
دانلود رایگان مقاله زمان بندی روندکاری مقید با مهلت سخت با استفاده از الگوریتم فرا ابتکاری
چکیده
برنامه ریزی کارآمد بخش مهمیاز پردازش برنامههای علمیپیچیده در محیطهای توزیع محاسباتی است. پیچیدگی محاسباتی هم از محیط ناهمگن و هم از ساختار برنامه میآید که معمولا به عنوان روند کاری که شامل وظایف مربوطه متفاوتی میشود، نشان داده میشود. تکنیکهای شناخته شدهی بسیاری توسط گروههای علمیمختلف پیشنهاد شده است. محبوبترین آنها در فن آوری هوشمند مبتی بر لیست حریص و یا الگوریتمهای فرا ابتکاری است.در این مقاله قابلیت اجرای الگوریتم فرا ابتکاری از پیش توسعه یافتهی الگوریتم ژنتیک (GCA) برای سریهای زمان بندی در روند کاری با محدودیت شدید زمانی را بررسی میکنیم.
1. مقدمه
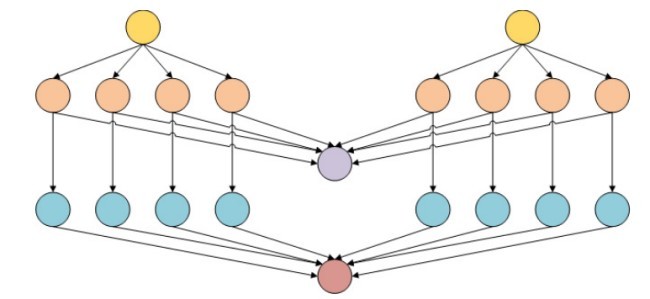
امروزه سیستمهای محاسباتی پیچیده بر اساس شبکه، خوشه یا ابرهای محاسباتی نقش بسیار مهمیدر تحقیقات علمیبازی میکنند، که معمولا از برنامههای مرکب برای اهداف محاسباتی استفاده میکنند. برای اجرای این برنامههادر محیطهای توزیع آنها را به وظایف از هم جدا تقسیم میکنند، که میتوانند در منابع مختلف با محدودیت سمت چپ بر روی وابستگی بین وظایف اجرا شوند. به طور رسمیاین برنامهها روندهای کاری نامیده میشود و توسط نمودار با وظایف تعریف شده بر روی گرهها و وابستگیهای به عنوان لبه ارائه میشوند.
برنامهریزی مناسب برای اجرای برنامههای مرکب، بر منابع موجود بخش مهمیاز حل موثر مشکلات است، که برای ما امکان بررسی مکانیزم بهینه سازی فرآیند برنامه ریزی را به ارمغان میآورد. برای اهداف مختلف معیارهای بهینه سازی مختلفی را میتوان مورد استفاده قرار داد، مانند کل زمان اجرا (makespan)، هزینه، بهرهوری انرژی و غیره. برای محیطهای ابر، هزینه محاسباتی اغلب مهمترین معیار است، زیرا کاربران باید برای مدت زمان استفاده از منابع هزینه پرداخت کنند. برای شبکه، محاسبه makespan روند کار مهم ترین است، چرا که نتایج اجرا منجر به پیشرفت تحقیقات و بسیاری از برنامههای کاربردی مرکب برای بسیاری از کاربرانی که منتظر فرصتی برای شروع اجرا هستند، میشود. در این کار، ما یک مشکل محاسبات فوری که مخصوصا محدودیتهای شدیدی بر زمان اجرا دارد، به نام مهلت سخت را مخاطب قرار داده ایم. برای مثال، اینها برای سیستمهای جلوگیری از خطر جاری شدن سیل، زلزله، بیماریهای همه گیر، آتش و غیره بسیار مهم هستند.
دو گروه اصلی از الگوریتم برای ساخت برنامههای اجرای روند کار استفاده میشوند. گروه اول اکتشافی مبتنی بر لیست است که شامل دو مرحله اصلی رتبه بندی کار و تخصیص منابع بر اساس این رتبه بندی است. یکی از الگوریتم هایی که بیشتر استفاده میشود الگوریتم اولین زمان پایان ناهمگن (HEFT) (عرب نژاد، 2013) با توجه به زمان محاسبه کوتاه و توانایی تولید راه حلهای با کیفیت خوب است. در این کار ما این روش را برای موارد مهلت سخت اتخاذ میکنیم. گروه دوم الگوریتمهای فوق ابتکاری است. الگوریتمهای این گروه معمولا نیاز به زمان بیشتری برای اجرا نسبت به فن آوری هوشمند دارند، اما میتوانند راه حلهای بسیار بهتری پیدا کنند. محبوب ترین الگوریتمهادر این زمینه عبارت هستند از الگوریتم ژنتیک (GA)، بهینه سازی ازدحام ذرات (PSO)، الگوریتم جستجوی گرانشی (GSA)، بهینه سازی کولونی مورچگان (ACO) (Yu J. R., 2008) و به همین ترتیب. در کار ما، الگوریتم ژنتیک مرسوم (CGA) برای موارد مهلت سخت بهبود یافته است.
از سوی دیگر بهینه سازی را نه تنها میتوان توسط جستجوی کارآمد نقشه ی وظایف در منابع محاسباتی بلکه با بهینه سازی منابع برای مجموعه خاصی از وظایف با استفاده از فن آوریهای مجازی سازی که اجازه میدهد تا دوباره تعادل پارامترهای پیکربندی منبع اصلی (پردازنده، حافظه و غیره) با توجه به نیازهای وظایف برقرار شود، انجام داد. در این کار ما این بهینه سازی را نیز در الگوریتم ژنتیک مرسوم جذب میکنیم.
2. کارهای مرتبط
امروزه، دو روش به طور گسترده پر استفاده وجود دارد که محدودیت سخت مهلت برای توسعه سیستمهای زمان واقعی را در نظر میگیرد - الگوریتمهای نرخ یکنواخت (RM) و مهلت نخست اولیه (EDF). در (Buttazzo، 2005) مقایسهای جامع از این الگوریتمها به منظور کشف نقاط قوت و ضعف هر دو الگوریتم و برطرف کردن تصورات غلط مربوط به آنها انجام شد. نشان داده شده است که اگر چه RM پیاده سازی ساده تری دارد، به طور کلی اغلب خواصی که به آن نسبت داده شده است را ندارد، مانند کنترل انحراف یا قابل پیش بینی بودن در شرایط اضافه بار. EDF، از سوی دیگر، اجازه استفاده بهتری از منابع وپاسخ به فعالیتهای نامتناوب را میدهد. با توجه به کار ما، مفهوم RM از اختصاص دادن اولویت برای انجام وظایف برعکس دورههای آنها، دراصلاح HEFT برای پشتیبانی مهلت پیاده سازی شده است.
در حال حاضر، تعداد زیادی از تحقیقات علمی به اجرای روندهای کاری بهینه سازی با توجه به یک یا چند مورد ازپارامترهای کیفیت خدمات (QoS) از جمله مهلت اختصاص داده شده است. به عنوان مثال، Yeoو Buyya در (یئو، 2005) رویکردی برای مسئولیت رسیدگی به توافق سطح خدمات (SLA) در محیطهای توزیع به منظور افزایش کاربرد پذیری خوشه محاسباتی ارائه نمودند. نویسندگان روشی برای وظایف برنامه ریزی با توجه به پارامترهای کیفیت خدمات تعریف شده توسط کاربران، مانند هزینههای محاسباتی و مهلت اجرا پیشنهاد دادند. نویسندگان کارایی الگوریتم در مقایسه با الگوریتمهای قدیمیتر برای ویژگیهایQoS متفاوت را نشان میدهند، اما روش ارائه شده نمیتواند به طور مستقیم در کار ما استفاده شود زیرا نمیتواند چند روند کاری با مهلتهای مختلف و گزینههای سخت را به حساب آورد.
ابریشمی و همکاران (ابریشمی، 2013) الگوریتمیبرای برنامه ریزی، با درنظر گرفتن مهلتها با توجه به مهلت و هزینه محاسبات ارائه و مقایسه نمودند. نویسندگان الگوریتمهای خود را برای به حداقل رساندن هزینه اجرای روندهای کاری و همچنین حفظ مهلتها هدف سازی نمودند. اشکال اصلی الگوریتم پیشنهادی آنها برای استفاده در کار ما این است که آنها تنها یک روند کاری با مهلتها را در نظر گرفتند، حال آنکه در رویکرد ما چند روند کاری با مهلتهای مختلف با ویژگی مهلت سخت را میتوان استفاده نمود. با این حال در آینده برای مقایسه با راه حل مان، فرض بر تطبیق کارآمد ترین الگوریتمهای توصیف شده (به عنوان مثال IC-PCP) برای مورد چند مهلت با گزینه مهلت سخت می نماییم .
در (Bochenina 2014)، Bochenina مطالعهای مقایسهای بر روی الگوریتمهای زمانبندی مختلف برای سیستمهای ناهمگن با توجه به مهلت انجام داد. نویسنده دو روش برای رفتار با محدودیتهای زمانی اجرای روند کار پیشنهاد میکند، که قادر به محاسبه نمودن مهلت نرم روند کاربه منظور ساخت برنامههای زمانی مناسب است.
Abstract
An efficient scheduling is the essential part of complex scientific applications processing in computational distributed environments. The computational complexity comes as from environment heterogeneity as from the application structure that usually is represented as a workflow which contains different linked tasks. A lot of well-known techniques were proposed by different scientific groups. The most popular of them are based on greedy list-based heuristics or evolutionary metaheuristics. In this paper we investigate the applicability of previously developed metaheuristic algorithm – coevolutional genetic algorithm (CGA) for scheduling series of workflows with hard deadlines constraints.
1 Introduction
Today complex computational systems based on Grids, clusters or computational clouds play very important role in applied scientific researches, which usually use composite applications for computational purposes. To execute these applications in distributed environments they are split into separated tasks, which can be run on different resources with left constrains on dependencies between those tasks. Formally these applications are called workflows and are represented by graph with defined tasks on the nodes and dependences as the edges.
Proper scheduling of composite applications’ execution on available resources is essential part of efficient problems solving, it brings us to investigate optimization mechanisms of scheduling process. For different reasons different optimization criteria can be used, such as total execution time (makespan), cost, energy efficiency and etc. For cloud environments computational cost often is the most important measure, since users have to pay for the resources usage time. For the Grid computing the makespan of the workflow is most crucial, because execution results leads to research progress, and a lot of composite applications of many users wait for opportunity to start running. In our work we address to a problem of urgent computing that specifies strong constrains on execution time called hard deadlines. The specifics come from the necessity to have the results exactly on set up time otherwise they become valueless. In example, it's crucial for the preventing system in the hazard of flooding, earthquake, epidemic, fire and etc.
Two main groups of algorithms are used for building workflow execution schedules. The first group is list-based heuristics that includes two main steps task ranking and resource allocation based on this ranking. One of the mostly used algorithms is heterogeneous earliest finish time (HEFT) algorithm (Arabnejad, 2013) due to its short computation time and ability to generate solutions with good quality. In this work we adopted it for hard deadline case. The second group is metaheuristic algorithms. Algorithms of this group usually require more time for execution, than heuristics, but can find much better solutions. The most popular algorithms in this area are genetic algorithm (GA), particle swarm optimization (PSO), gravitational search algorithm (GSA), ant-colony optimization (ACO) (Yu J. R., 2008) and so on. In our work we improved coevolutional genetic algorithm (CGA) for hard deadline cases.
On the other hand optimization can be conducted not only by efficient search of the tasks mapping on the computational resources but also by resources optimization for the certain set of task using virtualization technologies that allow to re-balance main resource configuration parameters (CPU, memory, etc.) according to the tasks needs. In this work we also amuse this optimization in coevolutional genetic algorithm.
2 Related works
Today, there are two widely used approaches that consider hard-deadline constraint for developing real-time systems – Rate Monotonic (RM) and Earliest Deadline First (EDF) algorithms. In (Buttazzo, 2005) comprehensive comparison of these algorithms was performed in order to figure out strong and weak points of both algorithms and dispel misconceptions related to them. It was shown that although RM have simpler implementation, in general it doesn’t have properties often credited to it, such as better jitter control or predictability in overload conditions. EDF, on the other hand, allows better resources utilization and better aperiodic activities responsiveness. Regarding our work, the RM concept of assigning priorities for tasks inversely to their periods was used in HEFT modification to implement deadlines support.
Currently, a large number of scientific researches is dedicated to workflows execution optimization with regard to one or several quality of service (QoS) parameters, including deadlines. For example, Yeo and Buyya in (Yeo, 2005) present an approach to handle service level agreements (SLA) in distributed environments in order to enhance the utility of the computational cluster. Authors propose technique for scheduling tasks with regard to user defined quality of service parameters, such as computational cost and execution deadline. Authors show efficiency of the algorithm in comparison with older algorithm for different QoS characteristics, but proposed approach can’t be directly used in our case since it does not take into account several workflows with different deadlines and hard option as well.
Abrishami et al. in (Abrishami, 2013) present and compare algorithms for scheduling, considering deadlines and computation cost. Authors aim their algorithms to minimize execution cost of workflows as well as to keep their deadlines. The main drawback of proposed algorithms regarding our use case is that they consider only one workflow with deadlines, when in our approach several workflows with different deadlines can be used with hard deadline feature. However in the future we suppose to adapt the most efficient of described algorithms (i.e. IC-PCP) for the case of several deadlines with hard deadline option to compare it to our solution.
In (Bochenina, 2014) Bochenina performs comparative study of different scheduling algorithms for heterogeneous systems considering deadlines. Author proposes two approaches for dealing with workflow execution time constraints, which are able to take into account workflow soft deadlines in order to build proper schedule.
چکیده
1. مقدمه
2. کارهای مرتبط
3. شرح مشکل
3.1 روندهای کاری
3.2 منابع محاسباتی
3.3 شرح مساله
4. راه حل پیشنهادی
4.1 الگوریتم ژنتیک تکاملی مهلت سخت(HDCGA)
4.2 اولین پایان زمان مهلت ناهمگن (DHEFT)
5. آزمایشات
6. نتیجه گیری
منابع
Abstract
1 Introduction
2 Related works
3 Problem statement
3.1 Workflows
3.2 Computational resources
3.3 Problem statement
4 Proposed solution
4.1 Hard deadline coevolutionary genetic algorithm (HDCGA)
4.2 Deadline Heterogeneous Earliest Finish Time (DHEFT)
5 Experiments
6 Conclusion
References