
دانلود مقاله ارزیابی کنترل همروندی توزیع شده
چکیده
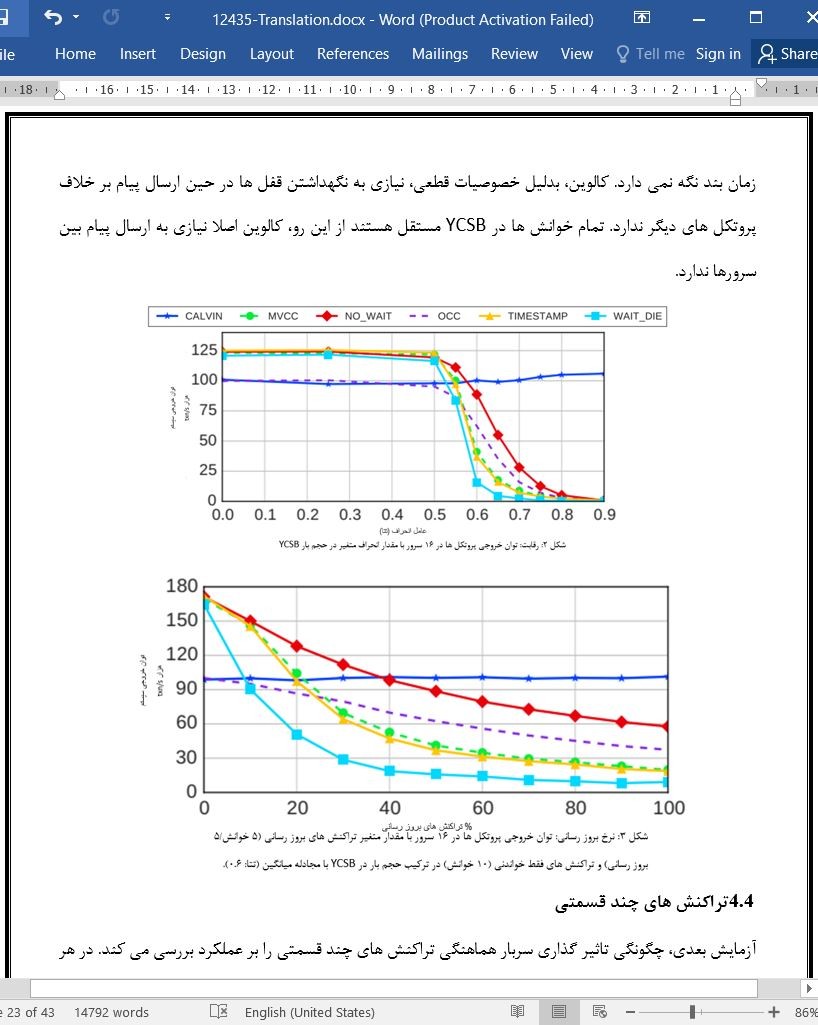
افزایش حجم تراکنش منجر به بررسی مجدد مزایای پردازش تراکنش توزیع شده گردیده است. بطور خاص، قسمت بندی داده ها در بین سرورهای مختلف می تواند عملکرد سیستم را از طریق پردازش موازی تراکنش ها توسط سرور بهبود بخشد. از طرفی، اجرای تراکنش ها در بین سرورهای مختلف، مقیاس پذیری و عملکرد این سیستم ها را محدود می سازد.
در این مقاله، ما اثر توزیع بر پروتکل های کنترل همروندی را در یک محیط توزیع شده تعیین خواهیم کرد. همچنین، شش پروتکل جدید و سنتی را در یک چارچوب ارزیابی پایگاه داده توزیع شده درون حافظه به نام دنوا (Deneva) بررسی خواهیم نمود و آنها را با توجه به مشابهت با یکدیگر مقایسه می کنیم. نتایج بدست آمده بیانگر محدودیت های جدی در موتورهای پردازش تراکنش توزیع شده هستند. علاوه بر این، در تحلیل و ارزیابی انجام شده، ما تنگناهای موجود در مقیاس پذیری متناسب با هر پروتکل را شناسایی خواهیم کرد. در نهایت، این نتیجه بدست آمد که برای دستیابی به یک عملیات مقیاس پذیر مطلوب، راهکارهای کنترل همروندی توزیع شده، باید با سخت افزار شبکه جدید (در یک شبکه ی محلی) یا برنامه ها (از طریق مدل سازی داده ها و اجرای معنادار آنها) یا هر دوی آنها جفت شوند.
1. مقدمه
برای داده زایی و حجم پرسش، ظرفیت سیستم های مدیریت پایگاه داده تک سرور کم است (DBMS) (20، 47، 17). در نتیجه این موضوع، سازمان ها بطور فزاینده داده ها را در بین سرورهای مختلف تقسیم بندی نموده اند که در هر قسمت تنها یک زیر مجموعه از پایگاه داده وجود دارد. این DBMS ها از این توانایی برخوردارند تا این چنین چالش هایی را کاهش دهند و به عملکرد بسیار بالا در زمانی که کوئری ها به اطلاعات در یک قسمت نیاز دارند، دست یابند (33، 49). در بسیاری از برنامه های پردازش تراکنش آنلاین (OLTP)، تقسیم بندی داده ها با این شیوه که تمام کوئری ها تنها به یک قسمت نیاز داشته باشند، چالش برانگیز خواهد بود (اگر امکان پذیر باشد) (22، 43). از سوی دیگر، برخی کوئری ها همیشه به اطلاعات در قسمت های مختلف نیاز خواهند داشت.
متاسفانه پروتکل های کنترل همروندی چند قسمتی سریال سازی شی، اثرات تخریبی بر عملکرد دارند (54، 49). زمانی که یک تراکنش به سرورهای مختلفی در یک شبکه دسترسی پیدا می کند، باید تا زمانی که با تراکنش های دیگر در حال رقابت است، صبر کند تا آنها کامل شوند. در نتیجه، این موضوع یک گزاره بسیار مخرب برای مقیاس پذیری سیستم پدید می آورد.
8. نتیجه گیری
ما عملکرد تراکنش های توزیع شده سریال سازی شی را در یک محیط رایانش ابری مدرن بررسی کردیم. همچنین، عملکرد شش پروتکل کنترل همروندی مدرن و سنتی را ارزیابی کردیم و نشان دادیم که در بسیاری از حجم بارها، تراکنش های توزیع شده در یک خوشه تنها به مقدار کمی از توان خروجی تراکنش های غیر توزیع شده در یک ماشین فراتر می روند. تنگنای مقیاس پذیری نیز وابسته به پروتکل می باشد: قفل گذاری دو مرحله ای در شرایطی که رقابت بالایی وجود دارد، به دلیل توقف ها عملکرد ضعیفی دارد، کنترل همروندی برچسب زمانی نیز در این شرایط، بدلیل بافر شدن عملکرد خوبی ندارد، کنترل همروندی بهینه نیز یک سربار اعتبار سنجی دارد و پروتکل قطعی، عملکرد خود را در محدوده ای از بارهای نامطلوب و انحراف داده حفظ می کند ولی عملکرد محدودی به دلیل زمان بندی تراکنش دارد. در نهایت، این نتایج حاکی از مشکل مقیاس پذیری جدی در تراکنش های توزیع شده هستند. ما معتقدیم راه حل این مشکل، جفت شدگی محکم تر موتورهای کنترل همروندی با برنامه ها و سخت افزار است که از طریق ترکیب بهبود شبکه در زیر ساخت ابری (حداقل در یک مرکز داده)، مدل سازی داده ها و تکنیک های کنترل همروندی معناگرا حاصل می شود. علاوه بر این، ما چارچوب دنوا را برای ارائه ی یک پلتفرم باز برای دیگران در نظر گرفتیم تا بتوانند ارزیابی دقیقی از تکنیک های کنترل همروندی جدید و جایگزین ارائه کنند و شفافیت را در فضای ابهام انگیز مبحث پروتکل های کنترل همروندی ایجاد نمایند.
Abstract
Increasing transaction volumes have led to a resurgence of interest in distributed transaction processing. In particular, partitioning data across several servers can improve throughput by allowing servers to process transactions in parallel. But executing transactions across servers limits the scalability and performance of these systems.
In this paper, we quantify the effects of distribution on concurrency control protocols in a distributed environment. We evaluate six classic and modern protocols in an in-memory distributed database evaluation framework called Deneva, providing an apples-to-apples comparison between each. Our results expose severe limitations of distributed transaction processing engines. Moreover, in our analysis, we identify several protocol-specific scalability bottlenecks. We conclude that to achieve truly scalable operation, distributed concurrency control solutions must seek a tighter coupling with either novel network hardware (in the local area) or applications (via data modeling and semantically-aware execution), or both.
1. INTRODUCTION
Data generation and query volumes are outpacing the capacity of single-server database management systems (DBMS) [20, 47, 17]. As a result, organizations are increasingly partitioning data across several servers, where each partition contains only a subset of the database. These distributed DBMSs have the potential to alleviate contention and achieve high throughput when queries only need to access data at a single partition [33, 49]. For many on-line transaction processing (OLTP) applications, however, it is challenging (if not impossible) to partition data in a way that guarantees that all queries will only need to access a single partition [22, 43]. Invariably some queries will need to access data on multiple partitions.
Unfortunately, multi-partition serializable concurrency control protocols incur significant performance penalties [54, 49]. When a transaction accesses multiple servers over the network, any other transactions it contends with may have to wait for it to complete [6]— a potentially disastrous proposition for system scalability.
8. CONCLUSION
We investigated the behavior of serializable distributed transactions in a modern cloud computing environment. We studied the behavior of six classic and modern concurrency control protocols and demonstrated that, for many workloads, distributed transactions on a cluster often only exceed the throughput of non-distributed transactions on a single machine by small amounts. The exact scalability bottleneck is protocol-dependent: two-phase locking performs poorly under high contention due to aborts, timestamp-ordered concurrency control does not perform well under high contention due to buffering, optimistic concurrency control has validation overhead, and deterministic protocol maintains performance across a range of adverse load and data skew but has limited performance due to transaction scheduling. Ultimately, these results point to a serious scalability problem for distributed transactions. We believe the solution lies in a tighter coupling of concurrency control engines with both hardware and applications, via a combination of network improvements on cloud infrastructure (at least within a single datacenter), data modeling, and semantics-based concurrency control techniques. Moreover, we intend for the Deneva framework to provide an open platform for others to perform a rigorous assessment of novel and alternative concurrency control techniques and to bring clarity to an often confusing space of concurrency control protocols.


(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1. مقدمه
2. بررسی سیستم
2.1 اصول و معماری
2.2مدل تراکنش
2.3 مدل اجرا
2.4 اجرا از سوی سرور
3. پروتکل های تراکنش
3.1 قفل گذاری دو مرحله ای
3.2 ترتیب برچسب زمانی
3.3 خوشبینانه
3.4 قطعی
3.5 تثبیت دو مرحله ای
4. ارزیابی
4.1 حجم بار
4.2 رقابت
4.3 نرخ بروز رسانی
4.4 تراکنش های چند قسمتی
4.5 مقیاس پذیری
4.6 سرعت شبکه
4.7 توقف های وابسته به داده
4.8 TPC-C
4.9 تامین کننده قطعات محصول
5. بحث
5.1 تنگناهای سیستم مدیریت پایگاه داده توزیع شده
5.2 راهکار های بالقوه
6. کار مرتبط
7. کار آینده
8. نتیجه گیری
منابع
ABSTRACT
1. INTRODUCTION
2. SYSTEM OVERVIEW
2.1 Principles & Architecture
2.2 Transaction Model
2.3 Execution Model
2.4 Server-Side Execution
3. TRANSACTION PROTOCOLS
3.1 Two-Phase Locking
3.2 Timestamp Ordering
3.3 Optimistic
3.4 Deterministic
3.5 Two-Phase Commit
4. EVALUATION
4.1 Workloads
4.2 Contention
4.3 Update Rate
4.4 Multi-Partition Transactions
4.5 Scalability
4.6 Network Speed
4.7 Data-Dependent Aborts
4.8 TPC-C
4.9 Product-Parts-Supplier
5. DISCUSSION
5.1 Distributed DBMS Bottlenecks
5.2 Potential Solutions
6. RELATED WORK
7. FUTURE WORK
8. CONCLUSION
REFERENCES
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه