
یکپارچه سازی مقیاس پذیر با وزن سبک در پردازنده های FPGA بر اساس شتاب دهنده ها
چکیده
سیستم های چند هسته ای مدرن در حال مهاجرت از سیستم های ناهمگون به سیستم های همگون و یکپارچه با رایانش مبتنی بر شتاب دهنده به منظور غلبه بر موانع عملکرد و محدودیت های توان است. در این راستا شتاب دهنده های مبتنی بر FPGA به طور فزاینده در حال گسترش هستند که دلیل آن انعطاف پذیری عالی و هزینه پایین طراحی است. در این مقاله پشتیبانی ساختاری برای تعامل کارآمد بین شتاب دهنده های متعدد مبتنی بر FPGA و چند پردازنده های تراشه ای (CMP) متصل از طریق شبکه تراشه ای (NoC) پیشنهاد می دهیم. گیرنده های پکت توزیعی و فرستنده های سلسله مراتبی برای حفظ مقیاس پذیری و کاهش تاخیر مسیر حیاتی تحت یک بار سنگین طراحی می شود. یک مکانیزم اختصاصی زنجیره شتاب دهنده نیز برای تسهیل استفاده مجدد از داده های FPGA در بین شتاب دهنده ها پیشنهاد می شود تا سربار ارتباطی بین FPGA و پردازنده ها به دست آید. به منظور ارزیابی معماری پیشنهادی، یک سیستم کامل همراه با پشتیبانی قابل برنامه ریزی با استفاده از نمونه FPGA به دست می آید. نتایج تجربی نشان می دهد که معماری پیشنهادی دارای عملکرد بالایی است و دارای مشخصات مقیاس پذیر و وزن سبک است.
1. مقدمه
امروز تمایل به طرح های با توان پایین و عملکرد بالا منجر به این شده است که سیستم های رایانه ای مدرن از سیستم های چند هسته ای مشابه به سیستم های چند هسته ای ناهمگون مهاجرت کنند که در آن ها شتاب دهنده های سخت افزاری (HWA) برای سرعت بخشی به کاربردهای با محاسبات بالا مورد استفاده قرار می گیرند [1]. آرایه های دروازه برنامه پذیر در محل (FPGA) که دارای انعطاف پذیری بالا و قابلیت محاسباتی زیادی هستند، گزینه های مناسبی برای سرویس دهی به عنوان شتاب دهنده های سخت افزاری در سیستم های ناهمگون هستند. اخیراً FPGAها به طور گسترده در صنعت به کار گرفته شده اند تا ظرفیت محاسباتی چند پردازنده های تراشه ای (CMP) را ارتقاء دهند. به عنوان نمونه، شرکت های Altera و Intel یک پلتفورم تحقیقاتی به نام HARP [2] را ارائه می دهند که شامل Altera Stratix-V FPGA و یک پردازنده Intel Xeon E5 است. به همین ترتیب، پلتفورم Zynq شرکت Xilinx [3] یک پردازنده دو هسته ای ARM را با FPGA معمولی ترکیب می کند تا یک سیستم بر روی تراشه (SoC) برنامه پذیر را شکل دهد.
7. نتیجه گیری و کار آتی
هدف اصلی این مقاله پیشنهاد و پیاده سازی طرح ساختاری مستقل از پلتفورم برای شتاب دهنده های چند تایی مبتنی بر FPGA برای ارتباط با چند پردازنده تراشه ای از طریق NoC است. هدف ما بهینه سازی عملکرد رابط در زمانی است که تعداد زیاد HWAها به یک FPGA نگاشته می شوند. به ویژه ما تغییرات پارامترهای کلیدی مختص به طراحی را مورد بررسی قرار می دهیم: (1) تعداد TB ها برای کاهش تاخیر ارتباط، (2) استراتژی های توزیع شده PR و استراتژی های سلسله مراتبی PS برای حداکثر کردن فرکانس کاری همانند حفظ مقیاس پذیری خوب و (3) سرعت بخشی و تبادل به دست آمده از مکانیزم پیشنهادی زنجیره. نتایج به دست آمده نشان می دهد که مجموعه بهینه این پارامترها می تواند بهبودی بیش از دو برابر در عملکرد را تضمین کند. به منظور ارزیابی کارکرد در سطح سیستم و ارزیابی عملکرد معماری رابط پیشنهادی، یک سیستم کامل را بر روی یک FPGA پیاده سازی می کنیم. NoC، FPGA همراه با یک معماری ادغام شده رابط و چندین HWA همراه با هسته های پردازنده با کارکردهای فراخوانی HWA برای غلبه بر مسائل برنامه پذیری مورد استفاده قرار می گیرند. ما طرح پیشنهادی خود را با نمونه های اولیه حافظه پنهان مشترک FPGA و مبتنی بر باس مقایسه می کنیم. در نهایت در می یابیم که معماری پیشنهادی از نطر عملکرد کارآیی مساحت و مقیاس پذیری برتری است. در کار آتی قصد داریم تا اثر پروتکل های مختلف مسیریابی NoC بر عملکرد رابط را مورد ارزیابی قرار دهیم.
Abstract
Modern multicore systems are migrating from homogeneous systems to heterogeneous systems with accelerator-based computing in order to overcome the barriers of performance and power walls. In this trend, FPGA-based accelerators are becoming increasingly attractive, due to their excellent flexibility and low design cost. In this paper, we propose the architectural support for efficient interfacing between FPGA-based multi-accelerators and chip-multiprocessors (CMPs) connected through the network-on-chip (NoC). Distributed packet receivers and hierarchical packet senders are designed to maintain scalability and reduce the critical path delay under a heavy task load. A dedicated accelerator chaining mechanism is also proposed to facilitate intra-FPGA data reuse among accelerators to circumvent prohibitive communication overhead between the FPGA and processors. In order to evaluate the proposed architecture, a complete system emulation with programmability support is performed using FPGA prototyping. Experimental results demonstrate that the proposed architecture has high-performance, and is light-weight and scalable in characteristics.
1 INTRODUCTION
IN OWADAYS, the desire for low-power and highperformance design has led to the migration of modern computing systems from homogeneous multicore systems to heterogeneous multicore systems, where hardware accelerators (HWAs) are used to speed up computationally intensive applications [1]. Field programmable gate arrays (FPGAs), which feature great flexibility and high computational capability, are promising candidates to serve as HWAs in heterogeneous systems. Recently, FPGAs have been seen increasingly used in industry to enhance the computation capability of chip-multiprocessors (CMPs). For instance, Altera and Intel provide a research platform, HARP [2], which consists of an Altera Stratix-V FPGA and an Intel Xeon E5 processor. Likewise, Xilinx’s Zynq platform [3] combines a dual core ARM processor with traditional FPGA fabric to form a programmable system-on-chip (SoC).
7 CONCLUSION AND FUTURE WORK
This paper mainly proposes and implements a platformindependent architectural design for FPGA-based multi-accelerators to efficiently interface with chipmultiprocessors through NoC. Our target is to optimize the performance of the interface when a large number of HWAs are mapped in an FPGA. Specifically, we explore the variations of the key design-specific parameters including: (1) the number of TBs to reduce communication latency; (2) the distributed PR strategies and hierarchical PS strategies to maximize operating frequency as well as maintain good scalability; and (3) the speedup and tradeoff derived from our proposed chaining mechanism. Results show that the optimal set of these parameters can guarantee a more than 2× improvement in performance. In order to emulate the system-level functionality and evaluate the performance of the proposed interface architecture, we prototype a full system on an FPGA. This prototype encompasses NoC, the FPGA with an integrated interface architecture and multiple HWAs, together with the soft processor cores with HWA invocation functions to tackle programmability issues. We compare our design with commonly used bus-based and FPGA share cache prototypes and finally find our proposed interface architecture demonstrates prominent superiority in performance, area-efficiency and scalability. In our future work, we plan to evaluate the effect of different NoC routing protocols on the performance of the interface.

