
دانلود رایگان مقاله تخصیص عمودی همزمان سلسله مراتبی با استفاده از الگوریتم انرژی پیوند
چکیده
طراحی یک سیستم پایگاه داده توزیع شده موثر (DDBS) به عنوان یکی از چالش برانگیز ترین مشکلات در نظر گرفته می شود به دلیل عوامل متعدد وابسته که بر روی عملکرد آن تاثیر گذار هستند . تخصیص و تکه تکه شدن دو فرآیند هستند که کارآیی و صحت آنها می تواند عملکرد DDBS را تحت تاثیر قرار دهد . بنابراین ، تکه تکه شدن کارآمد داده ها و تخصیص قطعات در سراسر قسمت های شبکه به عنوان یک حوزه مهم پژوهشی در طراحی پایگاه داده های توزیع شده به شمار می آید . در این مقاله ما یک روشی را ارائه می دهیم که در آن به طور همزمان به تکه تکه شدن داده ها و تخصیص قطعات مناسب در سراسر شبکه خواهیم پرداخت . الگوریتم انرژی پیوندی (BEA) با اندازه وابستگی بهتری برای بهبود خوشه های تولید شده از این ویژگی ها مورد استفاده قرار می گیرد . این الگوریتم به طور همزمان خوشه هایی از این ویژگی ها را تولید می کند، هزینه تخصیص هر خوشه به هر کدام از این محل ها را مورد محاسبه قرار می دهد و هر کدام از این خوشه ها را به مناسب ترین محل تخصیص می دهد.
1. مقدمه
پایگاه داده های توزیع شده سبب کاهش هزینه و افزایش کارایی و در دسترس بودن می شوند ، اما طراحی سیستم های مدیریتی پایگاه داده های توزیع شده (DDBMS) پیچیده است . برای امکان پذیر شدن این فرآیند ، آن را به دو مرحله تقسیم می کنیم : تکه تکه شدن و تخصیص . در مرحله تکه تکه شدن سعی می کنیم که داده ها را به تکه هایی تقسیم کنیم ، که باید به محل هایی در طول شبکه در مرحله تخصیص اختصاص داده شود. فرآیند تکه تکه شدن به دو دسته تقسیم می شود : تکه تکه شدن عمودی و تکه تکه شدن افقی . تکه تکه شدن عمودی (VF) از لحاظ پارتیشن بندی رابطه R در مجموعه های متلاشی شده(disjoint) از روابط کوچکتر است در حالیکه تکه تکه شدن افقی (HF) پارتیشن بندی مجموعه R به چندتایی های متلاشی شده است . مشکل تخصیص شامل پیدا کردن توزیع بهینه از تکه تکه شدن مجموعه F در محل مجموعه S است . چهار نوع استراتژی قابل اجرا برای تخصیص داده در رابطه با یک پایگاه داده توزیع شده وجود دارد : متمرکز شده ، تکه تکه شده (پارتیشن)، تکرار کامل و تکرار جزئی (انتخابی) [10]. زمانی که داده ها اختصاص داده شده است ، ممکن است از آنها کپی گرفته شود یا اینکه کپی گرفته نشود . برای همین ، تخصیص قطعه می تواند به صورت فاقد افزونه و با افزونه باشد . در طی طرح تخصیص فاقد افزونه ، دقیقا یک کپی از هر قطعه در سراسر تمامی سایت ها وجود دارد ، در حالیکه در طرح تخصیص افزونه ، بیشتر از یک کپی از هر قطعه در سراسر تمامی سایت ها وجود خواهد داشت [12] . در این کار ، ما تکه تکه شدن را با تکرار جزئی برخی از خوشه های ویژگی ها را انجام می دهیم.
تخصیص و تکه تکه شدن وابسته هستند و تخصیص موثر قطعات داده نیاز به در نظرگیری محدودیت های تخصیص در فرآیند تکه تکه شدن دارد ، اما در اکثر کارهای گذشته این دو مرحله جدا شده است .
دو روش کلی در حل مسائل پارتشین بندی وجود دارد . یکی پیدا کردن راه حلی کارآمد با در نظر گیری برخی از محدودیت ها است . هوفر [13] ظرفیت ذخیره سازی و محدودیت های هزینه های بازیابی را به عنوان عوامل اصلی در نظر گرفته است . هر کدام از این عوامل بر اساس میزان اثر آنها وزن شده است . هدف ما به حداقل رساندن هزینه های کلی بوده است . این وزن ها با استفاده از روش برنامه ریزی خطی مورد محاسبه قرار گرفته است تا مجموع وزن ها برابر با 1 شود.
یک مثال خوب دیگر از اولین مجموعه روش ها در شکولنیک [21] ارائه شده است . این روش سعی می کند که خوشه ای از سوابق را در داخل ساختار سلسله مراتبی سیستم مدیریتی اطلاعاتی (IMS) داشته باشد . درخت سلسله مراتبی تولید شده از لحاظ تعداد گره ها خطی است . گروه بندی اکتشافی با استفاده از روش ارائه شده به وسیله همر و نیامیر [3] صورت گرفته است . این قضیه با تخصیص ویژگی ها به موقعیت های مختلفی آغاز می شود . تمامی نوع های احتمالی از گروه بندی در نظر گرفته می شود و نوعی که نشان دهنده بهترین بهبود در طی نامزد های گروه بندی فعلی است به عنوان نامزد جدید مطرح می شود. گروه بندی و تجدید گروه بندی تا زمانی تکرار می شود که دیگر هیچ پیشرفت بیشتری را انتظار نداشته باشیم . اصلی ترین مشکل در این بین ، جهت حرکت است ، که دارای اثری غالب در کارآیی الگوریتم دارد . یکی دیگر از روش های اکتشافی توسط ما و همکارانش[5] ارائه شده است ، که از یک مدل هزینه و هدف به صورت جهانی و برای به حداقل رساندن هزینه ها استفاده می شود . هدف اصلی ایت است که قطعه بندی بر اساس بهره وری از رایج ترین کوئری ها است . در رفرنس [14] هافر و سورانس خوشه هایی از ویژگی های مشابه را با استفاده از اندازه گیری موثر جفت ویژگی هایی که در رابطه با الگوریتم انرژی پیوندی (BEA) وجود دارد انجام داده اند. یکی از اصلی ترین نقاط ضعف تعداد ویژگی ها در خوشه هایی است که قابل تصمیم گیری نیستند ، و از آنجایی که تنها شباهت های ویژگی هایی دو به دو در نظر گرفته می شود ، برای تعداد بزرگتری از ویژگی ها لازم است . تکه تکه شدن عمودی نیز می تواند در بیشتر از یک فاز انجام شود . این روش توسط نواسه و همکارانش در [23] ارائه شده است . در روش جداسازی دو فازی قطعات به تکه هایی که با یکدیگر تداخل دارند و به قطعاتی که با یکدیگر تداخل ندارند تقسیم می شود . فاز اول بر اساس تابع هدف تجربی است و سپس اجرای آن سبب بهینه سازی هزینه ها با ترکیب دانش از یک محیط خاص نرم افزاری در فاز دوم می شود . این روش توسط لاتیفول و شهیدلو [6] ارائه شده است و یک روشی برای طراحی پایگاه داده های توزیع داده شی است که شامل یک فاز تجزیه و تحلیل برای نشان دادن مناسب ترین روش تکه تکه شدن است ، یک الگوریتم تکه تکه شدن افقی کلاس ، و یک الگوریتم تکه تکه شدن کلاس عمودی است . فاز تجزیه و تحلیل مسئول انتخاب بین تکنیک های پارتیشن بندی افقی و عمودی است ، یا حتی ترکیب هر دوی این تکنیک ها ، به منظور کمک به طراحان توزیع در مرحله تکه تکه شدن پایگاه داده های شی است . بایائو و همکارانش [8] یک روش سه مرحله ای برای طراحی پایگاه داده های توزیع شده شامل فاز تجزیه و تحلیل ، فاز الگوریتم تکه تکه شدن افقی و فاز تکه تکه شدن عمودی کلاس است . این روش توسط ابولیامان در [7] انجام گرفته است که به طور تجربی نشان می دهد که انتقال یک ویژگی که به طور آزادانه در یک پارتیشن قرار دارد سبب بهبود آمار موفقیت ویژگی در پارتیشن می شود.
یک روشی برای تکه تکه شدن افقی هماهنگ و تخصیص توسط عبدالله [4] ارائه شده است . این روش یک مدل هزینه سلسله مراتبی را برای یافتن قطعه و تخصیص بهینه را ارائه می دهند . تکه تکه شدن بر اساس یک مجموعه ای از حالت های ساده است ، و تخصیص بهینه سبب به حداقل رسیدن تابع هزینه می شود . یک روش پارتیشن بندی عمودی سازگار توسط جین و می یانگ [15] ارائه شده است . این مقاله به بررسی پارتیشن بندی عمودی باینری (BVP) [18] می پردازد و نتایج آن را با روش پارتیشن بندی عمودی سازگار (AVP) مقایسه می کند که در آن از یک روش سلسله مراتبی برای روش قطعه قطعه شدن استفاده می شود ، یک درختی از پارتیشن را ایجاد می کند و در نهایت بهترین نتایج آن را انتخاب می کند . یک روش سلسله مراتبی در کار آدرین رونسنو [1] پیاده سازی شده است . در آن روش تدوین تابع هدف اعمال می شود ، با نام ارزیاب پارتیشن [2] ، پیش از اینکه الگورتم های (اکتشافی) را برای مشکلات پارتیشن بندی توسعه دهیم . این روش سبب می شود که ما قادر به مطالعه خواص الگورتیم با توجه به تابع هدف توافق شده باشیم ، و همچنین در مقایسه با الگوریتم های مختلف برای خوبی استفاده از معیار یکسان برای تکه تکه شدن عمودی پایگاه داده های توزیع شده است . یک الگوریتم ابتکاری جدید بر اساس یک تکنیک تجزیه به وسیله محمود و رویردن [16] توسعه داده شده است که تا حد زیادی سبب کاهش مشکل پیچیدگی محاسباتی تخصیص فایل و تخصیص ظرفیت در یک توپولوژی ثابت از شبکه توزیع شده می شود .اگرچه استفاده از یک طرح تکرار جزئی سبب افزایش بهره وری پایگاه داده می شود ، اما این مزیت همراه با هزینه است. این هزینه ، که به طور بالقوه بالا می باشد ، شامل کل هزینه ذخیره سازی ، هزینه پردازش محلی ، و هزینه های ارتباطاتی [19] است . برخی از روش های تکه تکه شدن همراه با بهینه سازی کوئری ، بهینه سازی توزیع ، و بهینه سازی پیوستن است که توسط حکیم زاده و هارون ربابا در [9] پوشش داده شده است . در اینجا ما ارتباطات و هزینه های پردازش های محلی را در ترکیب با دسترسی به کوئری را به حساب می آوریم و سپس هزینه ذخیره سازی کل را به طور جداگانه محاسبه می کنیم .
تکه تکه شدن و تخصیص معمولا به طور جداگانه ای صورت می پذیرد در حالیکه این دو در مرحله طراحی DBMS توزیع شده به طور نزدیکی به یکدیگر مرتبط هستند . دلیل جداسازی این طراحی توزیع شده به دو قسمت به این علت است که بهتر بتوان با پیچیدگی مشکلات مقابله کرد [17].
در اینجا ما یم روش برای VF را ارائه می کنیم ، که بر روی BEA سلسله مراتبی با اندازه گیری شباهت اصلاح شده و به طور همزمان با تخصیص قطعات به مناسب ترین سایت رخ می دهد . علائم این مدل در جدول 1 لیست شده است.
