
دانلود رایگان مقاله انتخاب بردارهای پشتیبان مناسب در SVM
چکیده
در یک دسته بندی SVM (ماشین بردار پشتیبان) افزایشی، داده های با بردارهای غیر پشتیبان عنوان بندی می-شوند( لیبل گذاری) که توسط دسته قبلی به عنوان داده های تمرینی در دسته بعدی همراه با داده های تایید شده توسط شرط KarusheKuhneTucker (شرایط کان تاکر) مورد استفاده قرار گرفته می شوند. این مقاله استراتژی نیمه تقسیم بندی انتخاب و حفظ بردارهای غیرپشتیبان از افزایش فعلی دسته بندی- که به عنوان بردارهای پشتیبان مناسب نامگذاری شدند(CSV)- را پیشنهاد می دهد که به احتمال زیاد به بردارهای پشتیبان در توسعه دسته بعدی تبدیل می شوند. همچنین این کار تحقیقاتی الگوریتمی را طراحی می کند که به عنوان بردار پشتیبان مناسب نامگذاری می شود که براساس الگوریتم SVM (CSV-ISVM) افزایشی می باشد به طوریکه استراتژی پیشنهادی را پیاده سازی می کند و کل فرایند دسته بندی SVM افزایشی تحقق می بخشد. این کار نیز تغییراتی را برای روش حلقه متمرکز پیشنهاد شده قبلی و استراتژی دسته معکوس پیشنهاد می دهد. عملکرد روش پیشنهادی با آزمایشات و همچنین مقایسه آن با تکنیکهای SVM دیگر ارزیابی می شود. نتایج تجربی و تحلیل عملکرد نشان می دهند که برای کشف نفوذ شبکه در زمان واقعی الگوریتم پیشنهادی CSV-ISVM از دسته بندی-های کلی ISVM بهتر می باشد.
1- معرفی
تشخیص نفوذ شبکه به عنوان یک طرح تشخیص مشکل برای طبقه بندی الگوهای ترافیک شبکه در دو کلاس –نرمال و غیرنرمال- در نظر گرفته می شود؛ باتوجه به شباهت بین آنها. امروزه در زمینه تشخیص نفوذ، ماشین بردار پشتیبان (svm) تبدیل به یک ابزار طبقه بندی محبوب شده است که براساس فراگیری ماشین آماری می باشد (Mohammad et al., 2011). دو موضوع در فراگیری-تمرین ماشین برای مجموعه داده های بزرگ و در دسترس پذیری یک مجموعه داده کامل وجود دارد. اگر مجموعه داده های تمرینی بسیار بزرگ باشند حافظه کامپیوتر کافی نخواهد بود و زمان تمرین بسیار طولانی خواهد بود. سپس، وقتی ما بسته های داده را از یک جریان شبکه می گیریم، ما نمی توانیم اطلاعات کامل شبکه را در اولین فرصت به دست آوریم و بنابراین با افزایش تعداد نمونه ها، یک فراگیری آنلاین مستمر برای بالابردن دقت موردنیاز می باشد. چالش فراگیری افزایشی برای این است تا تصمیم بگیریم که چه چیزی و چه میزان اطلاعات از فراگیری قبلی باید برای تمرین در مرحله فراگیری بعدی انتخاب شود و چگونه با مجموعه داده های جدیدی که در آن مرحله اضافه می شوند باید رفتار کرد. بنابراین کلید فراگیری افزایشی این است که با مجموعه داده های اضافه شده مقابله کنیم بطوریکه اطلاعات نمونه داده اصلی ضمنا حفظ شود.
اکثر روشهای تشخیص نفوذ از الگوریتمهای فراگیری غیر افزایشی استفاده می کنند. با جمع آوری نمونه داده های جدید، زمان تمرین شان مداوم افزایش می یابد، و در همان زمان، آنها مشکلاتی در تنظیم خودشان با تغییرات محیط شبکه دارند. در این مورد، فراگیری افزایشی این قابلیت را دارد که از نمونه های جدید سریع یادبگیرد و مدل اصلی خودشان را اصلاح کنند. روشهای فراگیری افزایشی می توانند بهتر نیازهای تشخیص نفوذ در زمان واقعی را برآورده کرده، و همچنین دقت محاسباتی برنامه های زمان حقیقی را می توانند بهبود بخشند.
یک الگوریتم ماشین بردار پشتیبان افرایشی ساده بردارهای پشتیبان را با تمرین مجموعه داده اولیه به دست می-آورد. مجموعه داده های جدید و بردارهای پشتیبان قبلی درهم ادغام می شوند تا یک مجموعه نمونه جدید را بسازند، و آنها را تمرین می دهند تا بردارهای پشتیبان جدید تولید کنند. این فرایند تا مجموعه داده آخر تکرار می شود. تغییرات مجموعه داده های جدید که منجر به تولید بردارهای پشتیبان می شوند، بااستفاده از نظریه KKT (کان تاکر) تست می شوند. نمونه هایی که شرایط KKT را نقض می کنند ممکن است مجموعه بردار پشتیبان قبلی را تغییر دهند، از اینرو آنها به مجموعه داده های قبلی افزوده می شوند. نمونه هایی که در شرایط KKT صدق می-کنند حذف می شوند چون آنها مجموعه بردار پشتیبان قبلی را تغییر نمی دهند.
این مقاله یک رویکرد فراگیری کارآمد و بهبود یافته از ماشین بردار پشتیبان را پیشنهاد می دهد که براساس ایده حفظ نمونه داده های اصلی و فعلی در کل فرایند فراگیری می باشد. در این رویکرد پیشنهادی، نقاط داده، که بردارهای پشتیبان در افزایش دسته بندی فعلی نیستند اما دارای شانس تبدیل شدن به بردارهای پشتیبان در افزایش بعدی دسته بندی می باشند، انتخاب شده و به عنوان بردارهای پشتیبان مناسب (CSV) حفظ می شوند به طوریکه آنها با مجموعه داده تمرینی جدید ترکیب می شوند که به تمرین بعدی اضافه می شوند. این رویکرد همچنین استراتژی نیمه تقسیم بندی (پارتیشن) را به عنوان بخشی از روش انتخاب CSV معرفی می کند و الگوریتمی را طراحی می کند که CSV-ISVM نامیده شده و از این استراتژی استفاده می کند.
بقیه مقاله به صورت زیر سازماندهی می شود. بخش 2 برخی کارهای تحقیقاتی مربوط به این مقاله را ارائه می دهد. در بخش 3،CSV مبتنی بر SVM افزایشی را معرفی کرده و ادبیات موضوعی (یعنی شرایط KKT و گردشهای ابرصفحه SVM) را توصیف کرده است. بخش 4 تغییر و اصلاح روش حلقه متمرکز را پیشنهاد داده و بخش 5 کار اصلی این مقاله ارتوضیح می دهد یعنی روش نیمه پارتیشن. تمام آزمایشهای این تحقیق در بخش 6 همراه با آنالیزهای لازم نشان داده می شوند. در انتها، بخش 7 نتیجه گیری مقاله و پیشنهاداتی برای تحقیقات آتی را نیز مطرح می کند.
2- کارهای تحقیقاتی مرتبط
بسیاری از کارهای تحقیقاتی که انجام شده اند روشهای فراگیری افزایشی را درنظر می گرفتند که از دسته بندی SVM استفاده می کنند، البته تغییرات مختلف نیز پیشنهاد شده اند. اکثر کارهای تحقیقاتی به نظر می رسند که بهبودهایی را برای عملکرد تشخیص، دقت وغیره پیشنهاد داده اند.
یک رویکرد مبتنی بر SVM افزایشی بنیادی که فراگیری دسته افزایشی با SVM نامیده می شود، توسط Liu و همکاران در سال 2004 پیشنهاد شد، که در آن فقط بردارهای پشتیبان برای افزایش بعدی حفظ شدند، در حالیکه تمام نمونه داده های دیگر حذف می شوند. در واقع، نمونه های حذف شده مقدار اطلاعات کمی درمورد دسته بندی را حمل می کنند. با افزودن مجموعه داده های جدید به افزایش های متوالی فرایند فراگیری، این نمونه داده ها ممکن است بردارهای پشتیبان یا بالعکس باشند. بنابراین در SVMافزایشی ساده مشابه این، دقت دسته-بندی در افزایشهای بعدی به شدت مورد تاثیر قرار گرفته می شود.
WenJian و Wang توضیح دادند که نمونه داده های متکی به ابرصفحه نزدیک بعد از افزودن مجموعه تمرینی جدید فرصتهای بیشتری برای تبدیل شدن به بردارهای پشتیبان را داشتند (Wang, 2008). بنابراین، آنها الگوریتم فراگیری افزایشی مازاد را پیشنهاد دادند که نمونه های مازاد متکی به ابرصفحه نزدیک را حفظ کرده و آنها را به مجموعه داده های جدید در افزایش بعدی اضافه کردند تا چک کنند که آیا آنها به بردارهای پشتیبان تبدیل شدند.
Abstract
In an Incremental Support Vector Machine classification, the data objects labelled as nonsupport vectors by the previous classification are re-used as training data in the next classification along with new data samples verified by KarusheKuhneTucker (KKT) condition. This paper proposes Half-partition strategy of selecting and retaining non-support vectors of the current increment of classification e named as Candidate Support Vectors (CSV) e which are likely to become support vectors in the next increment of classification. This research work also designs an algorithm named the Candidate Support Vector based Incremental SVM (CSV-ISVM) algorithm that implements the proposed strategy and materializes the whole process of incremental SVM classification. This work also suggests modifications to the previously proposed concentric-ring method and reserved set strategy. Performance of the proposed method is evaluated with experiments and also by comparing it with other ISVM techniques. Experimental results and performance analyses show that the proposed algorithm CSV-ISVM is better than general ISVM classifications for real-time network intrusion detection.
1. Introduction
Network intrusion detection is also considered as a pattern recognition problem of classifying the network traffic patterns into two classes e normal and abnormal; according to the similarity between them. Nowadays, in the field of intrusion detection, Support Vector Machine (SVM) is becoming a popular classification tool based on statistical machine learning (Mohammad et al., 2011). There are two issues in machine learning e training of large-scale data sets and availability of a complete data set (Le and Nguyen, 2011; Du et al., 2009a,b). Computer's memory will not be enough and training time will be too long if training data set is very large. Next, when we capture data packets from a stream of a network, we cannot obtain the complete network information in the very first time and hence a continuous online learning is required for high learning precision with increasing number of samples. The challenge of incremental learning is to decide what and how much information from the previous learning should be selected for training in the next learning phase and how to deal with new data sets being added in that phase. So, the key of incremental learning is to cope with increasing data samples while retaining the information of original data samples in the meantime.
Most of the intrusion detection methods use nonincremental learning algorithms. With accumulation of new data samples, their training time increases continuously, and at the same time, they have difficulties in adjusting themselves with changing network environment. On the contrary, incremental learning has ability of rapidly learning from new samples and modifying their original model (Yi et al., 2011). Incremental learning methods can better meet requirements of real-time intrusion detection, and can also improve computational accuracy of real-time applications.
A simple Incremental Support Vector Machine (ISVM) algorithm acquires the support vectors by training the initial sample set. Both new data sets and the previous support vectors are merged to form a new sample set, and train them to produce new support vectors. The process is repeated till the final data set (Makili et al., 2013). Chances of new data samples becoming support vectors are tested using KarusheKuhneTucker theory (Wang et al., 2006). Samples that violate the KKT conditions may change the previous support vector set, and hence they are added to previous data set. Samples that meet KKT conditions are discarded because they don't change the previous support vector set (Karasuyama and Takeuchi, 2010).
This paper proposes an improved and efficient learning approach of Incremental Support Vector Machine based on the idea of retaining the original and current data samples throughout the whole learning process. In this proposed approach, data points, that are not the support vectors in the current increment of classification but have chances of becoming support vectors in the next increment of classification, are selected and retained as the Candidate Support Vectors (CSVs) so that they can be combined with the new training data set that will be added in the next training. This approach also introduces Half-partition strategy as a part of the CSV selection method and devises an algorithm named CSV-ISVM using the strategy.
The rest of the paper is organized as follows. Section 2 presents some of the works related to this paper. In Section 3, CSV based incremental SVM is introduced and background knowledge for the approach (viz. KKT-conditions and SVM hyperplane rotations) is also described. Section 4 proposes modification to the concentric circle method and Section 5 explains the main work of this paper i.e. the Halfpartition method. All the experiments of this research are illustrated in Section 6 along with necessary analyses. At last, Section 7 draws conclusion of the paper and suggests further work too.
2. Related work
Many research works have been done regarding incremental learning methods using SVM classification and, of course, various modifications have also been proposed. Most of the works seem to have suggested improvements on detection performance, accuracy etc.
A basic incremental SVM based approach called Incremental Batch Learning with SVM was suggested by Liu et al. (2004), in which only the support vectors were preserved for the next increment, while all other data samples were discarded. In fact, the discarded samples carry some amount of information about classification. With the addition of new data samples in the following increments of the learning process, these data samples may become support vectors or vice-versa. Therefore, in simple incremental SVM like this, the classification accuracy is seriously affected in the later increments.
WenJian and Wang explained that data samples lying near the hyperplane had greater possibilities of becoming support vectors after adding new training set (Wang, 2008). So, they proposed the Redundant Incremental Learning Algorithm that retained the redundant samples lying near the hyperplane and added them to the new data sets in the next increment to check if they become the support vectors.
چکیده
1- معرفی
2- کارهای تحقیقاتی مرتبط
3- بردارهای پشتیبان مناسب مبتنی بر SVM افزایشی
3-1- شرایط KKT برای ISVM
4- روش حلقه متمرکز بهبودیافته
1-4- انتخاب شعاع R0 و Ri
2-4- محاسبه r
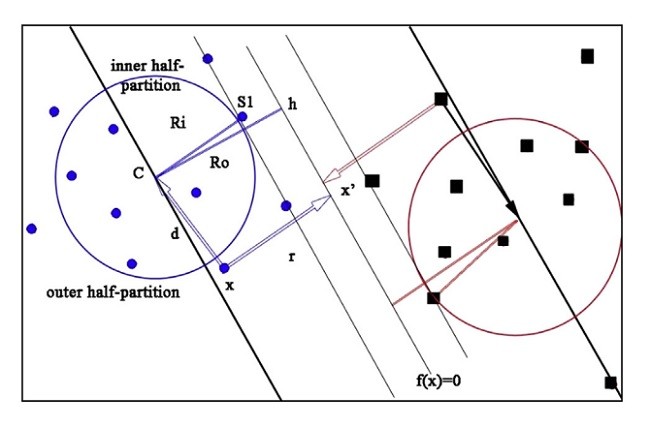
5- استراتژی نیمه پارتیشن
1-5- محاسبه وزن CSV
2-5- تخصیص آستانه
3-5- انتخاب CSV و الگوریتم های CSV-ISVM
6- آزمایش
1-6 داده های تجربی
2-6 پیش پردازش داده ها
3-6- جزئیات تجربی
4-6- ارزیابی و آنالیز عملکرد
7- نتیجه گیری و پیشنهادها
Abstract
1. Introduction
2. Related work
3. Candidate Support Vectors based incremental SVM
3.1. KKT conditions for ISVM
3.2. Rotation of the SV hyperplane
4. The Improved Concentric Circle method
4.1. Selection of radii Ri and Ro
4.2. Calculation of r
5. The Half-partition strategy
5.1. Calculation of weights of CSV
5.2. Threshold assignment
5.3. The CSV selection and the CSV-ISVM algorithms
6. The experiment
6.1. Experimental data
6.2. Data pre-processing
6.3. The experimental detail
6.4. Performance evaluation and analysis
7. Conclusion and further work