
دانلود مقاله سیستم تشخیص نفوذ در محاسبات ابری توزیع شده
چکیده
محاسبات ابری، امروزه به سبب سرویس های ذخیره سازی و دستیابی داده، بسیار مشهور شده است. امنیت و حریم خصوصی، از جمله مسائل و نگرانی های اولیه، در زمانی هستند که تهدیدهای شبکه افزایش یافته باشد. محاسبات ابری، سازمان ها و تشکیلات اقتصادی را به صورت مقیاس پذیر، انعطاف پذیر و زیر ساخت های مقرون به صرفه برای ذخیرة داده ها در وب، ارائه می دهد. یک ناهنجاری مبتنی بر پیاده سازی IDS، از ادغام داده ها در یک مجموعه داده محافظت می نماید و این کار با شناسایی و قرنطینه کردن موارد ثبت شده، در زمانی قابل انجام است که به طور غیر قابل انتظاری، تغییر در چیزی ظاهر شده باشد. یادگیری ماشین، مبتنی بر روش های خوشه بندی و طبقه بندی است که برای ناهنجاری ایجاد شده به سبب طبقه بندی حمله IDS و مقیاس پذیری در محیط های شبکه های پیشرفته، به کار رفته است. یادگیری ماشین، یک رویکردی سریع، کارآمد و وفقی برای توسعة مدل های تشخیص گسترش نفوذ به شمار می رود که می تواند در مقابل تهدیدهای اضطراری، حملات ( اتک های ) شناخته شده و ناشناخته ( شامل حملات صفر روزه)، قد علم کند. این مقاله، یک مدل طبقه بندی و خوشه بندی کارآمد هیبریدی ( ترکیبی ) برای پیاده سازی ناهنجاری مبتنی بر IDS و برای حالات مخرب طبقه بندی، ارائه می دهد. که این طبقه بندی می تواند به این صورت باشد: معمولی ( بدون نفوذ)، DOS، پراب، U2R و R2L، با استفاده از توابع مبتنی بر آستانه و نتایج با دو مقدار آستانة متفاوت 0/5 , 0/01 تست شده است. آزمایشات روی دو پایگاه داده تست، انجام گرفته است و تحت نام های NSL-KDD,KDD cup99 می شود. نرخ تشخیص، نرخ هشدار کاذب و دقت برای پژوهش عملیاتی در مورد روش شناسی پیشنهاد شده، به کار رفته است.پس از اعمال رویکرد پیشنهادی، K-mean با جنگل تصادفی در دو مقدار آستانه متفاوت، نشان داده شده است و دقت طبقه بندی و نرخ تشخیص بهتر دارد و نرخ هشدار کاذب دارد که به ترتیب 85/99 % و 78/99 % و 09/0 % روی مجموعه داده NSL-KDD و روی مجموعه داده KDD Cup 99 به ترتیب 27/98 % ، 12/98 % و 08/2 % می باشد.
1- مقدمه
سیستم های تشخیص نفوذ مبتنی بر شبکه ابری از روش مبتنی بر ناهنجاری برای امنیت برنامه های مبتنی بر ابر استفاده می کنند. دریک شبکه ابری، چندین نوع حمله روی برنامة های سرویس، وجود دارد که مثل حملات حالت و پروتکل، حملات حجمی انکار سرویس [1] و رمزنگاری یا حملات ورودی مخرب می باشد. اعمال نفوذ یا تهدیدات در شبکه سیستم، امنیت و محرمانگی سیستم را به خطر می اندازد. یک دفاع معمول در مقابل حملات، به عنوان یک سیستم تشخیص نفوذ شناخته می شود که فعالیت های مشکوک و نفوذ را پیش از وقوع هرگونه خسارت، شناسایی خواهد کرد. به عنوان مثال، یک سیستم تشخیص نفوذ، در زیرساخت ابری استفاده شده است و یک سیستم هشدار اولیه، در مقابل نفوذ و پیامدهای آن، می باشد. IDS در زیرساخت های ابری، چالش هایی مثل مثبت کاذب و هزینة بالای به کارگیری سیستم IDS بزرگ را ارائه می دهد. دو نوع معمول IDS وجود دارد: مبتنی بر شبکه و مبتنی بر هاست (میزبان). که به شناسایی منابع نفوذ و پاسخ به آنها می پردازد [2]. تکنیک های تشخیص ناهنجاری، قابلیت شناسایی گونه های پیشین غیر قابل دید از حمله را دارند. عدم تنظیم خودکار و شیوع مثبت کاذب، دو مسألة اصلی است. به منظور تشخیص حملات در مقیاس بزرگ، محیط های چند ابری توزیع شده، تعدادی قوانین پیچیده مطرح می شوند که می بایست مورد پیکربندی قرار گیرند [3].
روش های خوشه بندی و طبقه بندی، برای استفاده در تشخیص نفوذ، بسیار توصیه شده است. در طی سال های اخیر، توسعه های معناداری از تکنیک های خوشه بندی و طبقه بندی معرفی شده است که به طور خودکار، حملات جدید را بدون مداخلة انسانی تشخیص می دهند. به همین دلیل، استفاده از یادگیری ماشین برای ایجاد IDS ها ضروری است و تهدیدهای غیر قابل رویت پیشین را هم شناسایی می کند. تاثیر این سیستم ها تا حد بالایی متکی بر تنظیم دقت مدل بوده و روشی برای نظارت حملات و تکامل روش ها در طی زمان، ارائه می کند NSL-KDD [4]. مکانیسم را برای خوشه بندی و طبقه بندی ارائه می دهد که می تواند در IDS مشارکت داشته باشد و قابلیت کشف خودکار و تهدیدهای غیر قابل رویت پیشین، حملات انکار سرویس (DoS)، U2R,R2L ( کار بر حملة روت) و کاوش [3] را در بردارد. همکاری اولیة این پژوهش، مربوط به ساخت یک سیستم تشخیص نفوذ است که از خوشه بندی ترکیبی و رویکردهای طبقه بندی استفاده کرده و با دو مقدار آستانة جایگزین تست گردیده و روی دو مجموعه داده معیار ارزیابی شده بود و برای رسیدگی به مسائل تشخیص ناهنجاری در یک محیط محاسبات ابری توزیع شده، به کار می رود.
6- نتیجه گیری
از نتایج و تحلیل های تجربی می توان نتیجه گرفت که مدل پیشنهادی به حد کافی در تشخیص حملات متفاوت روی محیط ابری، کارایی دارد. مجموعه داده های معیار NSL-KDD,KDD 99IDS در آزمایشات و برای ارزیابی روش های خوشه بندی GMM,K-mean و در ارتباط با طبقه بند RF به کار می رود. هدف از این تحقیق، پیکربندی و یافتن حملات مخرب روی شبکه ابری در زمان واقعی است. بنابراین به پایداری و امنیت شبکه کمک کرده و این اتفاقات، اغلب رخ می دهند. در گسترش یک IDS موثر با نرخ هشدار کاذب پایین، مدل پیشنهادی ما نتایج را مبتین بر نقاط آستانه مقیاس بندی شده مثل 5/0 تا 001 نشان می دهد که در آن، آستانه به اندازه 5/0 روی خوشه بندی Kmean با نرخ تشخیص بهره جنگل تصادفی 78/99 درصد و نرخ هشدار کاذب 9/0 درصد تنظیم می شود. مقدار آستانه روی 1/0 برای داده تست قرار می گیرد. این روش، یک DR برای 33/94 درصد و FAR ، 12/14 درصد دارد. KDD cup 99 با استفاده از همین مدل، پیاده سازی می شود. علاوه براین، این مقاله روش طبقه بند ترکیبی یا هیبریدی با ناظر را برای شناسایی و طبقه بندی حملات فردی پیاده سازی کرده است. نتایج، اثبات می کنند که طبقه بندی جنگل تصادفی، بهترین عملکرد را برای شناسایی و برچسب گذاری DoS و حملات نرمال با دقت بالا، FAR پایین، DR بالا و AUC بالا دارند. تحقیقات آینده روی روش های اصلاحی شبکه مدل سازی ترافیک و رفتار حمله، انجام خواهند شد و بهترین عملکرد را در پارامترها و حملات تکی، بررسی می کنند.
Abstract
Cloud Computing is popular nowadays due to its storage and data access services. Security and privacy are prime concerns when network threats increase. Cloud computing offers organizations and enterprises a scalable, flexible, and cost-effective infrastructure to store data on the Web. An anomaly-based IDS implementation protects the integrity of the data in a database by identifying and quarantining records when something appears to have changed unexpectedly. Machine learning based clustering and classification methods are used for anomaly based IDS attack classification and scalability in advanced networking environments. Machine learning is a fast, efficient, and adaptable approach to develop intrusion detection models that can deal with emerging threats, i.e., known and unknown attacks (including zero-day attacks). This paper proposes an efficient Hybrid clustering and classification models for implementing an anomaly-based IDS for malicious attack type classifications such as normal (no intrusion), DoS, Probe, U2R, and R2L using threshold-based functions, and the results are tested with two different threshold values (e), 0.01 & 0.5. The experiments have been performed on two tested datasets, namely, NSL-KDD and KDDcup99. Detection rate, False alarm ratio, and accuracy have been used to study the performance of the proposed methodology. After applying the proposed approach, the K-means with random forest has been shown at two different threshold values to have a better classification accuracy, detection rate, and false alarm rate of 99.85%, 99.78% and 0.09% on the NSL-KDD dataset and 98.27%, 98.12% and 2.08% respectively on the KDDcup99 dataset.
1. Introduction
Cloud network-based Intrusion Detection Systems (IDS) use anomaly-based methods to secure cloud-based applications. In a cloud network, there are many types of attacks on service applications, such as state and protocol attacks, volumetric Denial-of-Service (DoS) attacks [1], and encrypted or malicious input attacks. Injecting intrusions or threats into the system’s network compromises its security and confidentiality. A common defense against attacks is known as an Intrusion Detection System (IDS), which will detect suspicious activities and intrusions before any damage is done. For example, an Intrusion Detection System (IDS) is used in cloud infrastructure as an early-warning system against intrusion and its consequences. IDS in cloud infrastructures present challenges such as false positives and the high cost of deploying large IDS systems. There are two common types of IDS: network-based and host-based, which detect and respond to intrusions [2]. Anomaly detection techniques have the ability to identify previously unseen forms of attack. The lack of automatic tuning and the prevalence of false positives are two major issues. In order to detect attacks in large-scale, distributed multi-cloud environments, a number of complicated rules must be configured [3].
Clustering and classification methods are highly recommended for use in intrusion detection. In the last few years, there has been significant development of clustering and classification techniques that can automatically detect new attacks without human intervention. This is why it makes sense to use machine learning to create IDSs that can detect previously unseen threats. The effectiveness of these systems is highly reliant on accurate model tuning and a method for monitoring how attacks are evolving over time. NSL-KDD [4] provides the mechanism for clustering and classification that can be incorporated into IDS to enable the automated discovery of previously unseen threats. i.e., Denial of Service attacks (DoS),R2L, U2R (User to Root Attack), probe, normal [5]. The primary contribution of this study is to built an intrusion Detection System utilizing hybrid clustering and classification approaches, tested with two alternative threshold values, and evaluated on two benchmark datasets to handle anomaly detection problems in a distributed cloud computing environment.
6. Conclusion
From the empirical results and analyses, it can be concluded that the proposed model is efficient enough in detecting various attack types on a cloud environment. The NSL-KDD and KDD99 IDS benchmark datasets were used in an experiment to evaluate the GMM and K-Means clustering methods in conjunction with the RF Classifier. The goal of this research is to confirm and find malicious attacks on the cloud network in real time. This will help the network to stable and safe even though these attacks happen often. In developing an effective IDS with a low false alarm rate, our proposed model shows the result based on scaled threshold points such as 0.5 to 001, i.e., where the threshold is set to 0.5 K-Means clustering with an RF gain detection rate of 99.78% and a false alarm rate of 0.9%. The threshold was set at 0.01 on test data. The detection rate was 98–99% with a 14–15% false alarm rate. Similarly, for GMM with RF Classifiers, with a DR of 99.7% of training data and a FAR of 0.5%, The threshold was set at 0.01 for the test data. This method has a DR of 94.33% and a FAR of 14.12%. KDDcup99 has also been implemented using the same model. Furthermore, this paper implemented a supervised hybrid classifier method for identifying and categorizing individual attacks; the results demonstrated that the random forest classifier performed best for identifying and labeling DoS and normal attacks with high accuracy, low FAR, high DR, and high AUC. Future research will be conducted on more refined methods of modeling network traffic and attack behavior that best represents the parameters of individual attacks.


(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1- مقدمه
2- پیش زمینه
3-1 مدل مخلوط گاوسی kmean (GMM)
3- کار مرتبط
4- روش شناسی
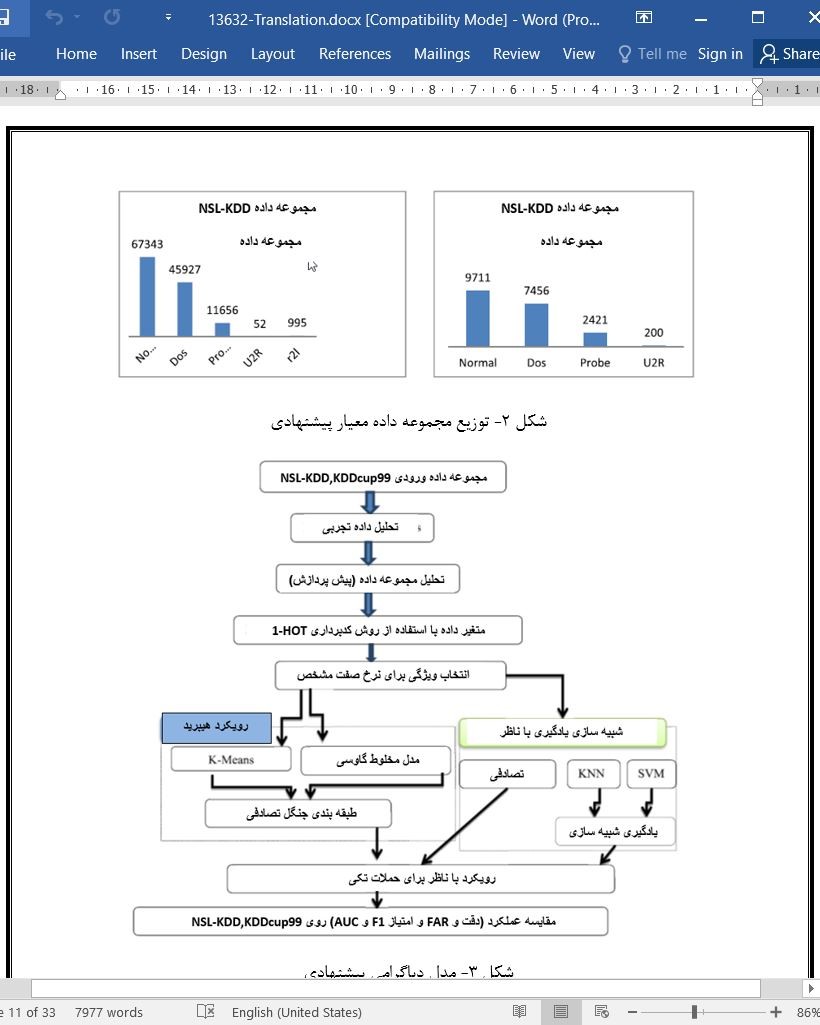
4-1 مجموعه داده
4-2 مدل پیشنهادی
4-2-1 تحلیل داده های تجربی
4-2-2پیش پردازش داده
4-2-3 متغیر گروه بندی داده با استفاده از یک روش کدگذاری 1- hot
4-2-2 انتخاب ویژگی با استفاده از نسبت ویژگی
4-2-5- رویکرد هیبرید (ترکیبی) K-mean و جنگل تصادفی
4-2-6 خوشه بندی k-mean
4-2-7 یک مدل مخلوط گاوسی
4-2-8. طبقه بند جنگل تصادفی
4-3 معناداری کار پیشنهادی
5- نتایج و تحلیل ها
5-1 تحلیل داده های تجربی
5-2 آماده سازی داده
5-3 معیار ارزیابی نتایج
5-4 پیاده سازی خوشه بندی Kmean با طبقه بندهای جنگل تصادفی
5-4-1 خوشه بندی Kmean
5-5 خوشه بندی مخلوط گاوسی با طبقه بندهای جنگل تصادفی روی مجموعه داده NSL-KDD
6- نتیجه گیری
اعلام منافع رقابتی
قابلیت دسترسی داده
مراجع
Abstract
1. Introduction
2. Background
2.1. K-means VS Gaussian Mixture Model (GMM)
3. Related work
4. Methodology
4.1. Dataset
4.2. Proposed model
4.2.1. Empirical Data Analysis
4.2.2. Data preprocessing
4.2.3. Data categorical variable using 1-hot coding method
4.2.4. Feature Selection using Attribute Ratio
4.2.5. Hybrid approach K-means and random forest (RF)
4.2.6. K-means clustering
4.2.7. A Gaussian mixture model (GMM)
4.2.8. Random forest (RF) classifier
4.3. Significance of the proposed work
5. Result and analysis
5.1. Empirical Data Analysis
5.2. Data preparation
5.3. Metrics to evaluate the results
5.4. Implementation of KMeans clustering with Random Forest Classifiers
5.4.1. KMeans clustering
5.5. Gaussian Mixture clustering with Random Forest Classifiers on NSL-KDD dataset
5.6. Classification of individual attacks using hybrid classifiers on benchmark datasets
6. Conclusion
Declaration of competing interest
Data availability
References
این محصول شامل پاورپوینت ترجمه نیز می باشد که پس از خرید قابل دانلود می باشد. پاورپوینت این مقاله حاوی 21 اسلاید و 6 فصل است. در صورت نیاز به ارائه مقاله در کنفرانس یا سمینار می توان از این فایل پاورپوینت استفاده کرد.
در این محصول، به همراه ترجمه کامل متن، یک فایل ورد ترجمه خلاصه نیز ارائه شده است. متن فارسی این مقاله در 9 صفحه (1700 کلمه) خلاصه شده و در داخل بسته قرار گرفته است.
علاوه بر ترجمه مقاله، یک فایل ورد نیز به این محصول اضافه شده است که در آن متن به صورت یک پاراگراف انگلیسی و یک پاراگراف فارسی درج شده است که باعث می شود به راحتی قادر به تشخیص ترجمه هر بخش از مقاله و مطالعه آن باشید. این فایل برای یادگیری و مطالعه همزمان متن انگلیسی و فارسی بسیار مفید می باشد.
بخش مهم دیگری از این محصول لغت نامه یا اصطلاحات تخصصی می باشد که در آن تعداد 50 عبارت و اصطلاح تخصصی استفاده شده در این مقاله در یک فایل اکسل جمع آوری شده است. در این فایل اصطلاحات انگلیسی (تک کلمه ای یا چند کلمه ای) در یک ستون و ترجمه آنها در ستون دیگر درج شده است که در صورت نیاز می توان به راحتی از این عبارات استفاده کرد.
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش و pdf بدون آرم سایت ای ترجمه
- پاورپوینت فارسی با فرمت pptx
- خلاصه فارسی با فرمت ورد (word)
- متن پاراگراف به پاراگراف انگلیسی و فارسی با فرمت ورد (word)
- اصطلاحات تخصصی با فرمت اکسل