بقیه این مقاله به شرح زیر است. روش ها و عوامل مختلف تاثیر گذار در قسمت 2 مورد بحث قرار گرفته اند . الگوریتم با ذکر جزئیات در بخش 3 توضیح داده شده است . بخش 4 نتایج مقایسه ای از اعمال BEA کلاسیک و روش ارائه شده را بر روی پایگاه داده ها ارائه داده است . در نهایت ، نتیجه گیری و کارهای آینده در بخش 5 ارائه شده است .
Abstract
Designing an efficient Distributed Database System (DDBS) is considered as one of the most challenging problems because of multiple interdependent factors which are affecting its performance. Allocation and fragmentation are two processes which their efficiency and correctness influence the performance of DDBS. Therefore, efficient data fragmentation and allocation of fragments across the network sites are considered as an important research area in distributed database design. This paper presents an approach which simultaneously fragments data vertically and allocates the fragments to appropriate sites across the network. Bond Energy Algorithm (BEA) is applied with a better affinity measure that improves the generated clusters of attributes. The algorithm simultaneously generates clusters of attributes, calculates the cost of allocating each cluster to each site and allocates each cluster to the most appropriate site.
1. Introduction
Distributed databases reduce cost and increase performance and availability, but the design of Distribute Database Management Systems (DDBMS) is complicated. To make this process feasible it is divided into two steps: Fragmentation and Allocation. Fragmentation tries to split data into fragments, which should be allocated to sites over the network in the allocation stage. The process of fragmentation falls into two categories: Vertical Fragmentation and Horizontal Fragmentation. Vertical Fragmentation (VF) is partitioning relation R into disjoint sets of smaller relations while Horizontal Fragmentation (HF) is partitioning relation R into disjoint tuples. The allocation problem involves finding the optimal distribution of fragmentation to set F on site set S. There are four data allocation strategies applicable in a distributed relational database: centralized, fragmentation (partition), full replication, and partial replication (selective) [10]. When data is allocated, it might either be replicated or maintained as a single copy. So, fragment allocation can be either non-redundant or redundant. Under a non-redundant allocation scheme, exactly one copy of each fragment will exist across all the sites, while under redundant allocation schema, more than one copy of each fragment will exist across all the sites [12]. In this work, we combine fragmentation with partial replication of some clusters of attributes.
Allocation and fragmentation are interdependent and efficient data fragment allocation requires considering allocation constraints in the process of fragmentation, but in the most previous works these two steps are separated.
There are two general approaches toward solving the partitioning problem. One is to find the efficient solution by considering some of the constraints. In Hoffer [13] the storage capacity and retrieval cost constraints are the role factors. Each of these factors is weighted based on their amount of effect. The objective was to minimize the value of overall cost. The weights are calculated using linear programming approach so that the sum of the weights is equal to 1.
Another good example of first set of approaches is proposed in Schkolnick [21]. The method tries to cluster records within an Information Management System (IMS) type hierarchical structure. The generated hierarchical tree is linear in the number of nodes. Heuristic grouping is used by the method presented in Hammer and Niamir [3]. It starts by assigning attributes to different positions. All potential types of grouping are considered and the one which represents the greatest improvement over the current grouping candidate becomes the new candidate. Grouping and regrouping are iterated until no further improvement is likely. The main issue is the direction of movement, which has a dominant effect on the efficiency of the algorithm. Another heuristic approach is presented in Ma et al. [5] uses a cost model and targets at globally minimizing these costs. The major objective is to fragment based on efficiency of the most frequent queries. In Hoffer and Severance [14] clusters of similar attributes are generated using the affinity measure between pairs of attributes in conjunction with Bond Energy Algorithm (BEA). One of the major weaknesses is that the number of attributes in clusters are not decidable, and since it only considers pairwise attribute similarity, it is improper for larger numbers of attributes. Vertical fragmentation could also be done in more than one phase. This method is presented in Navathe et al. [23]. A two-phased approach separates fragments into overlapping and non-overlapping fragments. The first phase is based on empirical objective function and then it performs cost optimization by incorporating the knowledge of a specific application environment in the second phase. The method presented in Latiful and Shahidul [6] is a methodology for the design of distributed object databases that includes an analysis phase to indicate the most adequate fragmentation technique, a horizontal class fragmentation algorithm, and a vertical class fragmentation algorithm. The analysis phase is responsible for driving the choice between the horizontal and the vertical partitioning techniques, or even the combination of both, in order to assist distribution designers in the fragmentation phase of object databases. Baiao et al. [8] presents a three phased methodology for the design of distributed database that contains analysis phase, horizontal fragmentation algorithm phase, and vertical class fragmentation phase. The method illustrated in Abuelyaman [7] experimentally shows that moving an attribute that is loosely coupled in a partition improves hit ratio of attribute in partition.
