
دانلود مقاله استراتژی های قراردهی سرور المثنی جدید با استفاده از الگوریتم های خوشه بندی
چکیده
بسیاری از ارائه دهندگان خدمات، محتواهای مختلفی را در اینترنت منتشر می سازند. شبکه های توزیع محتوا (CDN) کل وبسایت یا بخش عمده ای از مطالب وبسایت را کپی می کنند تا محتوایی نزدیک به محتوای جستجو شده توسط کاربر را نشان دهند و تأخیر در انتشار را کاهش دهند. CDN ها به منظور ارائه محتوای وب باید تصمیم بگیرند که سرورهای المثنی را در کجا قرار دهند و اینکه چه تعداد سرور لازم می باشد. ما در مقاله حاضر یک فرمولبندی برنامه نویسی خطی را برای قراردهی سرور وب المثنی ارائه داده ایم. ما همچنین الگوریتم های جدیدی را با استفاده از K-means (k-میانگین)، خوشه بندی c-means فازی، و شبکه عصبی نگاشت های خود سازمانده (SOM) به منظور قراردهی المثنی های سرور وب ارائه داده ایم. هدف ما این است که بهترین سایت های سرور المثنی را پیدا کنیم که فاصله بین المثنی ها و مشتریان را به حداقل برسانند – تا المثنی ها حفظ شوند. ما الگوریتم های خود را با الگوریتم حریصانه مقایسه می کنیم. ما در این مقاله به بهبود چشمگیری از لحاظ تعادل بار و زمان اجرا دست یافته ایم.
1. مقدمه
اینترنت در ابتدا بصورت «اینترنت میزبان ها» تصور میشد اما امروزه عناصر کلیدی جهان وب (شبکه گسترده جهانی) داده ها و خدمات (یا محتوا) هستند [2]. شبکه های توزیع محتوا (CDN) بعنوان شبکه های پیشرفته مشتری/سرور، محتوا را از سرور مبدأ به سرورهای جانشین کپی می کنند – سرورهای جانشین، سرورهای لبه ای هستند که از طرف سرور مبدأ عمل می کنند تا قابلیت دسترسی، قابلیت اطمینان، شفافیت، و کیفیت خدمات (QoS) را بهبود دهند؛ این خدمات توسط مشتریان نهایی دیده می شوند [10,11,14,24]. فراهم کنندگان CDN یا تجاری هستند (یعنی Akamai، Limelight، یا SAVVIS) یا آکادمیک/آزاد هستند (یعنی Coral، CoDeeN، یا Globule)، و قراردادهایی با فراهم دهندگان CDN بسته می شود [2].
یک جنبه مهم و بحرانی در موفقیت CDN، شیوه قراردهی جغرافیایی سرورهای المثنی برای بهینه سازی «ارائه محتوا» است [25]. چندین الگوریتم برای حل مشکل قراردهی سرور المثنی پیشنهاد شده اند [2]. استراتژی های قراردهی مهم هستند چون قراردهی مناسب سرورهای المثنی از طریق کاهش تأخیر به مشتریان برای فراهم کنندگان محتوا کمک میکند، و از طریق کاهش مصرف پهنای باند و الگوریتم های هات اسپات هم به سازمان های سرویس دهنده اینترنت (ISP) کمک میکند. الگوریتم حریصانه، یک تأسیسات را در هر گامی که پیشاپیش در رابطه با سایت موجود است قرار میدهد و کمترین هزینه را ایجاد میکند اما در هات اسپات، المثنی ها در نزدیکی مشتریانی قرار داده میشوند که بیشترین بار را ایجاد کرده اند.
7. نتیجه گیری ها
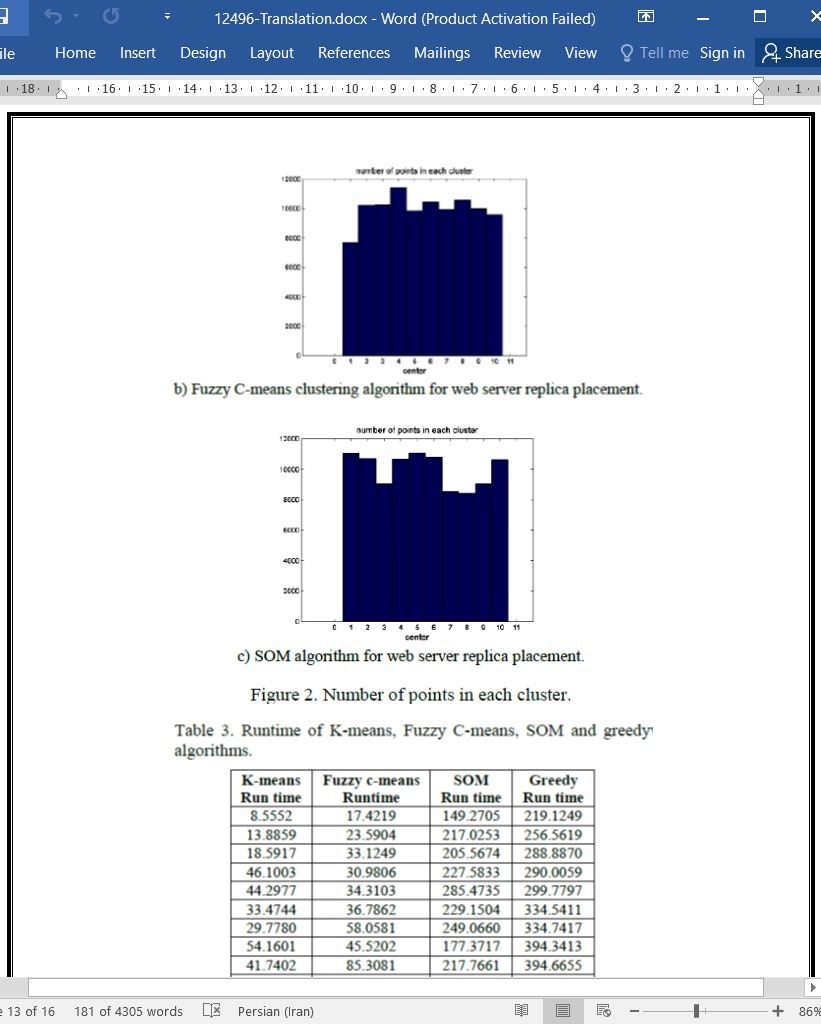
ما در این مقاله سه الگوریتم جدید را برای حل مسئله قراردهی المثنی سرور وب ارائه داده ایم؛ ما از الگوریتم های K-means ، c-means فازی و SOM استفاده کرده ایم و یک مرحله جدید را به این الگوریتم ها اضافه نموده ایم. اگرچه الگوریتم حریصانه پیشنهاد شده توسط کیو و همکارانش [26] نتایج بهتری را بدست آورده است اما الگوریتم های خوشه بندی داده ها برای قراردهی المثنی سرور وب از لحاظ تعادل بار و زمان اجرا خیلی بهتر هستند و اینها عوامل مهمی در تأخیر و مصرف پهنای باند در شبکه های CDN هستند. همچنین زمان محاسبه الگوریتم های SOM، K-means و c-means فازی برای قراردهی المثنی سرور وب نسبت به الگوریتم حریصانه پیشنهاد شده توسط کیو و همکارانش [26] خیلی کمتر بود. ما همچنین برای فرمولبندی قراردهی المثنی سرور وب از برنامه نویسی خطی استفاده کردیم. ما بر این باور هستیم که مطالعه ما بینش هایی را برای فراهم کنندگان CDN ایجاد می کند و در نحوه طراحی CDN ها برای فراهم سازی تعادل بار در بین سرورهای المثنی به آنها کمک می کند.
Abstract
Many service providers distribute various kinds of content over the internet. Content Distribution Networks (CDNs) use replication of either entire website or most used objects to bring content close to the users and improve communication delay. In order to deliver web contents, CDNs should decide where to place replica servers and how many replicas are needed. In this paper, a linear programming formulation for web server replica placement has been provided. We also present new algorithms using K-means, Fuzzy c-means clustering and Self-Organizing Maps (SOM) Neural network to place web server replicas. Our objective is to find best replica server sites, which minimize distance between replicas and clients- to keep replicas. We compare our algorithms with Greedy algorithm. We have considerable enhancement in terms of load balancing and Runtime.
1.Introduction
The internet was originally conceived as “internet of hosts” but today, the key elements of growing World Wide Web are data and services (or content) [2]. Content Distribution Networks (CDNs) as advanced client/ server networks replicate content from the origin server to surrogate servers-some edge servers that act on behalf of origin server to improve accessibility, reliability, transparency and Quality of Service (QoS) perceived by end clients [10, 11, 14, 24]. CDN providers are either commercial (i.e., Akamai, Limelight, SAVVIS) or academic/ free (i.e., Coral, CoDeeN, Globule) and sign contract with CDN providers [2].
An important and critical aspect in CDN success is the way that replica servers are placed geographically to optimize content delivery [25]. Several algorithms have been proposed to address the replica placement problem [2]. Placement strategies are important because appropriate placement of server replicas benefits content providers by reducing latency for their clients, and benefits Internet Service Providers (ISPs) by reducing bandwidth consumption.
7. Conclusions
In this paper we have presented three new algorithms to solve web server replica placement problem using K-means, Fuzzy C-means and SOM by adding a new step in these algorithms. Although Greedy algorithm proposed by Qiu et al. [26] gives better results but data clustering algorithms for web server replica placement are much better in terms of load balancing and runtime which are important in delay and bandwidth consumption in CDN networks. Also, the Computational time of SOM, K-means and Fuzzy Cmeans algorithms for web server replica placement are significantly lower than Greedy algorithm proposed by Qiu et al. [26]. We also apply Linear Programming to formulate web server replica placement. We believe that our work provides insights to CDN providers on how to design CDNs to provide load balancing among replica servers.


(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1. مقدمه
2. مطالعات مرتبط
3. فرمولبندی برنامه نویسی خطی
4. الگوریتم های K-means، c-means فازی و SOM برای قراردهی المثنی سرور وب
4.1 خوشه بندی K-means برای قراردهی سرور المثنی
4.2 الگوریتم c-means فازی
4.3 نگاشت های خود سازمانده
5. زمان محاسبه
6. شبیه سازی و نتایج
7. نتیجه گیری ها
منابع
Abstract
1.Introduction
2. Related Works
3. Linear Programming Formulation
4. K-means, Fuzzy c-means and SOM Algorithms for Web Server Replica Placement
4.1. K-means Clustering for Replica Server Placement
4.2. Fuzzy c-Means Algorithm
4.3. Self Organizing Maps
5. Computational Time
6. Simulation and Result
7. Conclusions
References
- اصل مقاله انگلیسی با فرمت ورد (word) با قابلیت ویرایش
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه