
دانلود رایگان مقاله طبقه بندی عمیق تصویر Hyperspectral با CNN متنی
چکیده
در این مقاله که یک شبکه عصبی کانولوشن عمیق جدید (CNN) که عمیقتر و گستردهتر از شبکههای عمیق موجود برای طبقهبندی تصویر Hyperspectral است ارائه شده است. برخلاف روشهای فعلی پیشرفته در طبقهبندی تصویر Hyperspectral مبتنی بر CNN، شبکه پیشنهاد شده به نام CNN عمیق متنی، میتواند بهطور مطلوب تعاملات متقابل محتوا را با بهرهبرداری از روابط فضایی-طیفی محلی از بردارهای پیکسل همسایه، بررسی کند. بهرهبرداری مشترک اطلاعات spatio-spectral توسط فیلترکانولوشن چند مقیاسی که به عنوان جزء اولیه خط لوله پیشنهادی CNN مورد استفاده قرار میگیرد، به دست میآید. ویژگیهای اولیه فضایی و طیفی نگاشتهای حاصل از فیلترکانولوشن چند مقیاسی را با هم ترکیب می کنند تا یک ویژگی مشترک فضایی طیفی ایجاد کنند. ویژگی مشترک نشاندهنده ویژگیهای طیفی و فضایی غنی از تصویر Hyperspectral است و سپس از طریق یک شبکه کاملا متقارن تغذیه میشود که در نهایت برچسب مربوطه هر pixelvector را پیشبینی میکند. مجموعه دادههای استفاده شده در روش پیشنهادی: مجموعه دادههای Pines هند، مجموعه دادههای Salinas و مجموعه دادههای دانشگاه Pavia. مقایسۀی عملکرد نشان میدهد که عملکرد سازگاری پیشرفته در رویکرد پیشنهادی بر روی وضعیت فعلی در سه مجموعه داده نشان داده شده است.
1. مقدمه
اخیرا، شبکههای عصبی کانولوشن عمیق (DCNN) برای طیف گستردهای از وظایف ادراکی بصری مانند تشخیص / طبقهبندی شی، تشخیص عمل / فعالیت و غیره مورد استفاده قرار گرفته است. به دنبال موفقیت قابل توجه DCNN در نمایش تصویر / ویدیو، قابلیتهای منحصر به فرد خود را از استخراج زیر ساختارهای غیرخطی از دادههای تصویری و همچنین شناخت مقولههای محتوای معنایی با بهینهسازی پارامترهای چند لایه استخراج میکند. اخیرا تلاشهای بیشتری برای استفاده از روشهای مبتنی بر یادگیری عمیق برای طبقهبندی HEX (HIPS) صورت گرفته است [1] - [8]. با این حال، در حال حاضر مجموعه دادههای HSI در مقیاس بزرگ در دسترس نیستند، که منجر به فراگیری بهینه DCNN با تعداد پارامترهای زیاد بنا به عدم وجود نمونههای آموزش دیده میگردد. دسترسی محدود به دادههای گسترده، رویکردهای مبتنی بر CNN برای طبقهبندی HSI [1] - [6] را از استفادهی شبکههای عمیقتر و گستردهتر منع میکند که میتواند بهطور بالقوه بهتر از اطلاعات طیفی و فضایی بسیار غنی موجود در تصاویر hypersepctral استفاده کند.
از این رو، رویکردهای مدرن و پیشرفته مبتنی بر CNN، بیشتر به استفاده از شبکههای کوچک مقیاس با تعداد لایهها و گرههای نسبتا کمتر در هر لایه برای کاهش هزینه عملکرد تمرکز میکنند. عمیقتر و گستردهتر به معنای استفاده از تعداد نسبتا بیشتری لایه (عمق) و گره در هر لایه (عرض) است. به این ترتیب، کاهش ابعاد طیفی تصویربرداری hypersepctral به طور کلی از طریق تطبیق با تکنیکهای کم عمق، مانند تجزیه و تحلیل مولفههای اصلی (PCA)، تشخیص اختیاری موضعی (BLDE) [3]، تجزیه و تحلیل اختلال محدودیت زوج و اختلاف ناپیوستگی (PCDA-NSD) [10] و غیره است. با این حال، بهرهبرداری از شبکههای بزرگ در مقیاس بزرگ، هنوز هم مطلوب است تا بهطور مشترک از زیرساختهای غیرخطی ساختار طیفی و فضایی دادههای Hyperspectral ساکن در فضای ویژگیهای چند بعدی استفاده کند. در روش پیشنهادی، قصد داریم یک شبکه عمیقتر و وسیعتر با توجه به مقادیر محدود دادههای Hyper-Terra بسازیم که بتواند بهطور مشترک از اطلاعات طیفی و مکانی هم بهره بگیرد. برای مقابله با مسائل مربوط به آموزش شبکه بزرگ مقیاس در مقدار محدودی از دادهها، یک مفهوم به تازگی معرفی شده از "یادگیری وابسته" را به اثبات میرسانیم که نشاندهنده توانایی قابل توجه برای افزایش قابلیتهای شبکههای بزرگ است. یادگیری وابسته [11] اساس یادگیری زیرگروههای لایهها به نام ماژولها است بهطوریکه هر یک از ماژولها توسط سیگنال وابسته، که تفاوت بین خروجی مورد نظر و ورودی ماژول است بهینه میشود، همانطور که در شکل 1a نشان داده شده است، ساختار وابسته از شبکهها باعث افزایش قابل توجهی در عمق و عرض شبکه میشود که منجر به افزایش یادگیری و در نهایت بهبود عملکرد تولید میشود. بنابراین، شبکه پیشنهاد شده نیاز به پیش پردازش برای کاهش ابعاد دادههای ورودی ندارد.
برای دستیابی به عملکرد بهتری برای طبقهبندی HSI، ضروری است که ویژگیهای طیفی و فضایی به صورت مشترک بهرهبرداری شوند. همانطور که در [1] - [3]، [7]، [8] مشاهده میشود، روشهای حاضر برای طبقهبندی مبتنی بر HSI به طور کامل از اطلاعات طیفی و فضایی استفاده میکنند. دو نوع متفاوت از اطلاعات، طیفی و فضایی، بهطور جداگانه از پیش پردازش به دست میآیند و سپس برای استخراج ویژگیها و طبقهبندی در [1]، [7] پردازش میشوند. هو و همکارانش [2] به طور مشترک اطلاعات طیفی و مکانی را تنها با استفاده از بردارهای پیکسل طیفی منفرد به عنوان ورودی به CNN پردازش کردهاند. در این مقاله با الهام از [12]، یک رویکرد مبتنی بر یادگیری عمیق ارائه میدهیم که از لایههای کانولوشن کامل (FCN) [13] برای استفاده بهتر از اطلاعات طیفی و فضایی از دادههای hypersepctral به کار میرود. در مرحله اولیه CNN عمیق پیشنهاد شده، یک فیلترینگ کانولوشن با مقیاس چندگانه شبیه به "ماژول آغازین" در [12] به طور همزمان توسط نگاشتهای محلی و گرافیکی طیفی ایجاد میشود. بانک فیلتر چندگانه اساسا برای بهره برداری از ساختارهای مختلف فضایی محلی و همچنین همبستگیهای طیفی محلی استفاده میشود. سپس نگاشتهای فضایی و طیفی اولیه تولید شده با استفاده از بانک فلیتر با هم ترکیب میشوند تا یک نگاشت ویژگی spatio-spectral مشترک ایجاد شود که ویژگیهای spatio-spectral غنی از بردارهای پیکسل hypersepctral را تشکیل دهد. نگاشت مشترک ویژگی به نوبه خود به عنوان ورودی برای لایههای بعدی مورد استفاده قرار میگیرد که به طور پیشفرض برچسبهای بردارهای پیکسل hypersepctral مربوطه را پیشبینی میکنند.
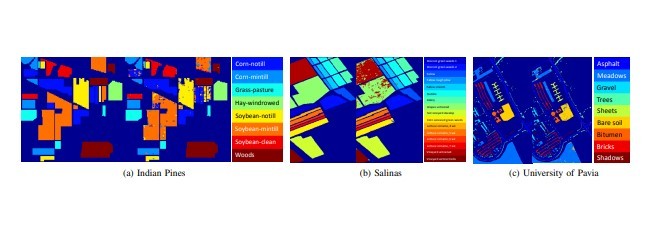
شبکه ارائه شده یک شبکه end-to-end است که بهطور کامل بهینه شده و نیازی به پیشپردازش و پسپردازش ندارد. شبکه پیشنهادی یک شبکه کاملا متقارن (FCN) [13] (شکل 1c) برای گرفتن تصاویر hypersepctral با اندازه دلخواه به عنوان ورودی است و از هیچ لایه زیرنمونهای (pooling) استفاده نمیکند که در غیر این صورت خروجی با اندازههای مختلفی از ورودی را منجر میشود؛ به این معنی که شبکه میتواند تصاویر hypersepctral را با اندازه دلخواه پردازش کند. در این روش، شبکه پیشنهادی را در سه مجموعه دادهی معیار با اندازههای مختلف (145 × 145 پیکسل برای مجموعه دادههای Pines هند، 640 × 340 پیکسل برای مجموعه دادههای دانشگاه پاویا و 217 × 512 برای مجموعه داده Salinas) ارزیابی میکنیم. شبکه پیشنهاد شده از سه مولفه اصلی تشکیل شده است. یک شبکه کاملا مجازی، یک بانک چندرسانهای و یادگیری وابسته همانطور که در شکل 1 نشان داده شده است. مقایسه عملکرد طبقهبندی پیشرفتهی، شبکه پیشنهادی را بر حسب حالت فعلی در سه مجموعه داده نشان میدهد.
موارد مطرح در مقاله به شرح زیر است:
• شبکهی عمیقتر و وسیعتر با کمک "یادگیری وابسته" برای غلبه بر کمبود بهینهگی در عملکرد شبکه که عمدتا ناشی از مقدار محدود نمونههای آموزشی است معرفی میکنیم.
• یک معماری CNN عمیق ارائه میکنیم که میتواند بهطور مشترک اطلاعات طیفی و فضایی تصاویر hypersepctral را بهینهسازی کند.
• روش پیشنهادی یکی از اولین تلاشها برای استفاده از یک شبکه عصبی کاملا پیچیده برای طبقهبندی hypersepctral است.
ادامهی مقاله به شرح زیر سازماندهی شده است. در بخش دوم، کارهای مربوطه شرح داده شده است. جزئیات شبکه پیشنهادی در بخش 3، بیان شده است. مقایسهی عملکرد در میان شبکههای پیشنهادی و رویکردهای فعلی موجود در بخش 4 شرح داده شده است. در بخش پنجم مقاله با نتیجهگیری به پایان رسیده است.
2. کارهای مرتبط
A. ارائهی مسیری عمیقتر با CNN برای شناسایی اشیا / طبقهبندی
LeCun و همکارانش اولین CNN عمیق به نام LeNet5 [15] را که شامل دو لایه کانولوشن، دو لایهی کاملا متصل و یک لایه اتصال Gaussian با لایههای اضافی برای جمع آوری بود، معرفی کرده است. با ظهور پایگاههای تصویری در مقیاس وسیع و تکنولوژی پیشرفته محاسباتی، شبکههای نسبتا عمیقتر و گستردهتر مانند AlexNet [16] در مجموعه دادههای تصویری وسیع مانند ImageNet [17] ساخته شدند. AlexNet از پنج لایه کانولوشن با سه لایه کاملا متصل استفاده میکند. Simonyan و Zisserman [18] عمق CNN را با VGG-16، با 16 لایه کانولوشن، به طور قابل توجهی افزایش دادهاند. Szegedy و همکارانش [12] یک شبکه 22 لایه عمیق را به نام GoogLeNet با استفاده از پردازش چندمرحلهای معرفی کردهاند که با استفاده از مفهوم "ماژول آغازگر" به دست میآید. He و همکارانش [11] یک شبکه عمیقتر از آنچه قبلا استفاده کرده بودند با استفاده از یک روش یادگیری جدید به نام «یادگیری وابسته» ساختند که میتواند به طور قابل توجهی بهبود کارایی آموزش شبکههای عمیق را افزایش دهد.