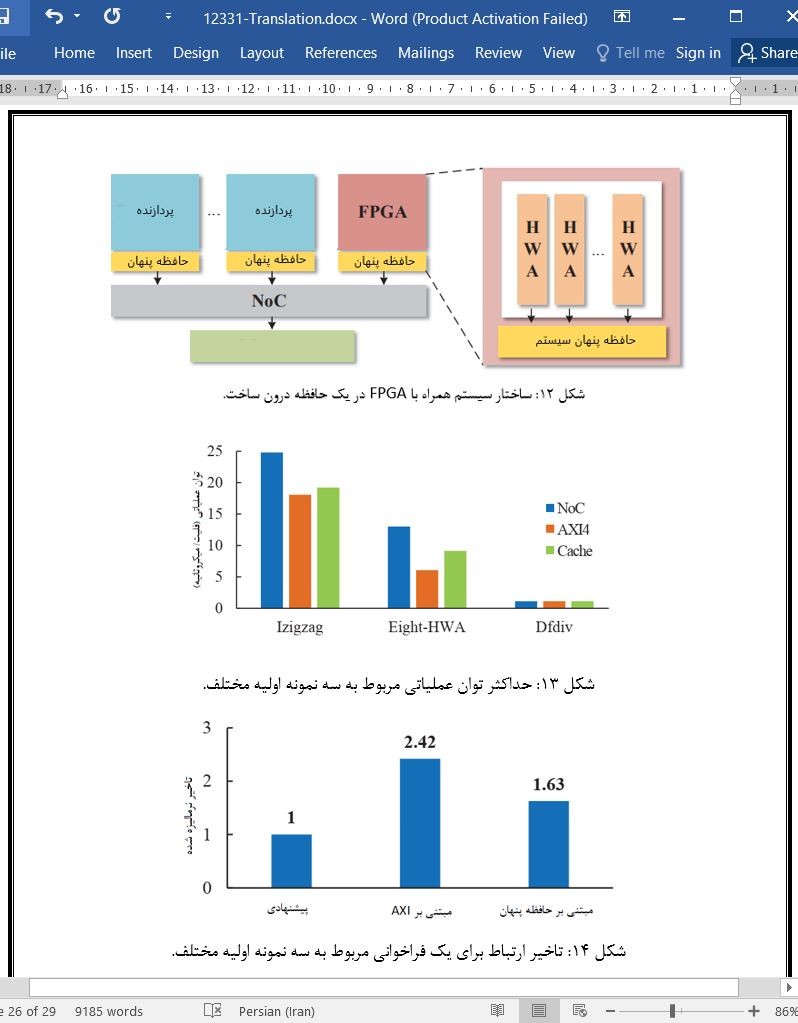

(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1. مقدمه
2. کارهای مرتبط
3. مروری بر کل سیستم
1-3 سیستم چند هسته ای مبتنی بر NoC
2-3 قالب پکت
4. معماری چند شتاب دهندگی مبتنی بر FPGA
1-4 بلوک رابط
A-1 گیرنده پکت (PR)
A-2 فرستنده پکت (PS)
2-4 کانال شتاب دهنده سخت افزاری (کانال HWA)
B-1 نوآوری در HWA
B-2 مکانیزم درخواست و اعطا
B-3 مکانیزم زنجیره HWA
5. پشتیبانی از برنامه پذیری برای نوآوری HWA
6. نتایج آزمایش
1-6 راه اندازی تجربی
2-6 بهره برداری از بافر وظیفه
3-6 حداکثر فرکانس و به کارگیری منابع
1-3-6 حداکثر فرکانس
2-3-6 به کارگیری منابع
4-6 توان عملیاتی معماری پیشنهادی
5-6 تجزیه تاخیر
6-6 ارزیابی مکانیزم زنجیره HWA
7-6 مقایسه با ادغام مبتنی بر باس
8-6 مقایسه با حافظه پنهان اشتراکی FPGA
7. نتیجه گیری و کار آتی
منابع
Abstract
1 INTRODUCTION
2 RELATED WORK
3 FULL-SYSTEM OVERVIEW
3.1 NoC-based multicore system
3.2 Packet format
4 FPGA-BASED MULTI-ACCELERATOR ARCHITECTURE
4.1 Interface block
A.1 Packet receiver (PR)
A.2 Packet sender (PS)
4.2 Hardware accelerator channel (HWA channel)
B.1 HWA invocation
B.2 Request and grant mechanism
B.3 HWA chaining mechanism
5 PROGRAMMABILITY SUPPORT FOR HWA INVOCATION
6 EXPERIMENTAL RESULTS
6.1 Experimental setup
6.2 Task buffer exploitation
6.3 Maximum frequency and resource utilization
6.3.1 Maximum frequency
6.3.2 Resource utilization
6.4 Throughput of the proposed architecture
6.5 Latency breakdown
6.6 Evaluation of HWA chaining mechanism
6.7 Comparison with bus based integration
6.8 Comparison with shared FPGA cache
7 CONCLUSION AND FUTURE WORK
REFERENCES
- اصل مقاله انگلیسی با فرمت ورد (word) با قابلیت ویرایش
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه