
دانلود مقاله مثبت بیندیشید: یک شبکه عصبی قابل تفسیر برای بازشناسی تصویر
چکیده
پاندمی COVID-19 همچنان در حال پیشرفت است و هزینه اضافه ای بر سیستمهای بهداشت و درمان در سراسر دنیا تحمیل کرده است. تشخیص به موقع و موثر این ویروس میتواند به کاهش انتشار بیماری کمک کند. گرچه RT-PCR همچنان استانداردی طلایی برای تست COVID-19 بشمار میرود، اما مدلهای یادگیری عمیق برای شناسایی ویروس از روی تصاویر پزشکی نیز در شرایط خاص مفید هستند؛ بویژه در موقعیتهایی که بیماران متحمل آزمایشات پرتو-X و یا CT-اسکنهای روتین میشوند ولی در مدت چند روز پس از این آزمایشات عوارض تنفسی را تجربه میکنند. همچنین مدلهای یادگیری عمیق جهت پیش-غربالگری قبل از آزمایش RT-PCR استفاده میشوند. ولی با اینحال، شفافیت/ قابلیت تفسیر فرایند استدلال پیش بینی های صورت گرفته بوسیله چنین مدلهای یادگیری ضرورت دارد. ما در این مقاله، یک الگوی یادگیری عمیق قابل تفسیر پیشنهاد میکنیم که از فرایند استدلال مثبت جهت پیش بینی استفاده میکند. ما مدل خودمان را آموزش داده و آن را بر روی یک مجموعه از داده های تصویری CT-اسکن قفسه سینه بیماران COVID-19، افراد سالم، و بیماران پنومونی، آزمایش کردیم. صحت، دقت، یادآوری و امتیازF- مدل ما به ترتیب 48/99 %، 99/0، 99/، و 99/0 بودند.
1-مقدمه
پاندمی COVID-19 همچنان در حال انتشار سویه های متعددی در سیستمهای بهداشت عمومی سراسر دنیا میباشد و به شدت، اقتصاد چندین کشور را تحت تاثیر قرار داده است. گرچه در حال حاضر واکسیناسیون علیه این ویروس در حال انجام است، اما تعداد واریته های ویروس نیز روبه افزایش هستند. واریته های جدید ویروس میتوانند کارایی واکسنها را کاهش دهند (WHO, 2021). بنابراین علاوه بر واکسیناسیون علیه این ویروس، تشخیص ویروس جهت کاهش انتشار بیماری و توسعه جهش های ویروس اهمیت دارد. علاوه بر تکنیک آزمایشی رایج واکنش زنجیرۀ پلیمراز با رونویسی معکوس (RT-PCR)، الگوهای یادگیری عمیق نیز در تلاش برای تشخیص ویروس مفید هستند. اکثر الگوریتمهای یادگیری بصورت یک جعبه سیاه عمل میکنند زیرا فرایند استدلال آنها برای پیش بینی، شفاف/ قابل تفسیر نیست. ولی تفسیر فرایند استدلال یک الگوی یادگیری عمیق مرتبط با یک تصمیم پُرخطر، اهمیت دارد. مواردی پیش می آمد که در آنها، داده های متعدد تغذیه شده به مدلهای جعبه سیاه مورد توجه قرار نمی گرفتند و به همین دلیل، محکومیتهای حبس بلندمدت غیرقانونی برای افراد صادر میشد (مثل، مورد زندانی Glen Rodriguez که بخاطر ارائه نمره COMPAS اشتباه، از حق آزادی مشروط محروم شد) (Li, Liu, Chen, Rudin, 2017; Wexler, 2017). عدم قابلیت تفسیر فرایندهای استدلال چنین الگوهای یادگیری عمیقی به مساله ای عمده تبدیل شده است از اینکه آیا ما میتوانیم به پیش بینی های دقیقی اعتماد کنیم که از این الگوها نشات میگیرند یا خیر. بنابراین ما یک مدل یادگیری عمیق قابل تفسیر تحت عنوان شبکه شناسایی بخشهای شبیه الگوی اولیه (Quasi-ProtoPNet) پیشنهاد میکنیم و این مدل را آموزش داده و برای مجموعه داده ای از تصاویر CT–اسکن قفسه سینه آزمایش میکنیم.
6-نتیجه گیری
استفاده از فرایند استدلال مثبت همراه با کاربرد الگوها با ابعاد فضایی مستطیلی و مربعی، به مدل ما کمک کرده است تا عملکردش را نسبت به سایر سری مدلهای ProtoPNet بهبود بخشد. همچنین همانطور که در بخش 3.2 اشاره شد، مدل Quasi-ProtoPNet بیشترین صحت (48/99%) را هنگام استفاده از DenseNet-121 بعنوان مدل پایه ارائه میدهد و بیشترین صحت محاسبه شده با مدل Quas-ProtoPNet برابر با بیشترین صحت (48/99 %) تعیین شده با مدل تفسیرناپذیر DenseNet-161 است.
Abstract
The COVID-19 pandemic is an ongoing pandemic and is placing additional burden on healthcare systems around the world. Timely and effectively detecting the virus can help to reduce the spread of the disease. Although, RT-PCR is still a gold standard for COVID-19 testing, deep learning models to identify the virus from medical images can also be helpful in certain circumstances. In particular, in situations when patients undergo routine -rays and/or CT-scans tests but within a few days of such tests they develop respiratory complications. Deep learning models can also be used for pre-screening prior to RT-PCR testing. However, the transparency/interpretability of the reasoning process of predictions made by such deep learning models is essential. In this paper, we propose an interpretable deep learning model that uses positive reasoning process to make predictions. We trained and tested our model over the dataset of chest CT-scan images of COVID-19 patients, normal people and pneumonia patients. Our model gives the accuracy, precision, recall and F-score equal to 99.48%, 0.99, 0.99 and 0.99, respectively.
1. Introduction
The pandemic COVID-19 is placing enormous strain on public health systems around the world, and severely affecting the economies of many countries. Although, vaccination is being done for the virus, but the number of the variants of the virus is also increasing. The new variants of the virus can reduce the effectiveness of the vaccines (WHO, 2021). Therefore, along with vaccination for the virus, detection of the virus is important to reduce the spread of the disease and the development of mutants of the virus. In addition to the prevalent testing technique reverse transcription polymerase chain reaction (RT-PCR), deep learning models can also be helpful in efforts to detect the virus. Most of the deep learning algorithms work as a black-box because their reasoning process for their predictions is not transparent/interpretable. However, the interpretation of the reasoning process of a deep learning model related to a high stake decision is important. There have been cases where erroneous data fed into the black-box models went unnoticed, due to which wrongful long prison sentences were given (e.g., inmate Glen Rodriguez was denied parole because of wrong COMPAS score) (Li, Liu, Chen, & Rudin, 2017; Wexler, 2017). The lack of interpretability of the reasoning processes of such deep learning models has become a major issue for whether we can trust predictions that are coming from these models. Therefore, we propose an interpretable deep learning model quasi prototypical part network (Quasi-ProtoPNet), and trained and tested the model over the dataset of chest CT images.
6. Conclusions
The use of positive reasoning process along with the use of prototypes with rectangular spatial dimensions and square spatial dimensions helped our model to improve its performance over the series of the other ProtoPNet models. Moreover, as observed in Section 3.2, Quasi-ProtoPNet gives the highest accuracy (99.48%) when DenseNet-121 is used as the base model, and the highest accuracy given by Quasi-ProtoPNet is equal to the highest accuracy (99.48%) given by the non-interpretable model DenseNet-161.


(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1-مقدمه
1.2-مجموعه داده
1.3-دستاوردها
2-روش
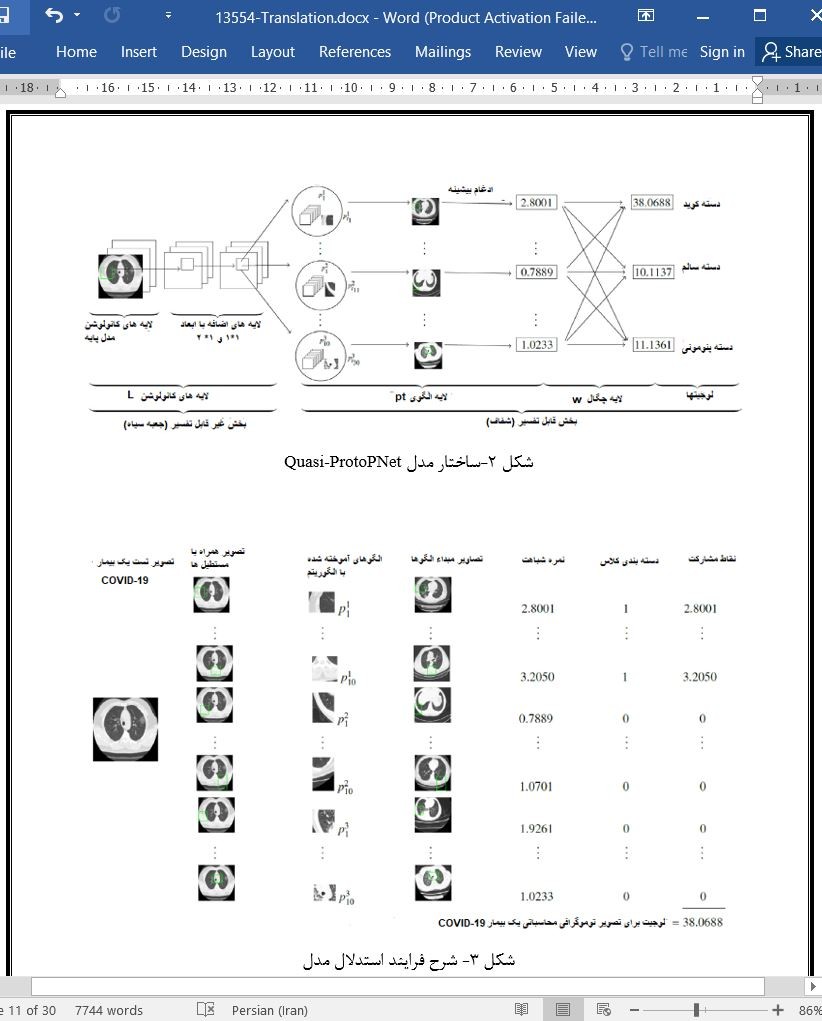
2.1-ساختار مدل Quasi-ProtoPNet
2.2-آموزش مدل Quasi-ProtoPNet
2.2.1- بهینه سازی تمام لایه ها قبل از لایه چگال
2.2.2- تصویرسازی الگوها
2.3-شرح مدل Quasi-ProtoPNet
3- نتایج
3.1-شاخص ها و ماتریسهای درهمریختگی
3.2-مقایسه عملکرد روشها
3.3-آزمایش فرضیه برای مقادیر صحت مدلها
3.4-مقایسه صحتها از روی نمودار
3.5-اثر تصویرسازی الگوها
4-نقاط ضعف مطالعه ما
6-نتیجه گیری
منابع
Abstract
1. Introduction
1.1. Related work
1.2. Dataset
1.3. Contributions
2. Method
2.1. Quasi-ProtoPNet architecture
2.2. Training of Quasi-ProtoPNet
2.2.1. Optimization of all layers before the dense layer
2.2.2. Projection of prototypes
2.3. Explanation of Quasi-ProtoPNet
3. Results
3.1. The metrics and confusion matrices
3.2. The performance comparison of the models
3.3. The test of hypothesis for the accuracies
3.4. The graphical comparison of the accuracies
3.5. The effect of the projection of prototypes
4. Limitations
5. Discussion
6. Conclusions
Declaration of Competing Interest
Acknowledgment
References
Hide outline
این محصول شامل پاورپوینت ترجمه نیز می باشد که پس از خرید قابل دانلود می باشد. پاورپوینت این مقاله حاوی 29 اسلاید و 6 فصل است. در صورت نیاز به ارائه مقاله در کنفرانس یا سمینار می توان از این فایل پاورپوینت استفاده کرد.
در این محصول، به همراه ترجمه کامل متن، یک فایل ورد ترجمه خلاصه نیز ارائه شده است. متن فارسی این مقاله در 11 صفحه (1850 کلمه) خلاصه شده و در داخل بسته قرار گرفته است.
علاوه بر ترجمه مقاله، یک فایل ورد نیز به این محصول اضافه شده است که در آن متن به صورت یک پاراگراف انگلیسی و یک پاراگراف فارسی درج شده است که باعث می شود به راحتی قادر به تشخیص ترجمه هر بخش از مقاله و مطالعه آن باشید. این فایل برای یادگیری و مطالعه همزمان متن انگلیسی و فارسی بسیار مفید می باشد.
بخش مهم دیگری از این محصول لغت نامه یا اصطلاحات تخصصی می باشد که در آن تعداد 50 عبارت و اصطلاح تخصصی استفاده شده در این مقاله در یک فایل اکسل جمع آوری شده است. در این فایل اصطلاحات انگلیسی (تک کلمه ای یا چند کلمه ای) در یک ستون و ترجمه آنها در ستون دیگر درج شده است که در صورت نیاز می توان به راحتی از این عبارات استفاده کرد.
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش و pdf بدون آرم سایت ای ترجمه
- پاورپوینت فارسی با فرمت pptx
- خلاصه فارسی با فرمت ورد (word)
- متن پاراگراف به پاراگراف انگلیسی و فارسی با فرمت ورد (word)
- اصطلاحات تخصصی با فرمت اکسل