
دانلود رایگان مقاله مدل ترکیبی فازی-عصبی برای کاربردکاوی وب
چکیده
کاربردکاوی وب شامل سه مرحله اصلی است: قبل از پردازش، کشف دانش و تجزیهوتحلیل الگو. اطلاعات بهدست آمده از تجزیهوتحلیل میتواند توسط مدیران وبسایت برای مدیریت کارآمد و شخصی از وبسایت خود استفاده شود و در نتیجه نیازهای خاص جوامع خاصی از کاربران میتواند برآورده شود و سود افزایش یابد. همچنین، کاربردکاوی وب تشخیص الگوهای پنهان نهفته در ورود دادههای وب است. این الگوها نشاندهندهی رفتار کاربر در حال جستجو است که میتواند برای تشخیص انحراف در رفتار کاربر در بانکداری مبتنی بر وب و برنامههای کاربردی دیگر که در آن حریم خصوصی دادهها و امنیت آنها اهمیت زیادی برخوردار است به کار رود. روش پیشنهادی دادههای وبسایت پلیتکنیک دکتر T.M.A.PAI را پردازش، کشف و تجزیهوتحلیل میکند. مدل ترکیبی براساس عصبی-فازی برای کشف دانش از لاگ وب استفاده شده است.
1. معرفی
افزایش تعداد برنامههای کاربردی مبتنی بر وب که در مجموعهای از مقدار عظیمی از اطلاعات در وب سرور منجر به پایگاهدادههای مربوطی میشود. این موضوع در کشف دانش با استفاده از تکنیکهای وبکاوی استفاده شده است. در کاربردکاوی وب الگوهای جستجو کاربران برای استخراج اطلاعات مفید تجزیهوتحلیل میشود. جوامع کسبوکار از دانش کشف برای افزایش سود توسط وبسایتهای شخصی برای مشتری استفاده میکند. با هدف درک رفتار کاربران و تنظیمات و در نتیجه افزایش سود برنامههای کاربردی مبتنی بر وب، کاربردکاوی وب الگوهای استفاده شدهی پنهان و جالب در دادههای وب را کشف میکند. معمولا، کاربردکاوی وب شامل پیشپردازش، کشف دانش و تجزیهوتحلیل الگو است.
لاگهای مربوط به سرور به عنوان ورودی برای فرآیند وبکاوی استفاده میشود. دادههای لاگ بدون ساختار و مبهم هستند. بهمنظور استخراج الگوهای مفید از لاگ وب، باید برای رفع نویزهای آن از پیش پردازش شوند، در نتیجه دادههای با حجم کاهش یافته پردازش شود. الگوریتمهای دادهکاوی میتواند برای لاگهای وب از پیش پردازش شده و برای استخراج الگوهای مفید بهکار برده شود.
ویژگی نامشخص و مبهم رفتار کاربران درحال جستجو برای مدلسازی بسیار دشوار است. بهطورکلی، یک وبسایت به بسیاری از گروههای مختلف کاربران حمله میکند. بهعنوان مثال، یک گروه بازدیدکننده وبسایت ممکن است شامل دانشآموزان آیندهنگر، والدین، بانکداران، پیمانکاران داخلی، ناشران کتاب و صاحبان فروشگاه کتاب و غیره همراه با عناصر ضد اجتماعی دیگر باشد. هر گروه میتواند برخی از نیازها یا اهداف خاصی داشته باشد. علاوهبراین، کاربران یک گروه میتوانند مقاصد مختلفی از بازدید وبسایت داشته باشند. بهعنوانمثال، ممکن است بانکدار از وبسایت دانشگاه و دسترسی به لینکهای مربوط به تاریخ ورود بازدید کند بهطوریکه کمپینی برای وامهای آموزشی داشته باشد. بانکدار مشابهی ممکن است از وبسایت جهت طرح وامهای ماشین و مسکن بازدید کند. الگوریتمهای خوشهبندی سخت موفق به گرفتن چنین رفتارهای متداخل و یا منافع کاربران بهعنوان یک الگوریتم انحصاری نیستند. از این رو، الگوریتمهای خوشهبندی فازی برای کاربردکاوی وب مناسبتر میباشند. از این رو، در این کار پیش از ای، الگوریتم خوشهبندی فازی C-میانگین برای خوشهبندی جلسات کاربر وب بهکار گرفته شده است.
در این کار، یک مدل ترکیبی براساس خوشهبندی عصبی–فازی برای خوشهبندی موثر کاربران وبسایت پلیتکنیک براساس الگوهای جستجو مشابه پیادهسازی شده است. لاگ وب بااستفاده از تکنیکهای کاهش ابعاد و روشهای ترکیب پیش پردازش شده است.
ادامه مقاله به شرح زیر سازماندهی شده است. بخش 2 کارهای مرتبط؛ بخش 3 ارائه روش پیشنهادی؛ بخش 4 راهاندازی تجربی و تجزیهوتحلیل نتیجه و در نهایت، بخش 5 نتیجه کار را بیان میکند.
2. کارهای مرتبط
A. Bhargav و همکارانش یک چارچوب برای کاربردکاوی وب متشکل از پیش پردازش، کشف الگو و طبقهبندی کاربران پیشنهاد داده است. این چارچوب کاربران را براساس کشور، ورود به سایت و زمان دسترسی طبقهبندی میکند. M. A. Eltahir و همکارانش و Sanjar و همکارانش بهبررسی و بحث در مورد استخراج اطلاعات از تاریخ ورود کاربر بااستفاده از کاربردکاوی وب پرداختهاند. بررسی دقیق جمعآوری دادهها و مرحله قبل از پردازش از کاربردکاوی وب توسط Varnagar بحث شده است. Sudheer و همکارانش چند روش آمادهسازی دادهها از جریان دسترسی برای شناسایی جلسات منحصربه فرد و کاربران منحصربه فرد پیشنهاد داده است. تجزیهوتحلیل رفتار یادگیرنده برای کمک به ارزیابی یادگیری و بهمنظور افزایش ساختار یک دوره است، تکنیکهای دادهکاوی آموزشی به کار برده شده است. Maheswar و همکارانش یک الگوریتم جدید برای پیش پردازش و خوشهبندی لاگ وب ارائه داده است.
تکنیکهای دادهکاوی و تجزیهوتحلیل براساس عبارات منظم در اطلاعات تولید شده توسط گزارشهای ارائه شدهی دانشگاه HTTP سرور توسط Adamov ارائه شده است. Joshi و همکارانش عملکردهای مختلف الگوریتمهای محاسبات نرم بر روی وبسایت آموزشی را اجرا و تجزیهوتحلیل کرد. CLIQUE الگوریتمی برای خوشهبندی جلسات وب برای شخصیسازی وبسایت توسط Santhisree است. Nadi و همکارانش یک مدل پویا براساس تکنیکهای خوشهبندی فازی، قابل اجرا بر روی خط کاربران پیشنهاد داده است. روش خوشهبندی فازی، در این مطالعه، امکان گرفتن عدم قطعیت در میان رفتار کاربران وب را فراهم میکند. خوشهبندی فازی در رویکرد medoids توسط پیرپائلو و همکارانش برای طبقهبندی توالی مرتب (مسیرهای) نمایش الگوهای رفتار فردی در یک فضای واقعی یا مجازی و حوزه زمان ارائه شده است. انصاری و همکارانش یک تابع عضویت فازی برای تخصیص وزن به جلسهها براساس تعداد آدرسهای دردسترس توسط جلسات به کار بردهاند و سپس از الگوریتم خوشهبندی فازی C-میانگین برای کشف خوشههای پروفایل کاربر استفاده کرده است. مدل فازی عصبی برای خوشهبندی دادهها توسط فرهاد روحی معرفی شده است.
Abstract
Web Usage mining consists of three main steps: Pre-processing, Knowledge Discovery and Pattern Analysis. The information gained from the analysis can then be used by the website administrators for efficient administration and personalization of their websites and thus the specific needs of specific communities of users can be fulfilled and profit can be increased. Also, Web Usage Mining uncovers the hidden patterns underlying the Web Log Data. These patterns represent user browsing behaviours which can be employed in detecting deviations in user browsing behaviour in web based banking and other applications where data privacy and security is of utmost importance. Proposed work pre-process, discovers and analyses the Web Log Data of Dr. T.M.A.PAI polytechnic website. A neuro-fuzzy based hybrid model is employed for Knowledge Discovery from web logs.
1. Introduction
The increasing number of web based applications has resulted in collection of massive amount of data in web server logs. This has resulted in Knowledge Discovery by the application of Web Usage Mining techniques. In Web Usage Mining browsing patterns of users are analyzed to extract useful information. Business communities make use of the discovered knowledge to increase the profit by personalizing the web sites for the customer thereby improved customer satisfaction. With the goal of understanding the user behaviors and preferences and thereby increasing the profit of the web based applications, Web Usage Mining discovers interesting usage patterns hidden in web data1. Usually, Web Usage Mining consists of Pre-Processing, Knowledge Discovery and Pattern Analysis.
Web Server Logs serves as the input to the Web Usage Mining process. The Web Log Data is unstructured and noisy and ambiguous. In order to extract useful patterns from Web Logs, it must be preprocessed to remove noisy and irrelevant data, thereby reducing the bulk of data to be processed. Data mining algorithms can then be applied to the pre-processed web logs to extract useful patterns.
The uncertain and fuzzy characteristic of the browsing behavior of user is very difficult to model. Generally, a Web site attracts many different groups of users. For example, a college web site visitor group may include prospective students, parents, bankers, civil contractors, book publishers and book shop owners etc along with other anti social elements. Each group can have some specific need or goal. Further, a user within a group can have different intention during his visit to the web site. For example, a banker may visit a college web site and access links pertaining to admission dates so as to campaign his bank for educational loans. Same banker may visit the college web site to know about faculty details to campaign their Car or House Loan Scheme. Hard Clustering algorithms fail to capture such overlapping behaviors or interests of users as these algorithms push every object exclusively to a single cluster. Hence, fuzzy clustering algorithms are more suitable for Web Usage Mining domain. Hence, in the earlier work, the Fuzzy C-Means Clustering algorithm was employed for clustering the web user sessions.
In this work, a hybrid model based on neuro – fuzzy clustering is implemented to efficiently cluster the users of polytechnic website based on similar browsing patterns. The Web Log was preprocessed using Dimensionality reduction techniques and combined methodologies.
The rest of the paper is organized as follows. Section 2 presents the related work; Section 3 presents the proposed method; Section 4 deals with the experimental set up and result analysis and finally, Section 5 concludes the work.
2. Related Work
A. Bhargav, et al.2 proposes a framework for Web Usage Mining consisting of Pre-processing, Pattern Discovery and Users classification. This framework classifies the users based on country, site entry and access time. M. A. Eltahir, et al.3 and Sanjay Kumar Malik, et al.4 explores and discusses Information extraction from user navigation history using Web Usage Mining. A detailed survey on data collection and pre-processing stage of web usage mining is discussed by Varnagar C. R.5. K. Sudheer Reddy, et al.6 proposes several data preparation techniques of access stream to identify the unique sessions and unique users. To analyze the learners’ behaviour to help in learning evaluation and to enhance the structure of a given course, Educational data mining techniques are employed7. B. U. Maheswari, et al.8 proposes a new algorithm for pre-processing and clustering of web log.
Data Mining and Analysis techniques based on regular expressions on the data generated by University HTTP Server Logs has been proposed by Adamov A.9. M. Joshi, et al.10 implements and analyzes the performance of different soft – computing algorithms over an educational site. CLIQUE (CLUstering in QUEst) algorithm for clustering web sessions for web personalization has been adopted by K. Santhisree, et al.11. S. Nadi, et al.12 proposes a model for dynamic recommendation based on fuzzy clustering techniques, applicable to currently on-line users. The fuzzy clustering approach, in this study, provides the possibility of capturing the uncertainty among Web user’s behaviours. A fuzzy clustering around medoids approach is adopted by Pierpaolo D’Urso et al.13 to classify ordered sequences (paths) representing patterns of individual behaviour in an actual or virtual space – time domain. Z. Ansari, et al.14 employs a Fuzzy Membership Function to assign weights to sessions based on the number of URLs accessed by the sessions followed by application of Fuzzy c-Mean Clustering algorithm to discover the clusters of user profiles. A neuro – fuzzy model for data clustering is introduced by Farhat Roohi15.
چکیده
1. معرفی
2. کارهای مرتبط
3. متودولوژی
3.1. روش جمعآوری دادههای وب
3.2. مرحله قبل از پردازش لاگ وب
3.2.1. تمیز کردن لاگ وب
3.2.2. شناسایی کاربر
3.2.3. شناسایی جلسه
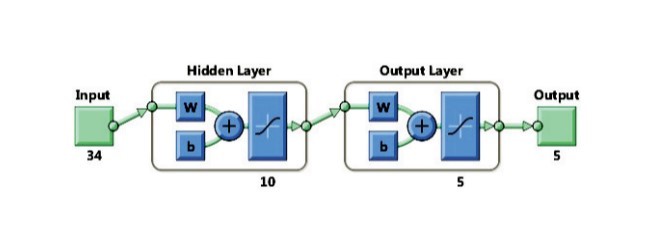
3.3. کشف دانش بااستفاده از الگوریتم خوشهبندی فازی- عصبی
4. راهاندازی تجربی و تحلیل نتایج
4.1. لاگ وب قبل از پردازش
4.2. فاز کشف دانش
5. نتیجهگیری
منابع
Abstract
1. Introduction
2. Related Work
3. Methodology
3.1 Web log data collection
3.2 Web log pre-processing
3.2.1 Web log cleaning
3.2.2 User identification
3.2.3 Session identification
3.3 Knowledge discovery using neuro – fuzzy clustering algorithm
4. Experimental Setup and Results Analysis
4.1 Web log pre-processing
4.2 Knowledge discovery phase
5. Conclusion
References