
دانلود مقاله جستجوی فضای طراحی شتاب دهنده های FPGA برای شبکه های عصبی پیچشی
چکیده
افزایش استفاده از الگوریتم های یادگیری ماشین، مانند شبکه های عصبی پیچشی (CNNها)، باعث می شود که روش شتابدهنده های سخت افزاری بسیار جالب باشد. اما، به سوالی در مورد چگونه طراحی بهتر یک شتابدهنده برای یک CNN مورد نظر، حتی در یک سطح بنیادی هنوز پاسخ داده نشده است. این مقاله این چالش را با فراهم کردن یک چارچوب جدید که می تواند بطور جهانی و دقیق انتخاب های معماری مختلف برای شتابدهنده-های CNN در FPGAها را ارزیابی و جستجو کند رفع می کند. چارچوب جستجوی ما گسترده تر از هر کار قبلی برحسب فضای طراحی است و منابع FPGA مختلف را برای بیشینه سازی عملکرد شامل منابع DSP، پهنای باند حافظه درون تراشه و حافظه بیرون تراشه درنظر می گیرد. نتایج تجربی ما با استفاده از بزرگترین مدل های CNN شامل مدلی که 16 لایه پیچشی دارد کارآمدی چارچوب ما و همچنین نیاز به چنین روش جستجوی معماری سطح بالا برای یافتن بهترین معماری برای یک مدل CNN را نشان می دهد.
1- مقدمه
شبکه های عصبی پیچشی (CNNها) برای یک محدوده گسترده از مسائل یادگیری ماشین مانند طبقه بندی شیء و بخش بندی معنایی استفاده می شوند ]1،2[. عملکرد تشخیص گفتار پیشرفته آن ها و همچنین پیچیدگی محاسباتی بسیار بالا آن ها را یک هدف بسیار جذاب برای تسریع سخت افزار می گرداند. مخصوصا،FPGAها، بنابر قابلیت برنامه ریزی مجدد، یک پلتفرم انتخاب برای بسیاری از CNNهای مقیاس بزرگ می باشند ]3-8[.
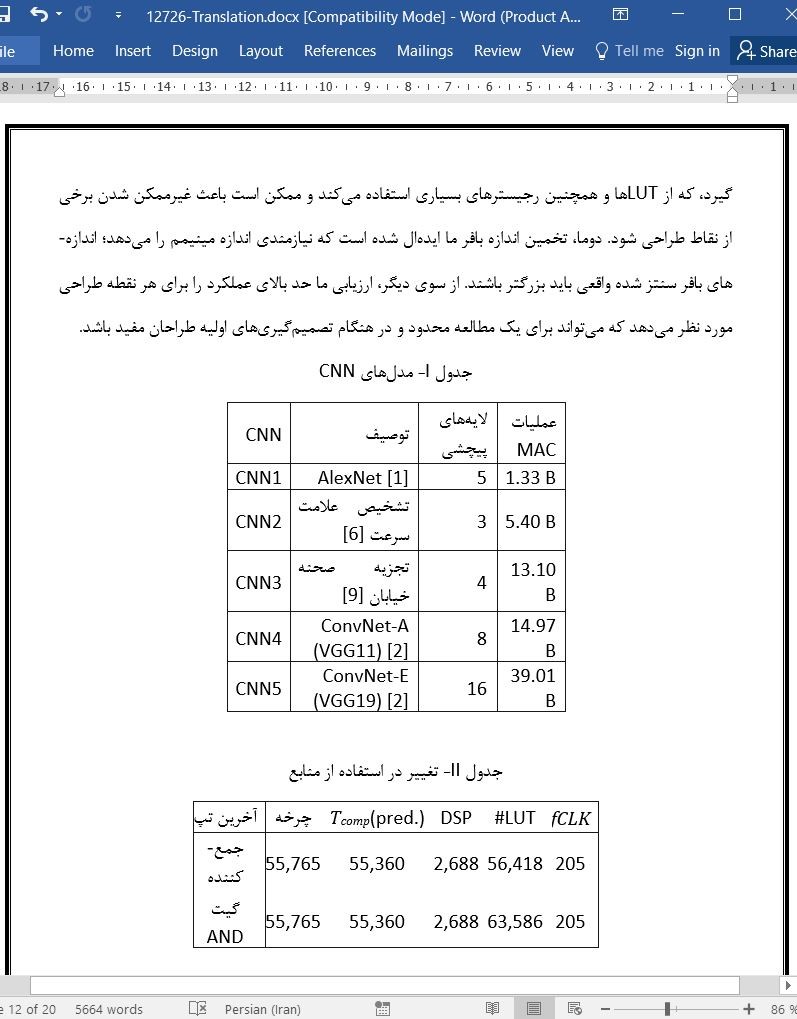
مساله تسریع شبکه های عصبی پیچشی مربوط به تسریع لایه های پیچشی است چونکه آن ها برای بیشتر پیچیدگی محاسباتی درنظر گرفته می شوند.
6-نتیجه گیری
ما یک روش جستجوی معماری را با هدف قرار دادن شتابدهنده های CNN در FPGAها ارائه کردیم. برخلاف کار قبلی که اغلب با یک معماری خاص محدود بود، روش ما یک ارزیابی سریع معماری های معتبر بسیاری را فراهم می کند که ما آن را در یافتن بهترین معماری که مناسب با کاربرد مد نظر است ضروری می بینیم. چارچوب جستجوی ما نه تنها گسترده است بلکه برحسب استفاده از منابع سخت افزاری مانند منابع DSP، حافظه درون تراشه، و پهنای باند خارج تراشه نیز بهینه می باشد. ما اثربخشی چارچوب خودمان را از طریق آزمایشات با استفاده از برخی از مدل های CNN هدف نشان داده ایم، که نیاز به یک روش جستجوی معماری سطح بالا مانند روش ما را برای یافتن بهترین معماری برای مدل های CNN نشان می دهد.
Abstract
The increasing use of machine learning algorithms, such as Convolutional Neural Networks (CNNs), makes the hardware accelerator approach very compelling. However the question of how to best design an accelerator for a given CNN has not been answered yet, even on a very fundamental level. This paper addresses that challenge, by providing a novel framework that can universally and accurately evaluate and explore various architectural choices for CNN accelerators on FPGAs. Our exploration framework is more extensive than that of any previous work in terms of the design space, and takes into account various FPGA resources to maximize performance including DSP resources, on-chip memory, and off-chip memory bandwidth. Our experimental results using some of the largest CNN models including one that has 16 convolutional layers demonstrate the efficacy of our framework, as well as the need for such a high-level architecture exploration approach to find the best architecture for a CNN model.
I. INTRODUCTION
Convolutional Neural Networks (CNNs) are used for a broad range of machine learning problems such as object classification and semantic segmentation [1] [2]. Their state-of-the-art recognition performance as well as very high computational complexity makes them a very attractive target for hardware acceleration. In particular, FPGAs, by virtue of reprogrammability, have been a platform of choice for many large-scale CNNs [3]–[8].
The problem of accelerating convolutional neural networks hinges on that of accelerating convolutional layers as they account for most of the computational complexity.
VI. CONCLUSION
We presented an architecture exploration approach targeting CNN accelerators on FPGAs. Unlike previous work which is often tied to a specific architecture, our approach allows for a quick evaluation of many valid architectures which we find essential in finding the best architecture that suits the target application. Our exploration framework is not only extensive but also highly optimizing in terms of utilizing hardware resources such as DSP resources, on-chip memory, and off-chip memory bandwidth. We have demonstrated the efficacy of our framework through experiments using some of the largest CNN models, which also point out the need for a high-level architecture exploration approach such as ours to find the best architectures for CNN models.


(جهت بزرگ نمایی روی عکس کلیک نمایید)
چکیده
1- مقدمه
2- چارچوب جستجوی ما
3- ارزیابی یک نقطه طراحی
4-آزمایشات
5- کار مرتبط
6-نتیجه گیری
منابع
Abstract
1. INTRODUCTION
.2 OUR EXPLORATION FRAMEWORK
3. EVALUATION OF A DESIGN POINT
4. EXPERIMENTS
5. RELATED WORK
6. CONCLUSION
REFERENCES
- اصل مقاله انگلیسی با فرمت ورد (word) با قابلیت ویرایش
- ترجمه فارسی مقاله با فرمت ورد (word) با قابلیت ویرایش، بدون آرم سایت ای ترجمه
- ترجمه فارسی مقاله با فرمت pdf، بدون آرم سایت ای ترجمه