
دانلود رایگان مقاله تخصیص منابع مبتنی بر مکانیسم Gossip برای محاسبات سبز
چکیده
ما به مسئله تخصیص منابع در محیط ابر در مقیاس بزرگ می پردازیم، که بهینه سازی پیکربندی ابر بهصورت پویا برای اهداف محاسبات سبز تحت محدودیت های پردازنده و حافظه را رسمی می کنیم. ما پروتکل عمومی gossip را برای تخصیص منابع پیشنهاد می کنیم، که می تواند برای اهداف خاص معرفی شود. ما نمونه ای از این پروتکل عمومی را باهدف به حداقل رساندن مصرف انرژی از طریق تحکیم سرور توسعه می دهیم، درحالیکه رضایت مندی تغییر الگوی بارگیری برآورده شود. این پروتکل، GRMP-Q نامیده شد، که یک راه حل ابتکاری کارآمد فراهم می کند که در اغلب موارد به خوبی عمل می کند— در موارد خاص، بهینه است. تحت سربار ، پروتکل یک تخصیص عادلانه از منابع پردازنده به خدمات گیرنده را می دهد. نتایج شبیه سازی نشان می دهد که معیارهای کلیدی عملکرد، با افزایش اندازه سیستم تغییر نمی کند، فرآیند تخصیص منابع مقیاس پذیر برای بالاتر از 100000 سرور. بهطورکلی، اثربخشی پروتکل در دستیابی به اهداف خود، با افزایش ظرفیت حافظه در سرورها، افزایش می یابد.
1. مقدمه
مصرف انرژی در مراکز داده قابل توجه است و به سرعت در سال های اخیر رشد کرده است و این رشد انتظار می رود ادامه دار باشد. چند مطالعه آن را نشان می دهد [1]-[3]. یک روش مؤثر برای کاهش مصرف انرژی مراکز داده، تحکیم سرور [4[، [5] است که باهدف تمرکز حجم کار بر روی حداقل تعداد سرورها است. این کار مؤثر است، زیرا امروزه سطح بهره برداری در مراکز داده اغلب پایین است، حدود 15% [6]. برای یک اجرا، سرور بیش از 60% از حداکثر مصرف انرژی خود را مصرف می کند، حتی اگر آن بار حمل نکند ([4])، تعویض سرورها (بهطور موقت) برای یک حالت ضروری نباشد که حداقل یا هیچ انرژی نیاز دارد که می تواند بهطور قابلتوجهی مصرف انرژی را کاهش دهد.
امروزه همه تکنولوژی های کلیدی موردنیاز برای تحکیم سرور، در دسترس هستند. تکنولوژی های مجازی سازی و مهاجرت زنده ، استحکام پویا حجم کار را تحت درخواست پشتیبانی می کند. داشتن سطوح مختلف از حالت آمادهبهکار (مشخص شده با سطوح مختلف مصرف انرژی و زمان بیدار شدن ) که پیشنهادهای تجهیزات مدرن، برای انطباق منابع مرکز داده برای نیازهای در حال تغییر را اجازه می دهد.
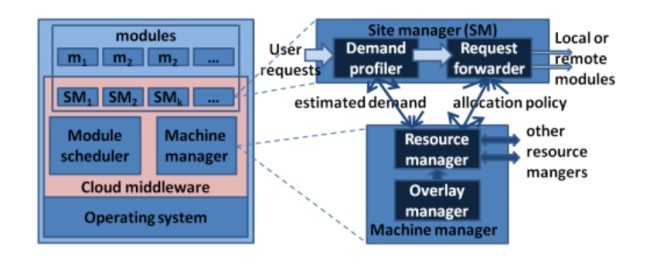
در این کار، ما به مسئله مدیریت منابع برای محیط ابر در مقیاس بزرگ (محدوده بالاتر از 100000 سرور) باهدف خدمت یک حجم کار پویا با حداقل مصرف انرژی می پردازیم. درحالیکه سهم ما در زمینه کلی تری است، ما بحث را از منظر مفهوم PaaS ، با مورد استفاده خاص از یک ارائهدهنده خدمات ابر که سایت های میزبان ها در محیط ابر است، انجام می دهیم. ذینفعان در این مورد استفاده در شکل 1(الف) نشان داده می شود. ارائهدهنده خدمات ابر، زیر ساخت های فیزیکی، که در آن خدمات ابر ارائه شده است را اداره می کند. این، سرویس های میزبانی به صاحبان سایت ها از طریق یک واسط که در زیرساخت هایش اجرا می شود را ارائه می دهد (شکل 2(ب) را ببینید). صاحبان سایت ها خدمات را به کاربران مربوطه خود از طریق سایت هایی که توسط ارائهدهنده خدمات ابر میزبان می شوند ارائه می دهند.
نتایج حاصل از این کار به مهندسی یک لایه واسط که تخصیص منابع در یک محیط ابر را انجام می دهد، با اهداف طراحی زیر کمک می کند.
1) هدف عملکرد
a. وقتی سیستم در زیر بار است، هدف به حداقل رسانی مصرف انرژی است از طریق تثبیت سرور، درحالیکه رضایت مندی تقاضا از سایت های میزبان باشد.
b. وقتی سیستم در سربار است، هدف تخصیص منابع موجود بهطور عادلانه در تمامی سایت های میزبان است.
2) سازگاری: فرآیند تخصیص منابع باید بهصورت پویا و کارآمد برای تغییرات در تقاضا سازگار باشد.
3) مقیاس پذیری: فرآیند تخصیص منابع باید در تعداد سرورهای موجود در ابر و تعداد سایت های میزبان ابر مقیاس-پذیر باشد. بهطور خاص، منابع مصرف شده در هر سرور بهمنظور دستیابی به یک هدف عملکرد معین، باید با تعداد سرورها و تعداد سایت ها افزایش یابد.
رویکرد ما در اطراف یک طراحی غیرمتمرکز مرکزیت می یابد که در آن اجزای لایه واسط در هر سرور از محیط ابر اجرا می شود. (ما در ادامه این مقاله به یک سرور از ابر، بهعنوان یک دستگاه رجوع می کنیم). برای رسیدن به یک مقیاس پذیری، ما تصور می کنیم که تمام وظایف کلیدی لایه واسط، شامل برآورد حالات عمومی ، قرار دادن ماژول های سایت و محاسبه سیاست ها برای درخواست ارسال، براساس الگوریتم های توزیعشده هستند. بر خلاف نرم افزار مدیریت موجود برای ابرهای خصوصی، مانند OpenNebula [8]، OpenStack [9]، AppScale [10] و Cloud Foundry [11]، راه حل پیشنهادی ما، در یک شکل ترکیبشده و یکپارچه فراهم می شود. (الف) انطباق پویا از تخصیص منابع موجود در پاسخ به یک تغییر، (ب) مقیاس گذاری پویا منابع برای یک کاربرد آنسوی یک دستگاه فیزیکی تک و (ج) مقیاس پذیری آنسوی برخی از 100000 سرور.
این مقاله بر اساس کار قبلی ما در مورد مدیریت منابع مقیاس پذیر برای محیط های ابر است [7]. آن از معماری واسط از آن کار را استفاده می کند، رسمی سازی مسئله تخصیص منابع را سازگار می کند و دوباره از مفهوم محاسبات سیاست های تخصیص منابع از طریق پروتکل gossip استفاده می کند. سهم کلیدی این مقاله به شرح زیر است. ابتدا ما پروتکل عمومی gossip را برای مدیریت منابع در محیط ابر معرفی می کنیم که می تواند برای اهداف خاص معرفی شود. سپس، ما مسئله حداقل سازی مصرف انرژی از طریق تثبیت سرور را رسمی می کنیم و یک راه حل ابتکاری در قالب یک نمونه از پروتکل عمومی ارائه می دهیم. درنهایت ما از طریق شبیه سازی اثربخشی پروتکل در مقایسه با یک سیستم ایده آل نشان می دهیم، و ما نشان می دهیم که پروتکل برای ابر بسیار بزرگ به خوبی مقیاس می کند.
ساختار مقاله بهصورت زیر است: بخش 2 معماری یک لایه واسط که مدیریت منابع را برای یک محیط ابر در مقیاس بزرگ انجام می دهد را شرح می دهد. بخش 3 مدل ما برای مدیریت منابع در محیط ابر و راه حل عمومی برای مسئله مدیریت منابع را ارائه می دهد. بخش 4 مسئله خاص موردمطالعه در این مقاله و راه حل ما را ارائه می دهد. راه حل از طریق شبیه سازی در بخش 5 ارزیابی می شود. بخش 6 کارهای مشابه را مرور می کند و بخش 7 نتیجه گیری از این مقاله و شرح کارهای آینده را شامل می شود.
Abstract
We address the problem of resource allocation in a large-scale cloud environment, which we formalize as that of dynamically optimizing a cloud configuration for green computing objectives under CPU and memory constraints. We propose a generic gossip protocol for resource allocation, which can be instantiated for specific objectives. We develop an instantiation of this generic protocol which aims at minimizing power consumption through server consolidation, while satisfying a changing load pattern. This protocol, called GRMP-Q, provides an efficient heuristic solution that performs well in most cases—in special cases it is optimal. Under overload, the protocol gives a fair allocation of CPU resources to clients. Simulation results suggest that key performance metrics do not change with increasing system size, making the resource allocation process scalable to well above 100,000 servers. Generally, the effectiveness of the protocol in achieving its objective increases with increasing memory capacity in the servers.
I. INTRODUCTION
Power consumption in datacenters is significant; it has been growing rapidly in recent years, and this growth is expected to continue, as several studies show [1]–[3]. An effective approach to reducing the power consumption of datacenters is server consolidation [4], [5], which aims at concentrating the workload onto a minimal number of servers. It is effective, because utilization levels in datacenters today are often low, around 15% [6]. As a running server consumes upwards of 60% of its maximum power consumption, even if it does not carry load (cf. [4]), switching servers that are (temporarily) not needed to a mode that requires minimal or zero power can significantly reduce power consumption.
All key enabling technologies required for server consolidation are available today. Virtualization and live migration technologies support dynamic consolidation of workload under changing demand. Having various levels of standby modes (characterized by different levels of power consumption and wakeup time) that modern equipment offers allows to adapt datacenter resources to changing needs.
In this work, we address the problem of resource management for a large-scale cloud environment (ranging to above 100,000 servers) with the objective of serving a dynamic workload with minimal power consumption. While our contribution is relevant in a more general context, we conduct the discussion from the perspective of the Platform-as-a-Service (PaaS) concept, with the specific use case of a cloud service provider which hosts sites in a cloud environment. The stakeholders in this use case are depicted in figure 1a. The cloud service provider owns and administers the physical infrastructure, on which cloud services are provided. It offers hosting services to site owners through a middleware that executes on its infrastructure (see figure 1b). Site owners provide services to their respective users via sites that are hosted by the cloud service provider.
The results from this work contribute to engineering a middleware layer that performs resource allocation in a cloud environment, with the following design goals.
1) Performance objective: (a) When the system is in underload, the objective is to minimize power consumption through server consolidation while satisfying the demand of hosted sites; (b) When the system is in overload, the objective is to allocate the available resources fairly across hosted sites.
2) Adaptability: The resource allocation process must dynamically and efficiently adapt to changes in the demand.
3) Scalability: The resource allocation process must be scalable both in the number of servers in the cloud and the number of sites the cloud hosts. Specifically, the resources consumed per server in order to achieve a given performance objective must increase sublinearly with both the number of servers and the number of sites.
Our approach centers around a decentralized design whereby the components of the middleware layer run on every server of the cloud environment. (We refer to a server of the cloud as a machine in the remainder of this paper.) To achieve scalability, we envision that all key tasks of the middleware layer, including estimating global states, placing site modules and computing policies for request forwarding are based on distributed algorithms. Unlike existing management software for private clouds, such as OpenNebula [8], OpenStack [9], AppScale [10] and Cloud Foundry [11], our proposed solution provides, in a combined and integrated form, (a) dynamic adaptation of existing resource allocation in response to a change, (b) dynamic scaling of resources for an application beyond a single physical machine and (c) scalability beyond some 100,000 servers.
This paper is based on our prior work on scalable resource management for cloud environments [7]. It uses the middleware architecture from that work, adapts the formalization of the resource allocation problem and reuses the concept of computing resource allocation policies through gossip protocols. The key contributions of this paper are as follows. First, we present a generic gossip protocol for resource management in cloud environments which can be instantiated for specific objectives. Second, we formalize the problem of minimizing power consumption through server consolidation and provide a heuristic solution in form of an instance of the generic protocol. Finally, we demonstrate through simulations the effectiveness of the protocol compared to an ideal system, and we show that the protocol scales well to a very large cloud.
The paper is structured as follows. Section II outlines the architecture of a middleware layer that performs resource management for a large-scale cloud environment. Section III presents our model for resource management in cloud environments and our generic solution to the problem of resource management. Section IV presents the specific problem studied in this paper and our proposed solution. The solution is evaluated through simulations in Section V. Section VI reviews related work, and Section VII contains the conclusion of this research and outlines of future work.
چکیده
1. مقدمه
2. معماری سیستم
3. مدل سازی تخصیص منابع و راه حل عمومی ما
A. مدل
GRMP B: پروتکل مدیریت منابع عمومی
4. مسئله و راه حل ما
A. مدیریت منابع بهعنوان یک مسئله بهینه سازی
B. راه حل GRMP-Q ما: یک راه حل ابتکاری برای (OP)
C. خصوصیات GRMP-Q
5. ارزیابی از طریق شبیه سازی
A. عملکرد GRMP-Q تحت CLF و MLF مختلف
6. کارهای مشابه
7. بحث و نتیجه گیری
منابع
Abstract
1. INTRODUCTION
2. SYSTEM ARCHITECTURE
3. MODELING RESOURCE ALLOCATION AND OUR GENERIC SOLUTION
A. The Model
B. GRMP: The Generic Resource Management Protocol
4. THE PROBLEM AND OUR SOLUTION
A. Resource Management as an Optimization Problem
B. Our Solution GRMP-Q: A Heuristic Solution to (OP)
C. Properties of GRMP-Q
5. EVALUATION THROUGH SIMULATION
A. Performance of GRMP-Q under Varying CLF and MLF
B. Scalability
6. RELATED WORK
7. DISCUSSION AND CONCLUSION
REFERENCES