
تحلیل تشخیصی برای شناسایی داده های پرت در تجزیه و تحلیل کلان داده ها
چکیده
به تازگی تجزیه و تحلیل کلان داده ها به یکی از موضوعات نوپدیدار در حوزه ی بازرگانی تبدیل شده است. داده ها گردآوری، پردازش، و تحلیل می شوند تا بینش های سودمندی درباره ی سازمان به دست دهند. تجزیه و تحلیل کلان داده ها از این قابلیت برخوردار است تا کیفیت زندگی را بهبود ببخشد و به دستیابی به آرمان های توسعه ی پایدار (SDG) کمک کند. برای اطمینان از تحقق آرمان های توسعه ی پایدار، ما باید با استفاده از داده های موجود، آن آرمان ها را برآورده کنیم و مسئولیت پذیری را تضمین نماییم. با وجود این، کیفیت داده اغلب در هنگام سروکار داشتن با داده ها نادیده گرفته می شود. هر گونه خطایی که در مجموعه داده پدیدار می شود می بایستی به درستی حل و فصل شود تا بدین وسیله اطمینان حاصل کنیم که تحلیل ارائه شده درست و قابل اطمینان است. در این مقاله، ما به مفهوم تشخیص کیفیت داده پرداخته ایم تا داده های پرت پدیدار شده در مجموعه داده ها را شناسایی نمایم. علت وجود داده-های پرت نیز مورد بحث قرار می گیرد تا بهبودهای بالقوه ای را که می توان در مجموعه داده اعمال کرد، شناسایی کنیم. افزون بر این، توصیه هایی برای بهبود کیفیت داده ها و سامانه های گردآوری داده ها فراهم خواهد شد.
1- مقدمه
در سال های اخیر، کلان داده ها و تجزیه و تحلیل داده ها در بسیاری از حوزه ها همچون بهداشت و درمان، مالیه، و خرده فروشی به طور شایانی مورد توجه قرار گرفته است. مزایای تجزیه و تحلیل کلان داده ها به یک گونه ی ویژه از صنعت محدود نمی شود چون تجزیه و تحلیل برای پیشی گرفتن سازمان ها از رقبا حیاتی قلمداد شده است. علاقه ی در حال گسترش برای اتخاذ تصمیم بر پایه ی داده ها، اهمیت پیش بینی دقیق و صحیح را نشان می دهد. دستورکار برای آرمان های توسعه ی پایدار در راستای شعار 'کسی را پشت سر نگذارید' [1] مستلزم یک سرمایه گذاری اساسی در زمان و منابع است. برای تضمین دستیابی به این دستورکار، کلان داده ها یکی از مولفه های مهم انگاشته می شود که می تواند نابرابری ها در جامعه را که پیش تر پنهان بودند، آشکار کند. برخی پژوهش های انجام شده نشان داده اند که 65 شاخص توسعه ی پایدار می تواند به طور مستقیم یا عیرمستقیم از منابع کلان داده ها بهره جویند [2]. استفاده از تجزیه و تحلیل کلان داده ها دارای این قابلیت است که به سازمان ها کمک کند تا فرصت ها در پشتیبانی از آرمان های توسعه ی پایدار را تحقق بخشند، در عین حال که اهداف رشد را از طریق گستره ای از مزایا در فعالیت های تجاری گوناگون، ازجمله فعالیت های زنجیره ی تأمین [3]، مورد توجه قرار دهند.
Abstract
Recently, Big Data analytics has been one of the most emerging topics in the business field. Data is collected, processed and analyzed to gain useful insight for their organization. Big Data analytics has the potential to improve the quality of life and help to achieve Sustainable Development Goals (SDG). To ensure that SDG goals are achieved, we must utilize existing data to meet those targets and ensure accountability. However, data quality is often left out when dealing with data. Any types of errors presented in the dataset should be properly addressed to ensure the analysis provided is accurate and truthful. In this paper, we have addressed the concept of data quality diagnosis to identify the outlier presented in the dataset. The cause of the outlier is further discussed to identify potential improvements that can be done to the dataset. In addition, recommendations to improve the quality of data and data collection systems are provided.
1. Introduction
In recent years, Big Data and data analytics has become exceptionally valuable in many areas such as health, finance and retail. The benefits of Big Data analytics are not restricted to a specific type of industry since analytics has proven vital for organisations to stay on top its competitors. The growing enthusiasm for making a decision based on data creates the importance of accurate and precise prediction. Agenda for Sustainable Development Goals (SDG) demands a significant investment in time and resources because of its call to ‘leave no one behind’ [1]. To ensure this agenda is achieved, Big Data is seen as one of the important elements that can unravel the disparities in society that were previously hidden. There has been some research conducted shown that 65 SDG indicators could directly or indirectly benefit from Big Data sources [2]. The use of Big Data analytics has the potential to help organisations to realize the opportunities in supporting SDG, while at the same time targeting growth through a range of advantages in various business activities, including supply chain activities [3].

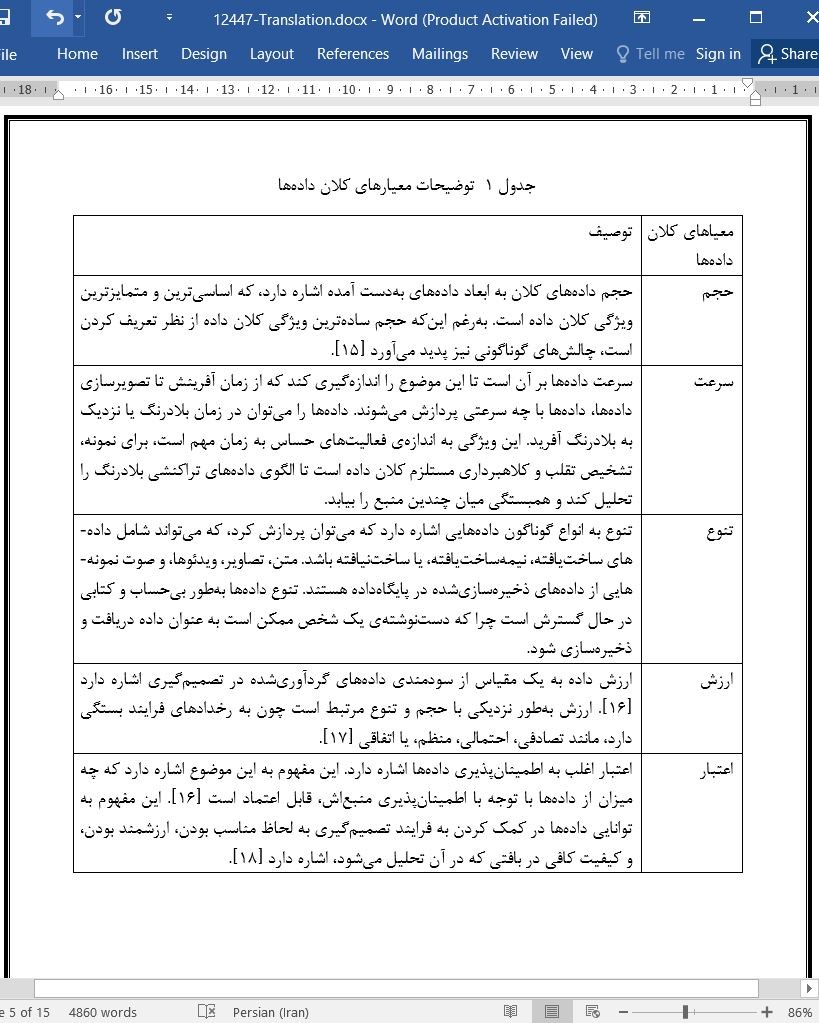

(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1- مقدمه
2- مرور پیشینه
2-1 تعریف کلان داده
2-2 کیفیت داده
2-3 داده پرت
3- تشخیص کیفیت داده ها
4- بحث
5- نتیجه گیری
منابع
Abstract
1. Introduction
2. Literature review
2.1. Definition of big data
2.2. Data quality
2.3. Outlier
3. Data quality diagnosis
4. Discussion
5. Conclusion
References
- اصل مقاله انگلیسی با فرمت ورد (word) با قابلیت ویرایش
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه