
دانلود رایگان مقاله یادگیری ماشین در داده های بزرگ
چکیده
یادگیری ماشین (ML) بهطور مداوم قدرت خود را در طیف گستردهای از برنامههای کاربردی نشان میدهد. این مسئله در سال های اخیر تا حدودی با توجه به ظهور دادههای بزرگ بیشتر مورد توجه قرار گرفته است. الگوریتم ML هرگز بهترین عملکرد خود را نداشت تا اینکه توسط دادههای بزرگ به چالش کشیده شد. دادههای بزرگ، الگوریتم ML را قادر به کشف الگوهای دقیقتر و پیشبینی به موقع تر و دقیق تر از قبل کردند. از سوی دیگر، چالشهای بزرگی در ML مانند مقیاسپذیری مدل و محاسبات توزیع شده مطرح کرد. در این مقاله، یک چارچوب از ML در دادههای بزرگ (MLBiD) برای هدایت بحث به فرصتها و چالشهای آن معرفی خواهد شد. چارچوب ML محور، شامل مراحل پیش پردازش، یادگیری و ارزشیابی است. علاوه براین، چارچوب شامل چهار جزء دیگر، مانند دادههای بزرگ، کاربران، دامنه و سیستم است. مراحل ML و اجزای MLBiD برای شناسایی فرصتهای مرتبط و چالشها و روشن کردن مسیر کاری آینده در بسیاری از موارد ناشناخته و یا در پژوهش حاضر ارائه شده است.
1. معرفی
تکنیکهای یادگیری ماشین (ML) تاثیرات اجتماعی بزرگی در طیف گستردهای از برنامههای کاربردی مانند بینایی کامپیوتر، پردازش سخنرانی، درک زبان طبیعی، علوم اعصاب، بهداشت و اینترنت اشیا داشته است. ظهور عصر داده ای بزرگ موجب توجه به ML گردید. الگوریتم ML هرگز بهترین نتایج را به همراه نداشت و توسط دادههای بزرگ برای به دست آوردن بینش جدیدی در برنامههای کاربردی مختلف کسب و کار و رفتار انسان به چالش کشیده شد. از یک طرف، دادههای بزرگ اطلاعات بیسابقهای غنی برای الگوریتم ML برای استخراج الگوهای اساسی و ساخت مدلهای پیشبینی فراهم میکند. از سوی دیگر، الگوریتمهای سنتی ML با چالشهای مهمی مانند مقیاسپذیری مقادیر واقعی و پنهان داده های بزرگ رو به رو هستند. با گسترش وسیع دادههای بزرگ، ML در جهت تبدیل دادههای بزرگ به هوش عملی رشد و پیشرفت کرد.
ML به این پرسش که چگونه یک سیستم کامپیوتری بسازیم که به طور خودکار از طریق تجربه بهبود یابد پاسخ میدهد[1]. مشکل ML بهعنوان مشکل یادگیری از تجربه با توجه به برخی از وظایف و اندازهگیری عملکرد اشاره دارد. تکنیکهای ML کاربران را قادر به کشف ساختار زیرین و پیشبینی از مجموعه دادههای بزرگ میکند. ML در تکنیکهای یادگیری کارآمد (الگوریتم)، دادههای بزرگ غنی و محیطهای محاسبات قدرتمند بسیار کارآمد است. بنابراین، ML پتانسیل زیادی دارد تا بخش مهمی از تجزیه و تحلیل دادههای بزرگ [2] گردد.
در این مقاله در مورد تکنیکهای ML در زمینه دادههای بزرگ و محیطهای محاسبات مدرن تمرکز داریم. بهطور خاص، هدف ما بررسی فرصتها و چالشهای ML بر روی دادههای بزرگ است. دادههای بزرگ فرصتهای جدیدی برای ML ارائه میکنند. بهعنوان مثال، دادههای بزرگ قادر به استفاده از یادگیری الگو در چند دانهای و تنوع، از دیدگاههای زیادی در حالت موازی هستند. علاوه براین، دادههای بزرگ فرصتها را برای استنتاج علیت براساس زنجیرهای از دنبالهها فراهم میکنند. با این وجود، دادههای بزرگ چالشهای عمدهای در ML مانند ابعاد بالای دادهها، مدل مقیاسپذیری، محاسبات توزیع شده، جریان داده [3]، سازگاری و قابلیت استفاده معرفی میکنند. در این مقاله، یک چارچوب ML در دادههای بزرگ (MLBiD) برای هدایت بحث به فرصتها و چالشهای آن معرفی میکنیم. این چارچوب ML محور، مراحل پیشپردازش، یادگیری و ارزشیابی را به همراه دارد. علاوه براین چارچوب از چهار جزء دیگر که توسط ML تحت تاثیر قرار میگیرند تشکیل شده است، دادههای بزرگ، کاربران، دامنه و سیستم. اجزای MLBiD و مراحل ML جهت شناسایی فرصتها و چالشها و کارهای آینده در بسیاری از حوزههای ناشناخته پژوهش ارائه شده است.
