
دانلود رایگان مقاله پردازش کلان داده ها با استفاده از داده های HDFS
چکیده
استفاده روز افزون از سیستم های فعال شده اینترنت (IOT) منجر به مقادیر فراوانی از داده ها با ساختارهای مختلف شده است. اکثر راه حل های کلان داده ها در بالای سیستم اکو هادوپ یا از سیستم فایل توزیع شده (HDFS) استفاده می شوند. با این حال، بررسی های ناکارآمدی در این سیستم در هنگام برخورد با داده ها نشان داده شده اند. برخی از تحقیقات این مسائل را برای نوع خاصی از داده های گراف برطرف می کنند، اما امروزه اطلاعات بیشتری از داده ها قابل دسترس هستند. چنین مسائلی مربوط به عملکردهایی می شوند که منجر به مسائل بزرگی از جمله فضای بزرگ تر مورد نیاز در مراکز داده، و از بین رفتن منابع (مانند مصرف انرژی)، و مشکلات زیست محیطی (مانند انتشار بیشتر کربن) نیز می شود. ما یک ماژول اطلاعاتی را برای سیستم اکو هادوپ ارائه می دهیم. ما همچنین یک روش رمزگذاری توزیع شده را برای الگوریتم های ژنتیک ارائه می دهیم. چارچوب ما این امکان را می دهد تا هادوپ بتواند توزیع داده ها و قرار دادن آنها براساس تجزیه و تحلیل داده های خوشه ای را مدیریت کند. ما قادر هستیم طیف گسترده ای از انواع داده ها را مدیریت کنیم و همچنین قادر هستیم زمان استفاده از منابع پرس وجو را بهینه کنیم. ما آزمایش هایی را که در مجموعه داده-های متعدد انجام شده اند را از طریق LUBM ایجاد می کنیم.
1. مقدمه
ایجاد علومی از داده ها با چالش های بسیاری مواجه بوده است. یک مسئله اصلی وجود دارد و آن این است که امروزه کلان داده ها، پویا و ناهمگن هستند، و چندین منابع را که اغلب ساختار استانداردی ندارند را جمع آوری می کنند.
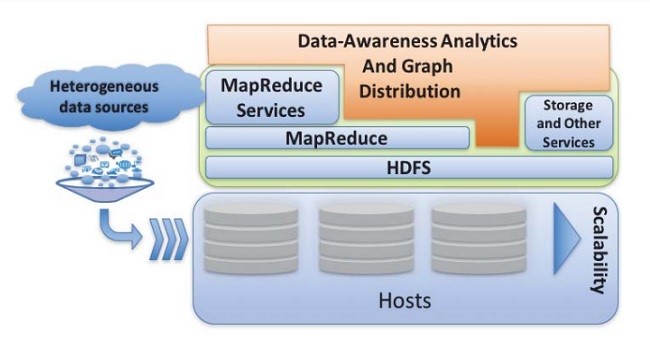
اکثر تجزیه و تحلیل داده های مدرن، ابزارهای مدیریت و سرویس را طراحی می کنند و در سیستم فایل توزیع شده هادوپ (HDFS) به عنوان یک انبار داده ای مورد استفاده قرار می دهند؛ گاهی اوقات هم این ابزار تحلیلی از سرویس هایی که توسط اکوسیستم هادوپ پردازش شده اند استفاده می کند. هادوپ از لحاظ هزینه و عملکرد بسیار خوب است.
قابلیت انعطاف هادوپ، مقیاسی را روی مسائل مدیریتی داده ها ارائه می دهند و در آن کاربران به صورت ناکارآمد کار انجام می دهند [1]. هونگ و همکارانش (a) راهکارهایی که کاربران به منظور اضافه کردن ماشین-ها برای غلبه بر محاسبات انجام می دهند نحوه تمرکز و استفاده از کدهای منابع کاربران را به ما نشان می دهد، و (b) بسیاری از کاربران HDFS معتقدند که این کدها برای پردازش دسته ای طراحی شده اند. از این رو، خوب است که کدها برای مدت طولانی در پس زمینه بکار برده شوند و حتی تصور هم نمی کنند که منابع مورد استفاده این فرآیندها هستند.
در باجدا پاولیکوفسکی و همکارانش روی هاداپ کار کردند [2]، و نویسندگان نمونه ای از چنین ناکارآمدی را ارائه دادند و داده های ساخت یافته را 50 بار برآورد کردند. با این حال، انفجار اقدام مهم داده های نیمه ساخت یافته، به صورت چندگانه و ساختارنیافته بر طبق بررسی های مایکل واکر است که در وبلاگ به آن اشاره شده است [3]. شرکت داده های بین المللی (IDC) برآورد کرده است که حجم داده های دیجیتال از 40 تا 50 درصد در سال رشد خواهد کرد [4]. تا سال 2020، IDC [4] پیش بینی کرده است که این تعداد به 40 زتابایت خواهد رسید. تا سال 2020، جهان 50 بار مقادیر داده ای و 75 بار محتوای داده ها را تولید خواهد کرد. نیازهای سختی برای ابزارهای تجزیه و تحلیل داده فعلی به منظور اندازه گیری کلان داده ها وجود دارد و آنها به طور موثر از منابع پردازش استفاده می کنند.
روهلوف و همکارانش در سال 2011 [5] نحوه ذخیره داده های گراف در هادوپ را با استفاده از نمای سه گانه توضیح دادند. آنها همچنین نشان دادند که چطور تطبیق الگوی زیر نمودار در یک نمودار مقیاس پذیر انجام می شود. اگرچه تمرکز بر روی گراف های وب معنایی بود، اما تکنیک هایی که در این مقاله ارائه شده بود انواع نمودارها را تعمیم می داد. سیستم SHARD نتیجه این مقاله بود. از این رو، تکنیک های هادوپ پشتیبانی می شوند تا ظرفیت تطبیق الگوریتم زیر نمودار ترسیم شود.
در سال 2011، هوانگ و همکارانش مقیاس پرس وجو SPARQL و گراف های RDF [1] را که به طور کارآمد در تکنیک ها توسط روهلوف و همکارانش بیان شده بودند را نشان دادند [5]. هوانگ و همکارانش [1] 1340 عامل را که کمتر از تکنیک های کارآمد است را معرفی کرده اند [5]. و از سایر تکنیک های جایگزین برای پردازش الگوریتم های زیر که براساس هادوپ هستند را استفاده کردند.
در برخی موارد، راه حل های کلان داده از HDFS به عنوان یک ابزار ذخیره ساز استفاده نمی کنند. با این حال، آنها از همان روش مقیاس پذیری افقی استفاده می کنند. ما راه حل هایی را که بر روی HDFS کار انجام می دهند را آزمایش و ارائه دادیم. نمونه هایی از ابزارهای ذخیره ساز HDFS به عنوان آپاچی اسپارک [6] و مسوس عمل می کنند [7]. سیستم هادوپ از طریق منابع YARN و منبع داده HDFS، و HAMR پشتیبانی می شود [8]. از این رو، بهینه سازی HDFS با چارچوب HDFS ارائه می شود و منجر به بهینه-سازی تعداد زیادی از راه حل های کلان داده ها می شود.
اسپارک [6] و استورم [9] جدیدترین ابزار کلان داده ها را ارائه کردند. آپاچی استورم [9] یکی دیگر از راه حل های داده ای است که از YARN برای تجزیه و تحلیل داده های نامحدود استفاده می کرده اند. استورم هادوپ را ایجاد می کند و به صورت دسته ای آن را پردازش می کند. برخی از تلاش ها در بهینه سازی Storm ایجاد می شوند. یک مثال از زمانبندی بهینه سازی در [10] یافت شده است، و با افزوده شدن Storm به آن در [11] ارائه شده است. تمرکز ما در این بررسی بیشتر روی بهینه سازی انبار داده ای HDFS است (در حال حاضر داده ها در HDFS قرار دارند). با این حال، در برخی از موارد، Strom [9] جریان داده ها را پردازش می کند و نتایج خروجی را به منظور پردازش بیشتر در HDFS ذخیره می کند، تا جایی که رویکرد ما امکانات تحلیلی داده را در بسته های هادوپ انجام دهد.
Abstract
The increased use of cyber-enabled systems and Internet-of-Things (IoT) led to a massive amount of data with different structures. Most big data solutions are built on top of the Hadoop eco-system or use its distributed file system (HDFS). However, studies have shown inefficiency in such systems when dealing with today’s data. Some research overcame these problems for specific types of graph data, but today’s data are more than one type of data. Such efficiency issues lead to largescale problems, including larger space required in data centers, and waste in resources (like power consumption), that in turn lead to environmental problems (such as more carbon emission) [1], as per scholars. We propose a data-aware module for the Hadoop eco-system. We also propose a distributed encoding technique for Genetic Algorithms. Our framework allows Hadoop to manage the distribution of data and its placement based on cluster analysis of the data itself. We are able to handle a broad range of data types as well as optimize query time and resource usage. We performed our experiments on multiple datasets generated via LUBM.
1 INTRODUCTION
Building a science out of data faces many challenges. One major problem is that today's data is big, dynamic, and heterogeneous, collected from multiple sources and frequently has no standard structure.
The majority of modern data analytics, management tools and services are designed to use Hadoop Distributed File System (HDFS) as a data warehouse; sometimes these analytic tools use services provided by the Hadoop ecosystem for processing. From a price/performance standpoint, Hadoop stands well.
The flexibility Hadoop provides to scale on data management problems is the reason why users perform inefficiently as per [1]. As per Huang et al. (a) the way users add machines to overcome computation issues made them focus less on how their codes use resources, and (b) many HDFS users are convinced that it is designed for batch processing. Hence, it’s okay to have the codes running for a long time in the background without even thinking about the resources these processes are using.
In Bajda-Pawlikowski et al. work Hadapt [2], the authors gave an example of such inefficiency, and overcame it for structured data by a factor of 50. However, the enterprise data explosion is mostly semi, multi and unstructured according to Michael Walker in the survey he referenced in his blog [3]. The International Data Corporation (IDC) estimates that the volume of digital data will grow 40 to 50 percent per year [4]. By 2020, IDC [4] predicts the number will have reached 40 Zettabytes (ZB). By 2020, the world will generate 50 times the amount of data and 75 times the number of data containers [3]. There is an intense need for the current data analytic tools to scale on big data and process it efficiently to utilize the resources.
Rohloff et al. in 2011 [5] explained how to store graph data in Hadoop using a representation of triples. They also showed how to perform sub-graph pattern matching in a scalable fashion on graphs of data. Even though the focus was Semantic Web graphs, the techniques presented in the paper are generalizable to other types of graphs. The system SHARD was a result of that paper. Its techniques support Hadoop with the capacity to scale sub-graph pattern matching.
In 2011, the work of Huang et al. on Scalable SPARQL querying of large RDF graphs [1] showed an efficiency problem in the techniques presented by Rohloff et al. [5]. Huang et al. [1] introduced a factor of 1340 times less efficient in Rohloff et al. [5] than other alternative techniques for processing sub-graph pattern matching queries within a Hadoop-based system.
In some situations, Big Data solutions do not use HDFS as a storage. However, they use the same methodology of horizontal scalability. We proposed and experimented with solutions that work on the core HDFS and can be generalizable in those cases. Examples of such tools that use HDFS as storage are Apache Spark [6] and Mesos [7]. An example of a system that supports Hadoop through Yarn resource negotiator and HDFS as a data source is HAMR [8]. Hence, optimizing HDFS with the proposed data-aware HDFS framework will lead to optimizing a large number of current big data solutions.
Spark [6] and Storm [9] are the colorful new Big Data toys. Apache Storm [9] is another big data solution that uses yarn to run real-time analysis on unbounded streams of data. Storm is building on what Hadoop did for batch processing. Some efforts have been made on optimizing Storm. An example of scheduling optimization is found in [10], and extensions to Storm were proposed in [11]. Our focus in this study is on optimizing HDFS as a data warehouse (where data already resides on HDFS). However, in some cases, Storm [9] processes streams of data and stores the output results for further processing on HDFS, where our approach facilitates the data-analytic packages around Hadoop.
چکیده
1. مقدمه
2 محدوده کاری
2.1 پایگاه داده های گراف
2.2 تشخیص جامعه و الگوریتم تکاملی چند هدفه
2.3 سرویس توسعه HDFS
3 عملکرد و کارآیی HDFS
4 شاخص های آگاه داده های HDFS
4.1 تبدیل گراف
4.2 خوشه بندی گراف
4.3 فرضیات و توزیع گراف
5 کل معماری
5.1 ساختار توزیع شده گراف های RDF
5.2 خوشه بندی مبتنی بر ژنتیک
5.3 پارتیشن بندی و جاگذاری کردن
6 آزمایشات و نتایج
6.1 تبدیل گراف و خوشه بندی
6.2 آزمایشات عملکرد سیستم
7 نتیجه گیری
Abstract
1 Introduction
2 Scope of Work
2.1 Graph Databases
2.2 Community Detection and Multi-Objective
Evolutionary Algorithms
2.3 Service deployments over HDFS
3 HDFS Performance & Efficiency Problem
4 Data-Aware HDFS Indices
4.1 Graph Transformation
4.2 Graph Clustering
4.3 Graph Distribution and Assumptions
5 Overall Architectur
5.1 Building Distributed RDF Graphs
5.2 Genetic-Based Clustering
5.3 Partitioning and Placement
6 Experiments and Results
6.1 Graph Conversion and Clustering
6.2 System Performance Experiments
7 Conclusion
REFERENCES