
دانلود رایگان مقاله تجزیه و تحلیل ساده شده کلان داده
چکیده
با توسعه تکنولوژی رایانه، افزایش قابل توجهی در رشد داد ه ها وجود دارد. دانشمندان با توجه به مقدار میزان افزایش نیازهای پردازش داده ها که در حوزه علم ایجاد می شوند همیشه غرق هستند. یک مسئله بزرگ در زمینه های مختلف استفاده از داده های با مقیاس بزرگ وجود دارد و این مسئله همیشه با پشتیبانی تصمیم-گیری مواجه است. داده کاوی تکنیکی است که می تواند الگوهای جدیدی را از مجموعه کلان داده ها پیدا کند. در طی این سال ها تمام زمینه های کاربردی مورد مطالعه و بررسی قرار گرفتند و بسیاری از روش های داده کاوی را توسعه داده اند. اما در سال های مقدار زیادی از داده ها، محاسبات و تجزیه و تحلیل آنها به طور قابل توجهی افزایش یافته اند. در چنین موقعیتی، اکثر روش های داده کاوی در عمل برای دسترسی به چنین کلان داده هایی از دسترس خارج شدند. الگوریتم موازی/همزمان و تکنیک های پیاده سازی به طور موثر کلید ارزیابی مقیاس پذیری و عملکرد مورد نیاز در تجزیه و تحلیل کلان داده ها در مقیاس بزرگ می باشند. تعدادی از الگوریتم های موازی دارای تکنیک های مختلف پیاده سازی هستند و می توانند: از نگاشت کاهش، MPI، بندها، و mash-up یا گردش کار که دارای ویژگی های عملکردی و قابلیت های متفاوتی هستند استفاده کنند. مدل MPI به طور موثر در محاسبه مسئله، به ویژه در شبیه سازی به دست می آید. در حقیقت استفاده از آن کار ساده ای نیست. نگاشت کاهش از یک مدل تجزیه و تحلیل داده ها در زمینه بازیابی داده ها است و به صورت فناوری ابر توسعه پیدا کرده است. تاکنون، چندین معماری نگاشت کاهش برای دست زدن به کلان داده ها توسعه پیدا کرده اند. معروف ترین آنها گوگل است. یکی دیگر از ویژگی های هادوپ این است که محبوب ترین نرم افزارها، نرم افزار منبع باز نگاشت کاهش است و توسط بسیاری از شرکت های فناوری اطلاعات مانند یاهو، فیس بوک، eBay و غیره مورد پذیرش قرار گرفته است. در این مقاله، ما به طور خاص روی هادوپ و اجرای موثر نگاشت کاهش به منظور تحلیل پردازش تمرکز می کنیم.
1. مقدمه
سازمان ها از چندین مقادیر که داده های ساختاری بسیار دشواری دارند و از تکنولوژی DBMS برای پردازش و تجزیه و تحلیل داده ها استفاده می کنند. این نوع مسئله با شرکت های مبتنی بر وب مانند فیس بوک، یاهو، گوگل و لینکدین همیشه مواجه است و نیاز به پردازش داده های با حجم بسیار زیاد و هزینه کافی مستر (ارباب) دارند. تعداد زیادی از این سازمان ها سیستم های غیر رسمی خود را برای غلبه بر این موضوع توسعه داده اند. به عنوان مثال، گوگل، نگاشت کاهش و سیستم فایل گوگل را توسعه داده است. همچنین یک سیستم DBMS به نام بیگ تیبل (جدول بزرگ) نیز ساخته شده است. امکان جستجو در میلیون ها صفحه نیز وجود دارد و نتایج در آن به صورت میلی ثانیه یا کمتر به منظور کمک به الگوریتم هایی که هر کدام از سرویس های جستجو را در یک چارچوب نگاشت کاهش گوگل به ارمغان می آورند برگردانده می شوند ]1[. این یک مسئله چالش برانگیز در تحلیل داده های بزرگ نیز است. کلان داده ها برای کار کردن بسیار بزرگ هستند و بنابراین یک کار بزرگ برای تجزیه و تحلیل کلان داده ها انجام می شود. تکنولوژی های موجود در تجزیه و تحلیل کلان داده ها به سرعت در حال تکمیل شدن هستند و به طور قابل توجهی علاقه زیادی به رویکردهای تحلیلی مانند هادوپ، نگاشت کاهش و Hive و توسعه نگاشت کاهش در برابر ارتباط DBMS دارند.
استفاده از چارچوب نگاشت کاهش به طور گسترده در جهت مقابله با کلان داده ها بسیار موثر بوده است. در چند سال گذشته، نگاشت کاهش به عنوان رایج ترین نمونه محاسباتی موازی، تحلیل کلان داده ها به نظر می-رسید.
نگاشت کاهش محبوبیت خود را زمانی که با موفقیت توسط گوگل مورد استفاده قرار گرفت به دست آورد. در واقع، این یک ابزار پردازش داده کاوی است و با خطا مقابله می کند و قادر است پردازش داده های با حجم بسیار زیاد را به موازات گره های محاسباتی ارائه دهد ]4[. به لطف سادگی آن، مقیاس پذیری و تحمل خطا، و نگاشت کاهش در حال تبدیل شدن در همه جا هستند، و به طور قابل توجهی هر دو صنعت علمی دانشگاه را به دست آورده اند. ما می توانیم عملکرد بالا را با توقف پردازش واحدهای کوچک به پایان برسانیم و می توانیم به صورت موازی چندین گره را در خوشه اجرا کنیم ]5[. در چارچوب نگاشت کاهش، سیستم فایل توزیع شده (DFS) ابتدا داده ها را در چندین ماشین تقسیم بندی کرده و سپس داده ها را به صورت جفت شده (key,value) بیان می کنند. چارچوب نگاشت کاهش توابع اصلی ماشین مستر (ارباب) را اجرا می کند و ما ممکن است داده های ورودی را قبل از نگاشت توابع که پس پردازنده نام دارد و خروجی عملکرد کاهش را پردازش کنند. توابع نگاشت و کاهش به صورت دوتایی ممکن هستند یکبار یا چندین بار اجرا شوند، به این دلیل که به ویژگی های برنامه بستگی دارند ]6[. هادوپ یک برنامه محبوب منبع باز است که مجموعه ای از نگاشت کاهش کلان داده ها را تجزیه و تحلیل می کند. این یک فایل سیستمی توزیع شده در سطح کاربر است و برای مدیریت منابع ذخیره سازی در میان خوشه ها مورد استفاده قرار می گیرد ]7[. با این وجود، سیستم سرعت های ناخواسته در مجموعه ای از داده ها که کمتر تولید می شوند از بین می برد. اما سرعت قابل قبولی را با مجموعه ای از کلان داده ها که تعداد گره های محاسباتی را کامل می کند تولید می کند و زمان اجرای آن را 30 درصد کاهش می دهد و آنها را با داده کاوی و سایر روش های پردازش مقایسه می کند.
به طور کلی بخش 2 تکامل نگاشت، کاهش و هادوپ را بیان می کند. بخش 3 توضیحات مختصر کلان داده ها و مدل برنامه نویسی نگاشت کاهش را ارائه می دهد. بخش 4 معماری هادوپ را تنظیم می کند. بخش 5 روشی علمی از تکنولوژی نگاشت کاهش و هادوپ که ترکیبی از عملکرد نگاشت و کاهش هادوپ است را ارائه می-دهد.
2. کارهای مرتبط
کلان داده ها به اشکال مختلف مجموعه ای از داده های بزرگ اشاره دارد و این کلان داده ها نیاز به سیستم های محاسباتی خاصی دارند تا تحلیل شوند. برای تجزیه و تحلیل کلان داده ها کارهای زیادی مورد نیاز است. اما، امروزه برای تجزیه و تحلیل چنین کلان داده هایی مسائل چالش برانگیز نیز وجود دارد. چارچوب نگاشت کاهش به تازگی توجه زیادی را برای چنین داده های گسترده ای را به کار می برد. نگاشت کاهش یک مدل برنامه نویسی و پیاده سازی مرتبط با پردازش و تولید مجموعه کلان داده ها می باشد و به طیف گسترده ای از وظایف در دنیای واقعی پاسخ می دهد ]9[. نگاشت کاهش نمونه ای از ویژگی برنامه نویسی موازی را به سادگی ارائه می دهد. در عین حال، متوازن کننده و ظرفیت تحمل پذیری خطا به همراه این ویژگی ها ارائه می شود ]10[. سیستم فایل گوگل (GFS) معمولا تحت عنوان یک سیستم نگاشت کاهش داده های توزیع شده را به صورت کارآمد و با قابلیت اطمینان ذخیره می کند و برنامه های کاربردی را در یک سیستم پایگاه داده بزرگ را که مورد نیاز است ارائه می دهد ]11[. نگاشت کاهش از طریق عنصر اولیه نگاشت و کاهش در توابع زبان های برنامه کاربردی انجام می شود ]12[. در حال حاضر برخی از پیاده سازی ها قابل دسترس هستند: اشتراک سیستم چند هسته ای با حافظه ]13[، پردازنده های چند هسته ای نامتقارن، پردازنده های گرافیکی، و خوشه ای ماشین های شبکه ]14[. تکنولوژی نگاشت کاهش گوگل امکان توسعه برنامه های توزیع شده در مقیاس وسیع را به شیوه ای ساده تر و با هزینه کم را فراهم می کند. ویژگی اصلی مدل نگاشت کاهش این است که قادر است کلان داده ها را به صورت موازی که در میان گره های مختلف توزیع شده است پردازش کند ]15[. نرم افزار نوین نگاشت کاهشی یک سیستم اختصاصی گوگل است و بنابراین برای استفاده از منابع باز قابل دسترس نیست. محاسبات توزیع شده نظریه عناصر اولیه نگاشت و کاهش را ساده می کند، سپس به زیرساخت عملکرد مورد نظر که غیربدیهی است دسترسی پیدا می کند ]16[. یک زیرساخت کلیدی دارای نگاشت کاهش گوگل، سیستم فایل توزیع شده است و با قابلیت اطمینان بالا به داده ها دسترسی پیدا می کند ]9[. با ترکیب روش زمانبندی نگاشت کاهش و سیستم فایل توزیع شده، می توان به راحتی به محاسبات توزیع شده به صورت موازی که بیش از هزاران گره محاسباتی دارد دست یافت؛ و پردازش داده ها را در مقیاس ترابایت و پتابایت و همچنین قابلیت اطمینان و بهینه سازی سیستم توزیع شده را می توان بهبود داد. ابزار نگاشت کاهش در بهینه-سازی داده ها بسیار کارآیی دارد و دارای قابلیت اطمینان نیز است به این دلیل که زمان دسترسی به داده ها یا بارگیری از آنها را 50 تا کاهش می دهد ]16[. گوگل اولین روش تکنیک نگاشت کاهش را تعمیم می دهد ]17[. تکنولوژی نگاشت کاهش که اخیرا معرفی شده است از جامعه علمی نشات می گیرد و کلان داده های بزرگ را تجزیه و تحلیل می کند ]18[. هادوپ یک برنامه منبع باز از مدل برنامه نویسی نگاشت کاهش است و به سیستم فایل توزیع شده هادوپ (HDFS) متکی است. اما سیستم فایل گوگل (GFS) وابسته نیست. HDFS بلوک های داده ای را با قابلیت اطمینان بالا در گره های مختلف قرار می دهد و آن ها را کپی می کند و سپس محاسبات را بعد از هادوپ در این گره ها انجام می دهد. HDFS شبیه به سیستم های دیگر است اما طوری طراحی شده است که در برابر خطا بسیار مقاوم است. سیستم فایل توزیع شده (DFS) هیچ سخت افزار بالایی ندارد و می تواند در رایانه ها و نرم افزارها اجرا شود. همچنین مقیاس پذیر نیز است و یکی از اهداف اصلی طراحی در اجرا است. همانطور که مشخص شد HDFS مستقل از هرگونه سیستم عامل سخت افزار و نرم افزار است، بنابراین در سیستم های ناهمگن به راحتی قابل حمل هستند ]19[. دستاورد بزرگی که توسط نگاشت کاهش حاصل شده است باعث شبیه سازی هادوپ که یک برنامه منبع باز می باشد شده است. هادوپ یک چارچوب منبع باز است که نگاشت کاهش را اجرا می کند ]20[. این یک مدل برنامه نویسی موازی است که از یک موتور نگاشت کاهش و یک سیستم فایل که سطح کاربر را مدیریت می کند و در میان منابع ذخیره-سازی خوشه تشکیل شده است ]9[. حمل و نقل سراسری سیستم عامل های مختلف-لینوکس، Mac OS/X، FreeBSD، سولاریس و ویندوز- هر دو در جاوا نوشته شده اند و فقط نیاز به سخت افزار کالا دارند.
