
دانلود رایگان مقاله مقدمه ای بر YARN و بررسی هادوپ
چکیده
تجزیه و تحلیل کلان داده ها و مقدار زیادی از داده ها در سال های اخیر به یک بینش جدید تبدیل شده اند. روز به روز داده ها با سرعت چشمگیری در حال رشد هستند. یکی از تکنولوژی های کارآمد و موثر که با کلان داده-ها برخورد می کند هادوپ است و در این مقاله آنها را مورد بحث و بررسی قرار می دهیم. هادوپ، برای پردازش از کلان داده ها، که از مدل زمانبندی نگاشت کاهش است استفاده می کند. هادوپ از زمانبندی های مختلفی برای اجرای موازین شغلی استفاده می کند. زمانبندی به طور پیش فرض (First In First Out) زمانبندی FIFO است. زمانبندی با گزینه های مختلف پیشدستی و غیرپیشدستی توسعه پیدا می کند. نگاشت کاهش از محدودیت هایی که دست پیدا کرده است عبور می کند. بنابراین برای غلبه بر محدودیت های نگاشت کاهش، نسل بعدی نگاشت کاهش با عنوان YARN توسعه پیدا می کند (منابع انتقال دهنده دیگر). بنابراین، این مقاله یک بررسی از هادوپ، و استفاده از چند روش زمانبندی و به طور مختصر مقدمه ای بر YARN را ارائه می دهد.
1- مقدمه
در حال حاضر سناریو با اینترنت چیزهای زیادی تولید می کند و به طور عمده برای هوش تجاری تجزیه و تحلیل می شوند. در منابع مختلف کلان داده ها سایت های شبکه های اجتماعی، حسگرها، تراکنش برنامه های کاربردی سازمانی/پایگاه داده ها، دستگاه های تلفن همراه، داده های تولید شده، مقدار زیادی داده های تولید شده از فیلم های با کیفیت بالا و منابع بسیاری وجود دارد. برخی از منابع این داده ها ارزش حیاتی دارند و برای توسعه کسب و کار بسیار مفید می باشند. بنابراین یک سوال مطرح می شود چگونه چنین مقادیر عظیمی از داده ها می توانند استفاده کنند؟ علاوه بر این، هیچگونه توقف داده ای در آن وجود ندارد. درخواست های زیادی برای بهبود تکنیک های مدیریت کلان داده ها وجود دارد. پردازش کلان داده ها را می توان با استفاده از محاسبات توزیع شده و مکانیسم های پردازش موازی انجام داد. هادوپ ]1[ یک سیستم عامل محاسباتی توزیع شده در جاوا است که شامل ویژگی هایی شبیه به سیستم فایلی گوگل و نمونه ای از برنامه نویسی نگاشت کاهش است. چارچوب هادوپ توسعه دهندگان را از مسیر حل مسائل مسدود می کند و به آنها این امکان را می دهد که روی مسائل محاسباتی خود تمرکز کنند و مسائل مربوط به راه اندازی چارچوب را به طور ذاتی انجام دهند.
در بخش دوم ما در مورد جزئیات دو مورد مهم هادوپ HDFS و نگاشت کاهش بحث می کنیم. در بخش سوم ما درباره برنامه های هادوپ بحث می کنیم. بخش چهارم برخی از انواع زمانبندی مورد استفاده در هادوپ و بهبود زمانبندی را مورد بحث قرار می دهیم. بخش پنجم بیشتر در مورد جنبه های فنی هادوپ بحث می کنیم. بخش ششم روی نمونه نسل بعدی هادوپ YARN متمرکز می شویم. سرانجام در بخش هفتم به منابع هادوپ رجوع می کنیم.
2- هادوپ
هادوپ یک چارچوب طراحی شده از کلان داده ها است و سیستم های معمولی کلان داده ها را می تواند سازماندهی کند. هادوپ داده ها را در مجموعه ای از دستگاه ها توزیع می کند. قدرت واقعی هادوپ به صورت مقیاس پذیری صدها یا هزاران کامپیوتر که هر کدام شامل چندین هسته پردازنده هستند می باشد. بسیاری از شرکت های بزرگ معتقدند که ظرف چند سال بیش از نیمی از داده ها جهان در هادوپ ذخیره خواهند شد ]2[. علاوه بر این، هادوپ با ماشین مجازی ترکیب می شود و نتایج بیشتری را ارائه می دهد. هادوپ عمدتا شامل موارد زیر است: 1) سیستم فایل توزیع شده هادوپ (HDFS): سیستم فایل توزیع شده برای دستیابی به فضای ذخیره سازی و تحمل خطا است و 2) نگاشت کاهش هادوپ یک مدل برنامه نویسی قدرتمند موازی است که مقدار زیادی داده را از طریق محاسبات توزیع شده در میان خوشه ها پردازش می کند.
A. سیستم فایل توزیع شده هادوپ-HDFS
سیستم فایل توزیع شده هادوپ ]3[ ]4[ یک سیستم فایل منبع باز است که به طور خاص برای بررسی فایل-های بزرگی نمی توانند سیستم فایل سنتی را سازماندهی کنند طراحی شده است. مقدار زیادی از داده ها تقسیم، تکثیر می شوند و در میان ماشین های متعدد وجود دارند. تکرار داده ها، محاسبات را سریع و قابلیت اطمینان را تسهیل می کنند. به همین دلیل است که سیستم HDFS نیز می تواند به عنوان یک سیستم فایل توزیع شده نامگذاری شود و این بدین معنی است که اگر یک کپی از داده ها خراب باشد یا به طور خاص نتوانسته باشد از گره نام در محل ذخیره سازی داده ها استفاده کند از عمل کپی تکراری استفاده می کند. در حال حاضر این عمل اطمینان حاصل می کند که بدون هرگونه اختلالی انجام شود.
HDFS دارای معماری ارباب/برده است. معماری HDFS در شکل 1 نشان داده شده است. در شکل الفبای A,B,C بلوک داده ها را نشان می دهد و D عدد مربوط به گره داده را نشان می دهد. HDFS اکوسیستم با قابلیت تحمل بالا را ارائه می دهد. تک گره نام همراه با گره داده در یک خوشه معمولی HDFS وجود دارد. گره نام، مسئولیت سرور اصلی فضای نامی سیستم فایل را مدیریت می کند و دسترسی کلاینت ها به فایل ها را کنترل می کند. فضای نامی ایجاد، حذف و اصلاح فایل ها توسط کاربران را ثبت می کند. نگاشت های گره نام بلوک های داده و گره های داده و عملیات فایل های سیستمی، تغییر نام و بسته شدن فایل ها و دایرکتوری ها را مدیریت می کنند. همه این دستورات براساس گره نام هستند، و گره های داده عملیاتی را بر روی بلوک های داده ای مانند ایجاد، حذف و تکرار انجام می دهند. اندازه بلوک 64 مگابایت است و به 3 نسخه تقسیم می شود. دومین نسخه در ردیف محلی در حالی که سومین نسخه در یک ردیف دور ذخیره می شود. ردیف چیزی جز مجموعه ای از گره های داده نیست.
B. نگاشت کاهش هادوپ
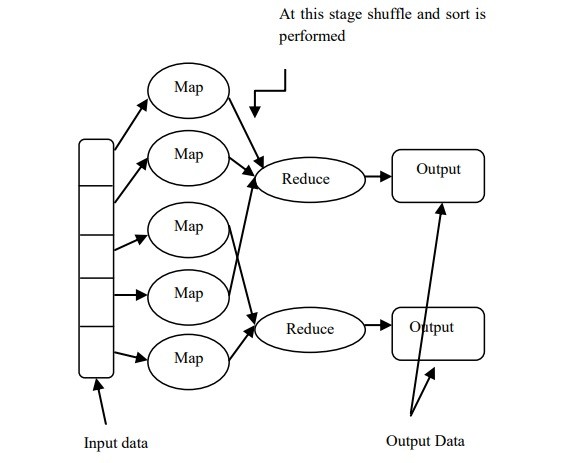
نگاشت کاهش ]5[ ]6[ یک تکنولوژی بسیار مهم است که توسط گوگل ارائه شده است. نگاشت کاهش یک مدل برنامه نویسی ساده شده و یک مولفه اصلی هادوپ برای پردازش موازی با میزان داده های وسیع است. برنامه نویسان بارگذاری مسائل را راحت به دست می آورند با این حال به صورت آزادانه روی توسعه نرم افزار تمرکز می کند. نمودار نگاشت کاهش هادوپ در شکل 2 نشان داده شده است. دو تابع پردازش داده مهم وجود دارند که عبارتند از نگاشت کاهش برنامه نویسی که شامل نگاشت و کاهش است.