2. چارچوب یادگیری ماشین در دادههای بزرگ
چارچوب ML در دادههای بزرگ (MLBiD) در شکل 1 نشان داده شده است. MLBiD بر جزء یادگیری ماشین (ML) استوار است، که با چهار جزء دیگر، از جمله دادههای بزرگ، کاربر، دامنه و سیستم تعامل برقرار میکند. فعل و انفعالات در هر دو جهت اتفاق میافتد. به عنوان مثال، دادههای بزرگ بهعنوان ورودی به ML وارد میشوند و خروجی تولید میشود، که به نوبه خود تبدیل به بخشی از دادههای بزرگ میگردد؛ کاربر ممکن است با ML برای ارائه دامنه دانش، ترجیحات شخصی و بازخورد قابلیت استفاده و با اعمال نفوذ نتایج یادگیری بهمنظور بهبود تصمیمسازی تعامل برقرار میکند؛
دامنه میتواند هم بهعنوان یک منبع دانش برای خدمت به راهنمای ML و هم بهعنوان زمینه اعمال در مدل یادگیری استفاده شود؛ معماری سیستم بر چگونگی اجرای الگوریتمهای یادگیری و چگونگی اجرای کارآمد آنها تاثیر دارد و بهطور همزمان پاسخگویی به نیازهای ML ممکن است به یک شرکت طراحی معماری سیستم منجر شود. سپس جزئی از MLBiD بهطور جداگانه معرفی میکنیم.
2.1 یادگیری ماشین
ML معمولا از طریق پردازش دادهها، یادگیری و مرحله ارزیابی (شکل 1 را ببینید) پیگیری میشود. پیش پردازش دادهها کمک میکند تا دادههای خام به "شکل درست" برای مراحل یادگیریهای بعدی آماده شود. دادههای خام به احتمال زیاد بدون ساختار، نویزدار، ناقص و متناقض هستند. گام پیشپردازش، دادهها را به شکلی که میتوان به عنوان ورودی برای یادگیری دادهها از طریق، استخراج، تبدیل، و همجوشی استفاده کرد تبدیل میکند. فاز آموزش، الگوریتمهای یادگیری را انتخاب و پارامترهای مدل را برای تولید خروجی مورد نظر با استفاده از پیش پردازش دادههای ورودی به کار میگیرد. برخی روشهای یادگیری، بهویژه یادگیری بازنمودی، نیز میتواند برای پیش پردازش دادهها استفاده شود. ارزیابی برای تعیین عملکرد مدل به دست آمده بسیار مفید است. برای مثال، ارزیابی عملکرد یک طبقهبندی شامل انتخاب مجموعه داده، اندازهگیری عملکرد، برآورد خطا و آزمونهای آماری است [4]. بررسی نتایج ممکن است به تنظیم پارامترهای انتخاب شده در الگوریتمهای یادگیری و / یا انتخاب الگوریتمهای مختلف منجر شود.
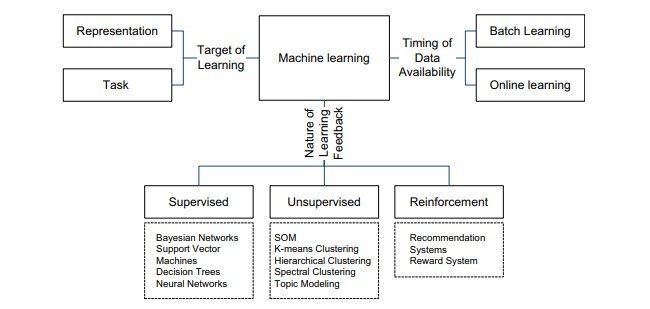
ML میتواند در ابعاد مختلف مشخص گردد: ماهیت یادگیری بازخورد، هدف از وظایف یادگیری و زمان دردسترس بودن دادهها. براین اساس، یک طبقهبندی چندبعدی از ML، همانند شکل نشان داده شده در 2 پیشنهاد میدهیم.
• براساس ماهیت بازخورد دردسترس برای یک سیستم یادگیری، ML را میتوان به سه نوع اصلی طبقهبندی کرد: یادگیری نظارت شده، یادگیری بدون نظارت و یادگیری تقویتی [5]. در یادگیری نظارت شده، یک سیستم یادگیری با نمونههایی از جفتهای ورودی-خروجی ارائه میگردد و هدف ا یادگیری یک تابع است که ورودی را به خروجی نگاشت کند. در یادگیری بدون نظارت، سیستم با بازخورد صریح یا خروجی مورد نظر ارائه نشده است و هدف کشف الگوهایی در ورودی است. همانند یادگیری بدون نظارت، یک سیستم یادگیری تقویتی با جفت ورودی و خروجی ارائه نشده است. مانند یادگیری نظارتی، یادگیری تقویتی براساس تجربههای قبلی عمل میکند. برخلاف یادگیری نظارت شده، بازخورد در یادگیری تقویتی پاداش یا مجازات مرتبط با اقدام به جای خروجی مورد نظر و یا اصلاح صریح و روشن اقدامات مطلوب است. یادگیری نیمه نظارت شده بین یادگیری نظارت شده و نظارت نشده قرار دارد، که در آن سیستم با تعداد کمی از جفتهای ورودی-خروجی و یک تعداد زیادی از ورودیهای نامشخص ارائه شده است. هدف از یادگیری نیمه نظارتی شبیه به یادگیری نظارت شده است.
• براساس اینکه آیا هدف از یادگیری، وظایف خاص با استفاده از ویژگیهای ورودی است، ML را میتوان به یادگیری بازنمودی و یادگیری وظیفه طبقهبندی کرد. هدف از یادگیری بازنمودی، یادگیری نمایشهای جدید داده است که استخراج اطلاعات مفید در هنگام ساختن و یا قبل از طبقهبندی را آسانتر میکند[6]. نمایش خوب باید دارای عوامل زمینهای از تنوع باشد. که اغلب توزیع عوامل اکتشافی زمینهای برای خروجیهای مشاهده شده در مورد مدل احتمالاتی است [6].
ABSTRACT
Machine learning (ML) is continuously unleashing its power in a wide range of applications. It has been pushed to the forefront in recent years partly owing to the advent of big data. ML algorithms have never been better promised while challenged by big data. Big data enables ML algorithms to uncover more fine-grained patterns and make more timely and accurate predictions than ever before; on the other hand, it presents major challenges to ML such as model scalability and distributed computing. In this paper, we introduce a framework of ML on big data (MLBiD) to guide the discussion of its opportunities and challenges. The framework is centered on ML which follows the phases of preprocessing, learning, and evaluation. In addition, the framework is also comprised of four other components, namely big data, user, domain, and system. The phases of ML and the components of MLBiD provide directions for identification of associated opportunities and challenges and open up future work in many unexplored or under explored research areas.
1. Introduction
Machine learning (ML) techniques have generated huge societal impacts in a wide range of applications such as computer vision, speech processing, natural language understanding, neuroscience, health, and Internet of Things. The advent of big data era has spurred broad interests in ML. ML algorithms have never been better promised and also challenged by big data in gaining new insights into various business applications and human behaviors. On the one hand, big data provides unprecedentedly rich information for ML algorithms to extract underlying patterns and to build predictive models; on the other hand, traditional ML algorithms face critical challenges such as scalability to truly unleash the hidden value of big data. With an everexpanding universe of big data, ML has to grow and advance in order to transform big data into actionable intelligence.
ML addresses the question of how to build a computer system that improves automatically through experience [1]. A ML problem is referred to as the problem of learning from experience with respect to some tasks and performance measures. ML techniques enable users to uncover underlying structure and make predictions from large datasets. ML thrives on efficient learning techniques (algorithms), rich and/or large data, and powerful computing environments. Thus, ML has great potential for and is an essential part of big data analytics [2].
This paper focuses on ML techniques in the context of big data and modern computing environments. Specifically, we aim to investigate opportunities and challenges of ML on big data. Big data presents new opportunities for ML. For instance, big data enables pattern learning at multi-granularity and diversity, from multiple views in an inherently parallel fashion. In addition, big data provides opportunities to make causality inference based on chains of sequence. Nevertheless, big data also introduces major challenges to ML such as high data dimensionality, model scalability, distributed computing, streaming data [3], adaptability, and usability. In this paper, we introduce a framework of ML on big data (MLBiD) to guide the discussion of its opportunities and challenges. The framework is centered on ML which follows the phases of preprocessing, learning, and evaluation. In addition, the framework is also comprised of four other components that both influence and are influenced by ML, namely big data, user, domain, and system. The components of MLBiD and the phases of ML provide directions for identification of opportunities and challenges and open up future work in many unexplored or under explored research areas.
2. A framework of machine learning on big data
The framework of ML on big data (MLBiD) is shown in Fig. 1. MLBiD is centered on the machine learning (ML) component, which interacts with four other components, including big data, user, domain, and system. The interactions go in both directions. For instance, big data serves as inputs to ML and the latter generates outputs, which in turn become a part of big data; user may interact with ML by providing domain knowledge, personal preferences and usability feedback, and by leveraging learning outcomes to improve decision making; domain can serve both as a source of knowledge to guide ML and as the context of applying learned models; system architecture has impact on how learning algorithms should run and how efficient it is to run them, and simultaneously meeting ML needs may lead to a co-design of system architecture. Next, we introduce each component of MLBiD separately.