3. اهمیت کلان داده ها
سازمان ها باید سیستم عامل محاسباتی تحقیقاتی خود را برای بهبود بخشیدن مقادیر کامل کلان داده ها ایجاد کنند. این کار کاربران را قادر می سازد تا از ساختار تجزیه و تحلیل کلان داده ها برای استخراج داده های مفید که به راحتی قابل کشف هستند را استفاده کنند. اهمیت کلان داده ها را می توان به صورت زیر توصیف کرد:
1) کلان داده ها باعث انگیزه در یک اصطلاح می شوند.
2) این افزایش و مشهوری از هر دو کاربر تجارت و صنعت فناوری اطلاعات به دست می آیند.
3) از دیدگاه تجزیه و تحلیل هنوز هم تراکم کاری و راه حل های مدیریتی که قبلا نمی توانستند از هزینه/یا محدودیت ها پشتیبانی کنند نشان داده شده اند.
4) راه حل ها قادر هستند تصمیم گیری هوشمندتری را که زمان بیشتری را برای تحلیل تکنولوژی و محصولات صرف کنند ارائه دهند.
5) تجزیه و تحلیل داده ها در چندین ساختار تصمیم گیری های هوشمندانه ای را می توانند اتخاذ کنند. تا به امروز، این نوع داده ها برای پردازش های پیچیده از تجزیه و تحلیل سنتی تکنولوژی های پردازش استفاده می-کرده است.
6) تصمیم گیری های سریع قابلیت فعال بودن را دارند به این دلیل که راه حل های کلان داده ها از تجزیه و تحلیل سریع داده های دقیق با حجم بالا پشتیبانی می کنند.
7) در نظر گرفتن زمان سریع امکان پذیر است به این دلیل که سازمان ها می توانند داده های خارج از انبار داده های سازمانی را پردازش و تجزیه و تحلیل کنند.
برنامه نویسان از مدل برنامه نویسی نگاشت کاهش برای بازیابی اطلاعات از کلان داده ها استفاده می کنند. ویژگی های اصلی و مسائل مربوط به تحویل انواع مختلف مجموعه ای از کلان داده ها در جدول زیر خلاصه شده هستند. داده هایی که درباره تکنولوژی کلان داده ها هستند می توانند به حل آنها کمک کنند.
Abstract
With the development of computer technology, there is a tremendous increase in the growth of data. Scientists are overwhelmed with this increasing amount of data processing needs which is getting arisen from every science field. A big problem has been encountered in various fields for making the full use of these large scale data which support decision making. Data mining is the technique that can discovers new patterns from large data sets. For many years it has been studied in all kinds of application area and thus many data mining methods have been developed and applied to practice. But there was a tremendous increase in the amount of data, their computation and analyses in recent years. In such situation most classical data mining methods became out of reach in practice to handle such big data. Efficient parallel/concurrent algorithms and implementation techniques are the key to meeting the scalability and performance requirements entailed in such large scale data mining analyses. Number of parallel algorithms has been implemented by making the use of different parallelization techniques which can be listed as: threads, MPI, MapReduce, and mash-up or workflow technologies that yields different performance and usability characteristics. MPI model is found to be efficient in computing the rigorous problems, especially in simulation. But it is not easy to be used in real. MapReduce is developed from the data analysis model of the information retrieval field and is a cloud technology. Till now, several MapReduce architectures has been developed for handling the big data. The most famous is the Google. The other one having such features is Hadoop which is the most popular open source MapReduce software adopted by many huge IT companies, such as Yahoo, Facebook, eBay and so on. In this paper, we focus specifically on Hadoop and its implementation of MapReduce for analytical processing.