داده های اصلی فاز نگاشت را به عنوان ورودی معرفی می کنند و طبق زمانبندی ای که توسط برنامه نویسان انجام شده نتایج را پردازش و تولید می کنند. برنامه های نگاشت موازی در یک زمان اجرا می شوند. اولا، داده-های ورودی به بلوک های با اندازه ثابت تقسیم می شوند و برنامه های نگاشت موازی را اجرا می کنند. خروجی نگاشت مجموعه ای از جفت مقادیر کلیدی هستند که هنوز هم دارای خروجی متوسط نیز هستند. این جفت ها در طی کار کاهش فشرده می شوند. فقط یک کلید توسط هر برنامه کاهش پذیرفته می شود و براساس این کلید پردازش انجام خواهد شد. سرانجام خروجی به فرم جفت های کلیدی درخواهد آمد.
چارچوب نگاشت کاهش هادوپ شامل یک گره ارباب است که به عنوان JobTracker و به عنوان گره های TaskTrackers کار می کند. کاربر تعدادی از برنامه های نگاشت و کاهش را در درون آنها تغییر شکل می-دهد. این برنامه ها به TaskTrackers تخصیص داده می شوند. TaskTracker به خوبی اجرای برنامه ها و پایان آنها را زمانی که تمام برنامه ها انجام می شوند رسیدگی می کند؛ و به کاربر در مورد اتمام کار اخطار می-دهد. HDFS تحمل خطا و قابلیت اطمینان را با ذخیره سازی و جایگزین کردن ورودی ها و خروجی های هادوپ ارائه می دهد.
Abstract
Big Data, the analysis of large quantities of data to gain new insight has become a ubiquitous phrase in recent years. Day by day the data is growing at a staggering rate. One of the efficient technologies that deal with the Big Data is Hadoop, which will be discussed in this paper. Hadoop, for processing large data volume jobs uses MapReduce programming model. Hadoop makes use of different schedulers for executing the jobs in parallel. The default scheduler is FIFO (First In First Out) Scheduler. Other schedulers with priority, pre-emption and non-pre-emption options have also been developed. As the time has passed the MapReduce has reached few of its limitations. So in order to overcome the limitations of MapReduce, the next generation of MapReduce has been developed called as YARN (Yet Another Resource Negotiator). So, this paper provides a survey on Hadoop, few scheduling methods it uses and a brief introduction to YARN.
I. INTRODUCTION
In present scenario with the internet of things a lot of data is generated and is analyzed mainly for business intelligence. There are various sources of Big Data like social networking sites, sensors, transactional data from enterprise applications/databases, mobile devices, machinegenerated data, huge amount of data generated from high definition videos and many more sources. Some of the sources of this data have vital value that is helpful for businesses to develop. So the question arises how such a gigantic amount of data can be dealt out? Further, there is no stopping of this data generation. There is a great demand for improving the Big Data management techniques. The processing of this huge can be best done using distributed computing and parallel processing mechanisms. Hadoop [1] is a distributed computing platform written in Java which incorporates features similar to those of the Google File System and MapReduce programming paradigm. Hadoop framework relieves the developers from parallelization issues while allowing them to focus on their computation problem and these parallelization issues are handled inherently by the framework.
In section II we discuss in more detail about Hadoop’s two important components HDFS and MapReduce. In section III we discuss Hadoop applications. Section IV discusses about some basic types of schedulers used in Hadoop and scheduler improvements. Further section V talks about technical aspects of Hadoop. Section VI focuses on next generation MapReduce paradigm YARN. Finally section VII concludes the paper after which references follow.
II. HADOOP
Hadoop is a framework designed to work with huge amount of data sets which is much larger in magnitude than the normal systems can handle. Hadoop distributes this data across a set of machines. The real power of Hadoop comes from the fact its competence to scalable to hundreds or thousands of computers each containing several processor cores. Many big enterprises believe that within a few years more than half of the world’s data will be stored in Hadoop [2]. Furthermore, Hadoop combined with Virtual Machine gives more feasible outcomes. Hadoop mainly consists of i) Hadoop Distributed File System (HDFS): a distributed file system to achieve storage and fault tolerance and ii) Hadoop MapReduce a powerful parallel programming model which processes vast quantity of data via distributed computing across the clusters.