2.1. Machine learning
ML typically goes through data preprocessing, learning, and evaluation phases (see Fig. 1). Data preprocessing helps prepare raw data into the “right form” for subsequent learning steps. The raw data is likely to be unstructured, noisy, incomplete, and inconsistent. The preprocessing step transforms such data into a form that can be used as inputs to learning through data cleaning, extraction, transformation, and fusion. The learning phase chooses learning algorithms and tunes model parameters to generate desired outputs using the preprocessed input data. Some learning methods, particularly representational learning, can also be used for data preprocessing. The evaluation follows to determine the performance of the learned models. For instance, performance evaluation of a classifier involves dataset selection, performance measuring, error-estimation, and statistical tests [4]. The evaluation results may lead to adjusting the parameters of chosen learning algorithms and/or selecting different algorithms.
ML can be characterized in multiple dimensions: nature of learning feedback, target of learning tasks, and timing of data availability. Accordingly, we propose a multi-dimensional taxonomy of ML, as shown in Fig. 2.
• Based on the nature of the feedback available to a learning system, ML can be classified into three main types: supervised learning, unsupervised learning, and reinforcement learning [5]. In supervised learning, a learning system is presented with examples of input-output pairs, and the goal is to learn a function that maps inputs to outputs. In unsupervised learning, the system is not provided with explicit feedback or desired output, and the goal is to uncover patterns in the input. As in unsupervised learning, a reinforcement learning system is not presented with input-output pairs. Like supervised learning, the reinforcement learning is given feedback on its previous experiences. Unlike supervised learning, however, the feedback in reinforcement learning is rewards or punishments associated with actions instead of desired output or explicit correction of sub-optimal actions. Semi-supervised learning falls between supervised and unsupervised learning, where the system is presented with both a small number of input-output pairs and a large number of un-annotated inputs. The goal of semisupervised learning is similar to supervised one except that it learns from both annotated and un-annotated data.
• Based on whether the target of learning is specific tasks using input features or the features themselves, ML can be categorized into representational learning and task learning. Representational learning aims to learn new representations of data that make it easier to extract useful information when building classifiers or other predictors [6]. A good representation is one that disentangles the underlying factors of variation. It is often one that captures the posterior distribution of underlying exploratory factors for the observed output in case of probabilistic models [6].
چکیده
1. معرفی
2. چارچوب یادگیری ماشین در دادههای بزرگ
2.1. یادگیری ماشین
2.2. دادههای بزرگ
2.3. دیگر مولفهها
2.3.1 کاربران
2.3.2 دامنه
2.3.3 سیستم
3. فرصتها و چالشهای پیشپردازش دادهها
3.1. افزونگی دادهها
3.2. نویز دادهها
3.3. ناهمگونی اطلاعات
3.4. مجزاسازی داده
3.5. برچسبگذاری داده
3.6. دادههای نامتوازن
3.7. نمایش ویژگی و انتخاب
4. فرصتهای یادگیری و چالشها
4.1. عدم موازیسازی
4.2. موازیسازی دادهها
4.2.1 میانافزار عمومی دادههای بزرگ برای الگوریتمهای یادگیری موجود
4.2.2 تلاش بر روی الگوریتمهای خاص با دادههای موازی
4.3. مدلها / موازیسازی پارامتر
4.3.1 یادگیری ماشین توزیع شده
4.3.2 موازیسازی الگوریتمهای سنتی ML
4.3.3 یادگیری عمیق
4.4. روشهای ترکیبی
4.5. فرصتها و چالشهای کلیدی
5. فرصتهای ارزیابی و چالشها
6. پژوهشهای آینده و نتیجهگیری
منابع
ABSTRACT
1. Introduction
2. A framework of machine learning on big data
2.1. Machine learning
2.2. Big data
2.3. Other Components
2.3.1. Users
2.3.2. Domain
2.3.3. System
3. Data preprocessing opportunities and challenges
3.1. Data redundancy
3.2. Data noise
3.3. Data heterogeneity
3.4. Data discretization
3.5. Data labeling
3.6. Imbalanced data
3.7. Feature representation and selection
4. Learning opportunities and challenges
4.1. Non-parallelism
4.2. Data parallelism
4.2.1. General big data middleware for existing learning algorithms
4.2.2. Efforts on specific algorithms with parallel data
4.3. Models/parameter parallelism
4.3.1. Distributed machine learning
4.3.2. Parallelization of traditional ML algorithms
4.3.3. Deep learning
4.4. Hybrid approaches
4.5. Key opportunities and challenges
5. Evaluation opportunities and challenges
6. Future research and conclusion
References