1. Introduction
Organizations with large amounts of multi-structured data find it difficult to use traditional relational DBMS technology for processing and analyzing such data. This type of problem is especially faced by Web-based companies such as Google, Yahoo, Facebook, and LinkedIn which require to process huge voluminous data in a speedily and in cost-effective manner. A large number of such organizations have developed their own nonrelational systems to overcome this issue. Google, for example, developed MapReduce and the Google File System. It also built a DBMS system known as BigTable. It becomes possible to search millions of pages and return the results in milliseconds or less with the help of the algorithms that drive both of these major-league search services originated with Google's MapReduce framework [1]. It is a very challenging problem of today to analyze the big data. Big data is big deal to work upon and so it is a big job to perform analytics on big data. Technologies for analyzing big data are evolving rapidly and there is significant interest in new analytic approaches such as MapReduce, Hadoop and Hive, and MapReduce extensions to existing relational DBMSs [2].
The use of MapReduce framework has been widely came into focus to handle such massive data effectively. For the last few years, MapReduce has appeared as the most popular computing paradigm for parallel, batch-style and analysis of large amount of data [3].
MapReduce gained its popularity when used successfully by Google. In real, it is a scalable and fault-tolerant data processing tool which provides the ability to process huge voluminous data in parallel with many low-end computing nodes [4]. By virtue of its simplicity, scalability, and fault-tolerance, MapReduce is becoming ubiquitous, gaining significant momentum from both industry and academic world. We can achieve high performance by breaking the processing into small units of work that can be run in parallel across several nodes in the cluster [5]. In the MapReduce framework, a distributed file system (DFS) initially partitions data in multiple machines and data is represented as (key, value) pairs. The MapReduce framework executes the main function on a single master machine where we may preprocess the input data before map functions are called or postprocess the output of reduce functions. A pair of map and reduce functions may be executed once or numerous times as it depends on the characteristics of an application [6]. Hadoop is a popular open-source implementation of MapReduce for the analysis of large datasets. It uses a distributed user-level filesystem to manage storage resources across the cluster [7]. Though, the system yields undesired speedup with less significant datasets, but produces a reasonable speed with a larger collection of data that complements the number of computing nodes and reduces the execution time by 30% as compared to normal data mining and other processing techniques [8].
Section 2 gives the overall demonstration of the evolution of map, reduce and Hadoop. Sections 3 give the detail description Big Data and programming model of MapReduce. Section 4 formulates the Hadoop architecture. Sections 5 provide the practical approach of MapReduce and Hadoop technology which is a powerful combination of map and reduce function with the advent of Hadoop.
2. Related Work
Big Data refers to various forms of large information sets that require special computational platforms in order to be analyzed. A lot of work is required for analyzing the big data. But, to analyze such big data is a very challenging problem today. The MapReduce framework has recently attracted a lot of attention for such application that works on extensive data. MapReduce is a programming model and an associated implementation for processing and generating large datasets that is responsive to a broad variety of real-world tasks [9]. The MapReduce paradigm acquires the feature of parallel programming that provides simplicity. At the same time along with these characteristics, it offers load balancing and fault tolerance capacity [10]. The Google File System (GFS) that typically underlies a MapReduce system provides an efficient and reliable distributed data storage which is needed for applications that works on large databases [11]. MapReduce is enthused by the map and reduces primitives present in functional languages [12]. Some currently available implementations are: shared-memory multi-core system [13], asymmetric multi-core processors, graphic processors, and cluster of networked machines [14]. The Google’s MapReduce technique makes possible to develop the large-scale distributed applications in a simpler manner and with