A. HDFS- Hadoop Distributed File System
Hadoop Distributed File System [3] [4] is an opensource file system that has been designed specifically to handle large files that traditional file system cannot handle. The large amount of data is split, replicated and scattered on multiple machines. The replication of data facilitates rapid computation and reliability. That is why HDFS can also be called as self-healing distributed file system meaning that, if a particular copy of the data gets corrupt or more specifically to say if the DataNode on which the data was residing fails then replicated copy can be used. This ensures that the on-going work continues without any disruption.
HDFS has master and slave architecture. The architecture of HDFS is shown above in Figure 1. In figure alphabets A, B, C represents data block and D fallowed by a number represents a numbered DataNode. HDFS provides distributed and highly fault tolerant ecosystem. One Single NameNode along with multiple DataNodes is present in a typical HDFS cluster. The NameNode, a master server handles the responsibility of managing the namespace of filesystem and governs the access by clients to files. The namespace records the creation, deletion and modification of files by users. NameNode maps data blocks to DataNodes and manages file system operations like opening, closing and renaming of files and directories. It is all upon the directions of NameNode, the DataNodes performs operations on blocks of data such as creation, deletion and replication. The block size is of 64MB and is replicated into 3 copies. The second copy is stored on the local rack itself while the third on remote rack. A rack is nothing but just a collection of data nodes.
B. Hadoop MapReduce
MapReduce [5] [6] is an important technology which was proposed by Google. MapReduce is a simplified programming model and is a major component of Hadoop for parallel processing of vast amount of data. It relieves programmers from the burden of parallelization issues while allowing them to freely concentrate on application development. The diagram of Hadoop MapReduce is shown in Figure 2 below. Two important data processing functions contained in MapReduce programming are Map and Reduce.
The original data will be given as input to the Map phase which performs processing as per the programming done by the programmers to generate intermediate results. Parallel Map tasks will run at a time. Firstly, the input data is split into fixed sized blocks on which parallel Map tasks are run. The output of the Map procedure is a collection of key/value pairs which is still an intermediate output. These pairs undergo a shuffling phase across reduce tasks. Only one key is accepted by each reduce task and based on this key the processing will be done. Finally the output will be in the form of key/value pairs.
The Hadoop MapReduce framework consists of one Master node termed as JobTracker and many Worker nodes called as TaskTrackers. The user submitted jobs are given as input to the JobTracker which transforms them into a numbers of Map and Reduce tasks. These tasks are assigned to the TaskTrackers. The TaskTrackers scrutinizes the execution of these tasks and at the end when all tasks are accomplished; the user is notified about job completion. HDFS provides for fault tolerance and reliability by storing and replicating the inputs and outputs of a Hadoop job.
چکیده
1- مقدمه
2- هادوپ
A. سیستم فایل توزیع شده هادوپ-HDFS
B. نگاشت کاهش هادوپ
3. برنامه های کاربردی هادوپ
4. زمانبندی کار
A. زمانبندی پیش فرض هادوپ
B. شایستگی زمانبندی
C. زمانبندی ظرفیت
D. ارتقاء زمانبندی براساس اشکال اجرایی وظایف
5. نگاهی کلی به جنبه های فنی مسائل
6. یکی دیگر از منابع انتقال دهنده (YARN)
A. مقایسه YARN و نگاشت کاهش
7. نتیجه گیری
Abstrac
I. INTRODUCTION
II. HADOOP
A. HDFS- Hadoop Distributed File System
B. Hadoop MapReduce
III. APPLICATIONS OF HADOOP
IV. JOB SCHEDULING
A. The Default FIFO Scheduler
B. Fair Scheduler
C. Capacity Scheduler
D. Improvements to Schedulers based on Speculative Execution of Tasks
V. A LOOK IN TO TECHNICAL ASPECTS
VI. YET ANOTHER RESOURCE NEGOTIATOR (YARN)
A. Comparison of YARN and MapReduce
VII. CONCLUSION
REFERENCES