A method for synchronized horizontal fragmentation and allocation is proposed in Abdalla [4]. This method introduces a heuristic cost model to find optimal fragment and allocation. Fragmentation is based on a set of simple predicates, and optimal allocation is the one which minimizes the cost function. An adaptable vertical partitioning method is presented in Jin and Myoung [15]. This article reviews Binary Vertical Partitioning (BVP) [18] and compares its results with the presented adaptable vertical partitioning (AVP) which uses a hierarchical method of fragmentation, creates a tree of partitions and finally selects the best result. A heuristic method is implemented in Adrian Runceanu [1]. It applies the approach of formulating an objective function, named Partition Evaluator [2], before developing (heuristic) algorithms for the partitioning problem. This approach enables studying the properties of algorithms with respect to an agreed upon objective function, and also to compare different algorithms for goodness using the same criteria for distributed database vertical fragmentation. A new heuristic algorithm which is based on a decomposition technique is developed in Mahmoud and Roirdon [16] that greatly reduces the computational complexity of the problem of file allocation and capacity assignment in a fixed topology distributed network. Although using a partial replication scheme increases database efficiency, this benefit comes with some costs. This cost, which could potentially be high, consists of total storage cost, cost of local processing, and communication cost [19]. Some fragmentation methods along with query optimization , distribution optimization, and join optimization are covered in Haroun Rababaah, Hakimzadeh [9]. Here we take into account communication and local processing costs in combination with query access and calculate total storage cost separately.
Fragmentation and allocation are usually performed separately while these two steps of Distributed DBMS design are closely related to each other. The reason for separating the distribution design into two steps is to better deal with the complexity of the problem [17].
Here we present a method for VF, which applies BEA hierarchically with a modified similarity measure and simultaneously allocates the fragments to the most appropriate site. The model notations are listed in Table 1.
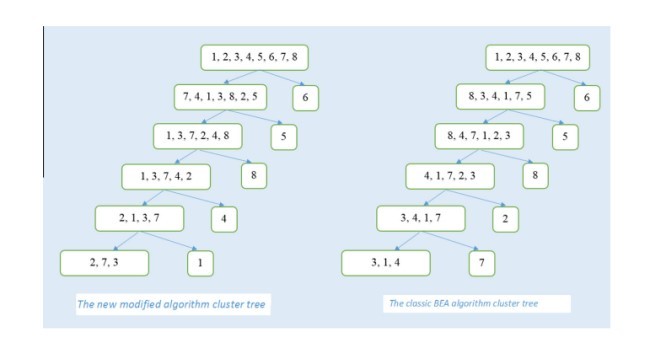
The rest of this article is organized as follows. Methods and different influencing factors are discussed in Section 2. The algorithm is described in details in Section 3. Section 4 draws comparative results of applying both the classic BEA and the presented method on one database. Finally, conclusion and future work are discussed in Section 5.
چکیده
1. مقدمه
2. روش ها
3 . الگوریتم
4. مورد مطالعاتی
5 . جمع بندی
Abstract
1. Introduction
2. Methods
3. Algorithm
4. Case study
5. Conclusion
References