reduced cost. The main characteristic of MapReduce model is that it is capable of processing large data sets parallelly which are distributed across multiple nodes [15]. The novel Map-Reduce software is a proprietary system of Google, and therefore, not available for open use. Although the distributed computing is largely simplified with the notions of Map and Reduce primitives, the underlying infrastructure is non-trivial in order to achieve the desired performance [16]. A key infrastructure in Google’s MapReduce is the underlying distributed file system to ensure data locality and availability [9]. Combining the MapReduce programming technique and an efficient distributed file system, one can easily achieve the goal of distributed computing with data parallelism over thousands of computing nodes; processing data on terabyte and petabyte scales with improved system performance, optimization and reliability. It was observed that the MapReduce tool is much efficient in data optimization and very reliable since it reduces the time of data access or loading by more than 50% [16]. It was the Google which first popularized the MapReduce technique. [17]. The recently introduced MapReduce technique has gained a lot of attention from the scientific community for its applicability in large parallel data analyses [18]. Hadoop is an open source implementation of the MapReduce programming model which relies on its own Hadoop Distributed File System (HDFS). It does not depend on Google File System (GFS). HDFS replicates data blocks in a reliable manner, places them on different nodes and then later computation is performed by Hadoop on these nodes. HDFS is similar to other filesystems, but is designed to be highly fault tolerant. This distributed file system (DFS) does not require any high-end hardware and can run on commodity computers and software. It is also scalable, which is one of the primary design goals for the implementation. As it is found that HDFS is independent of any specific hardware or software platform, thus, it is easily portable across heterogeneous systems [19]. The grand achievement made by MapReduce has stimulated the construction of Hadoop, which is a popular open-source implementation. Hadoop is an open source framework that implements the MapReduce[20]. It is a parallel programming model which is composed of a MapReduce engine and a user-level filesystem that manages storage resources across the cluster [9]. For portability across a variety of platforms — Linux, FreeBSD, Mac OS/X, Solaris, and Windows — both components are written in Java and only require commodity hardware.
3. THE IMPORTANCE OF BIG DATA
Organizations need to build an investigative computing platform to realize the full value of big data. This enables business users to make use, structure and analyze big data to extract useful business information that is not easily discoverable in its actual original arrangement. The significance of Big Data can be characterized as[21]:
1) Big data is a valuable term despite the hype
2) It is gaining more popularity and interest from both business users and IT industry.
3) From an analytics perspective it still represents analytic workloads and data management solutions that could not previously be supported because of cost considerations and/or technology limitations.
4) The solutions provided enable smarter and faster decision making, and allow organizations to achieve faster time to value from their investments in analytical processing technology and products.
5) Analytics on multi-structured data enable smarter decisions. Up till now, these types of data have been difficult to process using traditional analytical processing technologies.
6) Rapid decisions are enabled because big data solutions support the rapid analysis of high volumes of detailed data.
7) Faster time to value is possible because organizations can now process and analyze data that is outside of the enterprise data warehouse.
The programmers use the programming model MapReduce to retrieve precious information from such big data. The main features and problems associated in handing different types of large data sets are summarized in the table below. It gives précises information how Big Data technologies can help solve them [22].
چکیده
1. مقدمه
2. کارهای مرتبط
3. اهمیت کلان داده ها
3.1 مدل برنامه نویسی نگاشت کاهش
4. تنظیم مسائل
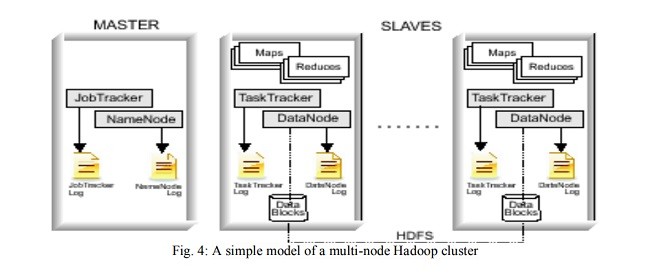
معماری HDFS
توسعه هادوپ
5. آزمایشات
نگاشت و کاهش
6. مشارکت ما
7. نتیجه گیری
Abstract
1. Introduction
2. Related Work
3. THE IMPORTANCE OF BIG DATA
3.1 MapReduce: A Programming Model
4. Problem Formulation
HDFS architecture
Deploying Hadoop
5. Experiment
Map and reduce
6. Our Contribution
7. Conclusion
References