2M scenarios. Our semantic model was extended to support multiple word categories and a new unsupervised learning method was designed. Distributional profiles extracted from web services may contain noisy dimensions and several senses of the target word (sense-conflation). These issues decrease accuracy, and limit the potential of this model. Our learning method minimizes these issues through dimensional reduction filters and clustering.


(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1. مقدمه
2. سرو کار داشتن با داده های IoT
3. ویژگی های معنایی برای IoT
4. پیش زمینه تحقیق و تحقیق های مرتبط
5. پروفایل های توزیع از خدمات وب عمومی
6. پیاده سازی
7. ارزیابی عملکرد
8.نتیجه گیری
منابع
Abstract
1. Introduction
2. Dealing with IoT data
3. Semantic Features for IoT
4. Background and Related Work
5. Distributional profiles from Public Web Services
6. Implementation
7. Performance evaluation
8. Conclusions
References
- اصل مقاله انگلیسی با فرمت ورد (word) با قابلیت ویرایش
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه