
دانلود مقاله داده های اندک اغلب برای تشخیص داده های پرت مبتنی بر فاصله کافی است
چکیده
تعداد زیادی از مطالعات موردی از آموزش سریع و دفعات پیش بینی سود می برند، و بیشتر تحقیقات به بررسی تسریع روش های تشخیص داده های پرت مبتنی بر فاصله برای میلیون ها نقطه داده می پردازند. یافته های ما برخلاف عقیده عموم نشان می دهند که داده های اندک اغلب برای مدلهای تشخیص داده های پرت مبتنی بر فاصله کافی هستند. ما نشان می دهیم که از بخش کوچکی از داده ها برای آموزش مدلهای تشخیص داده های پرت مبتنی بر فاصله استفاده می شود که اغلب منجر به کاهش غیرمعنی داری در عملکرد پیش بینانه و واریانس تشخیص در محدوده گسترده ای از مجموعه داده های جدولی می شود. علاوه بر این، ما کاهش داده را براساس زیرنمونه گیری تصادفی و نمونه های اولیه مبتنی بر خوشه بندی مقایسه می کنیم و نشان می دهیم که هر دو رویکرد منجر به نتایج تشخیص داده های پرت مشابهی می شوند. بنابراین، زیرنمونه گیری تصادفی ساده ثابت می کند که یک معیار مفید و مبنایی برای تحقیقات آینده در تسریع تشخیص داده های پرت مبتنی بر فاصله است.
1. مقدمه
داده های پرت (outlier) و ناهنجاری (anomaly) دو عبارتی هستند که بیشترین کاربرد را در زمینه تشخیص داده های پرت یا تشخیص ناهنجاری دارند. یک داده پرت اغلب به صورت «یک مشاهده (یا زیرمجموعه یا مشاهدات) تعریف می شود که ناسازگار با بقیه مجموعه داده هستند» [5]. تشخیص داده های پرت حوزه تحقیقاتی است که تشخیص چنین مشاهدات ناسازگاری را مورد مطالعه قرار می دهد. داده های پرت در ماهیت رویدادهایی کمیاب (بعنوان مثال، شرایط پزشکی نادر یا خرابی های دستگاه) هستند، و بدست آوردن برچسب ها اغلب دشوار است. بنابراین، بیشتر الگوریتم های تشخیص داده های پرت در یک محیط غیرنظارت شده عمل می کنند.
4. نتیجه گیری
مبادله بین سوگیری و واریانس یکی از چالش های اصلی یادگیری ماشینی است. استفاده از داده های بیشتر بی اهمیت ترین روش برای کاهش واریانس یک تخمین گر است. با این حال، مبادله ای بین سرعت پیش بینی و یادگیری و عملکرد پیش بینانه وجود دارد که به ویژه در یادگیری بدون نظارت که میزان زیادی از داده ها ممکن است دردسترس باشد، مرتبط است. ما نشان می دهیم که زیرنمونه گیری داده های تصادفی ساده و کاهش داده های مبتنی بر نمونه اولیه استراتژی های ارزشمندی برای تسریع یادگیری و پیش بینی با تحلیل رویکردهای تشخیص داده های پرت مبتنی بر فاصله هستند. در مواردی که تعداد غیرعملی زیادی از همسایگان به بهترین صورت چگالی داده های پرت را توصیف می کنند، کاهش داده به ویژه برای بهبود سرعت پیش بینی و عملکرد پیش بینانه مناسب است. معمولا روش های جدید تقریب برای سرعت بخشیدن به تشخیص داده های پرت مبتنی بر فاصله با استفاده از مجموعه داده های آموزشی کامل بعنوان معیاری برای سرعت و عملکرد ارزیابی می شوند. توسعه دهندگان روش های افزایش سرعت آینده برای تشخیص داده های پرت مبتنی بر فاصله باید شامل زیرنمونه گیری بعنوان یک معیار ساده و خط مبنا باشند.
Abstract
Many real-world use cases benefit from fast training and prediction times, and much research went into speeding up distance-based outlier detection methods to millions of data points. Contrary to popular belief, our findings suggest that little data is often enough for distance-based outlier detection models. We show that using only a tiny fraction of the data to train distance-based outlier detection models often leads to no significant reduction in predictive performance and detection variance over a wide range of tabular datasets. Furthermore, we compare a data reduction based on random subsampling and clustering-based prototypes and show that both approaches yield similar outlier detection results. Simple random subsampling, thus, proves to be a useful benchmark and baseline for future research on speeding up distance-based outlier detection.
1. Introduction
Outlier or anomaly are the two terms most commonly used in the context of outlier detection or anomaly detection. An outlier is frequently defined as ”an observation (or subset of observations) which appears to be inconsistent with the remainder of that set of data” [5]. Outlier detection is the research area that studies the detection of such inconsistent observations. Outliers are by nature infrequent events (e.g., rare medical conditions or machine failures), and labels are often difficult to obtain. Most outlier detection algorithms, therefore, operate in an unsupervised setting.
4. Conclusion
The trade-off between bias and variance is one of the central machine learning challenges. Using more data is the most trivial approach to reduce the variance of an estimator. However, there is also a trade-off between learningand prediction-speed and predictive performance, which is especially relevant in unsupervised learning, where vast amounts of data might be available. We show that simple random data subsampling and prototype-based data reduction are valuable strategies to accelerate learning and prediction with the analyzed distance-based outlier detection approaches. In cases where an impractically large number of neighbors best describes the outlier density, a data reduction is particularly suited to improve prediction speed and predictive performance. Current approximation techniques to accelerate distance-based outlier detection are typically evaluated using the complete training data set as a benchmark for speed and performance. Developers of future speed-up methods for distance-based outlier detection should additionally include random subsampling as a simple benchmark and baseline.

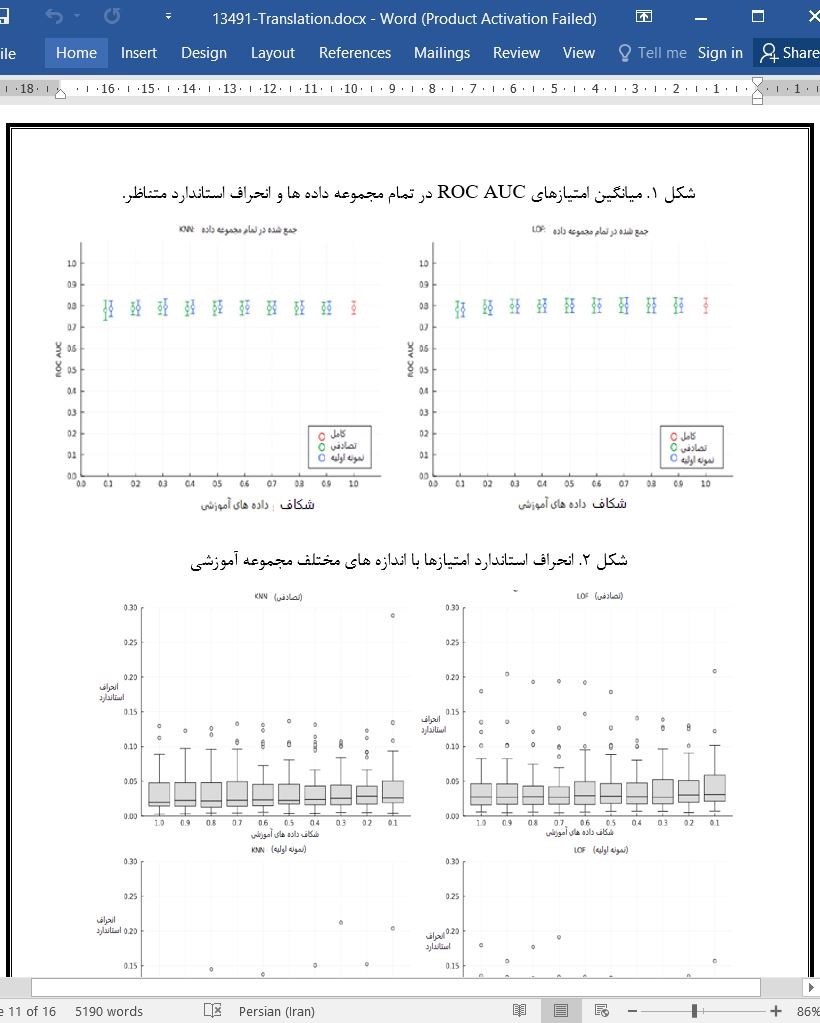

(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1. مقدمه
1.1. تشخیص داده های پرت مبتنی بر فاصله
1.2. روش های تقریبی مبتنی بر فاصله
2. روش شناسی
2.1. مجموعه داده ها
2.2. نمونه گیری و نمونه های اولیه
2.3. الگوریتم ها
2.3.1. k-نزدیکترین همسایگی
2.3.2. عامل پرت محلی
2.4. ارزیابی
3. نتایج
3.1. تاثیر بر عملکرد تشخیص
3.2. تاثیر بر واریانس تشخیص
3.3. مقایسه نمونه گیری تصادفی و نمونه های اولیه
4. نتیجه گیری
منابع
Abstract
1. Introduction
1.1. Distance-based outlier detection
1.2. Approximate distance-based methods
2. Methodology
2.1. Datasets
2.2. Sampling and Prototypes
2.3. Algorithms
2.3.1. k-Nearest Neighbors
2.3.2. Local Outlier Factor
2.4. Evaluation
3. Results
3.1. Effect on detection performance
3.2. Effect on detection variance
3.3. Comparison of random sampling and prototypes
4. Conclusion
References
این محصول شامل پاورپوینت ترجمه نیز می باشد که پس از خرید قابل دانلود می باشد. پاورپوینت این مقاله حاوی 17 اسلاید و 4 فصل است. در صورت نیاز به ارائه مقاله در کنفرانس یا سمینار می توان از این فایل پاورپوینت استفاده کرد.
در این محصول، به همراه ترجمه کامل متن، یک فایل ورد ترجمه خلاصه نیز ارائه شده است. متن فارسی این مقاله در 7 صفحه (1650 کلمه) خلاصه شده و در داخل بسته قرار گرفته است.
علاوه بر ترجمه مقاله، یک فایل ورد نیز به این محصول اضافه شده است که در آن متن به صورت یک پاراگراف انگلیسی و یک پاراگراف فارسی درج شده است که باعث می شود به راحتی قادر به تشخیص ترجمه هر بخش از مقاله و مطالعه آن باشید. این فایل برای یادگیری و مطالعه همزمان متن انگلیسی و فارسی بسیار مفید می باشد.
بخش مهم دیگری از این محصول لغت نامه یا اصطلاحات تخصصی می باشد که در آن تعداد 30 عبارت و اصطلاح تخصصی استفاده شده در این مقاله در یک فایل اکسل جمع آوری شده است. در این فایل اصطلاحات انگلیسی (تک کلمه ای یا چند کلمه ای) در یک ستون و ترجمه آنها در ستون دیگر درج شده است که در صورت نیاز می توان به راحتی از این عبارات استفاده کرد.
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش و pdf بدون آرم سایت ای ترجمه
- پاورپوینت فارسی با فرمت pptx
- خلاصه فارسی با فرمت ورد (word)
- متن پاراگراف به پاراگراف انگلیسی و فارسی با فرمت ورد (word)
- اصطلاحات تخصصی با فرمت اکسل