CNN .B عمیق برای طبقهبندی تصویر
تعدادی از روشهای ارائه شده برای مرتفع کردن مسائل طبقهبندی HSI [4]، [19] - [42] ارائه شدهاند. بهتازگی، روشهای هستهای، مانند یادگیری چندهستهای [19] - [25]، بهطور گسترده مورد استفاده قرار گرفتهاند، زیرا آنها میتوانند یک کلاس را قادر به یادگیری تکاملی محدود به یک پارامتر کنند. این مرز با طراحی دادهها بر روی یک فضای هستهای چندبعدی هیلبرت ساخته شده است [43]. این کار برای استفاده از مجموعه دادهها با نمونههای آموزش محدود مناسب است. بااین حال، پیشرفت اخیر در روشهای مبتنی بر یادگیری عمیق، بهدلیل قابلیتهای آن، میتواند از طریق ساختارهای غیرخطی و پیچیده تصاویر با استفاده از لایههای بسیاری از فیلترهای کانولوشن، بهبود چشمگیر عملکرد را نشان دهد. تا به امروز، چندین روش مبتنی بر یادگیری عمیق [1] - [6] برای طبقهبندی HSI توسعه داده شده است. اما بعضی از آنها به دلیل پیشرفت ناشی از عدم وجود نمونههای آموزش کافی و استفاده از شبکههای نسبتا کوچک مقیاس به پیشرفتهای فراوانی دست یافتند.
Abstract
In this paper, we describe a novel deep convolutional neural network (CNN) that is deeper and wider than other existing deep networks for hyperspectral image classification. Unlike current state-of-the-art approaches in CNN-based hyperspectral image classification, the proposed network, called contextual deep CNN, can optimally explore local contextual interactions by jointly exploiting local spatio-spectral relationships of neighboring individual pixel vectors. The joint exploitation of the spatio-spectral information is achieved by a multi-scale convolutional filter bank used as an initial component of the proposed CNN pipeline. The initial spatial and spectral feature maps obtained from the multi-scale filter bank are then combined together to form a joint spatio-spectral feature map. The joint feature map representing rich spectral and spatial properties of the hyperspectral image is then fed through a fully convolutional network that eventually predicts the corresponding label of each pixel vector. The proposed approach is tested on three benchmark datasets: the Indian Pines dataset, the Salinas dataset and the University of Pavia dataset. Performance comparison shows enhanced classification performance of the proposed approach over the current state-of-the-art on the three datasets.
I. INTRODUCTION
RECENTLY, deep convolutional neural networks (DCNN) have been extensively used for a wide range of visual perception tasks, such as object detection/classification, action/activity recognition, etc. Behind the remarkable success of DCNN on image/video anlaytics are its unique capabilities of extracting underlying nonlinear structures of image data as well as discerning the categories of semantic data contents by jointly optimizing parameters of multiple layers together.
Lately, there have been increasing efforts to use deep learning based approaches for hyperspectral image (HSI) classification [1]–[8]. However, in reality, large scale HSI datasets are not currently commonly available, which leads to sub-optimal learning of DCNN with large numbers of parameters due to the lack of enough training samples. The limited access to large scale hyperspectral data has been preventing existing CNNbased approaches for HSI classification [1]–[6] from leveraging deeper and wider networks that can potentially better exploit very rich spectral and spatial information contained in hypersepctral images. Therefore, current state-of-the-art CNNbased approaches mostly focus on using small-scale networks with relatively fewer numbers of layers and nodes in each layer at the expense of a decrease in performance. Deeper and wider mean using relatively larger numbers of layers (depth) and nodes in each layer (width), respectively. Accordingly, the reduction of the spectral dimension of the hyperspectral images is in general initially performed to fit the input data into the small-scale networks by using techniques, such as principal component analysis (PCA) [9], balanced local discriminant embedding (BLDE) [3], pairwise constraint discriminant analysis and nonnegative sparse divergence (PCDA-NSD) [10], etc. However, leveraging large-scale networks is still desirable to jointly exploit underlying nonlinear spectral and spatial structures of hyperspectral data residing in a high dimensional feature space. In the proposed work, we aim to build a deeper and wider network given limited amounts of hypersectral data that can jointly exploit spectral and spatial information together. To tackle issues associated with training a large scale network on limited amounts of data, we leverage a recently introduced concept of “residual learning”, which has demonstrated the ability to significantly enhance the train efficiency of large scale networks. The residual learning [11] basically reformulates the learning of subgroups of layers called modules in such a way that each module is optimized by the residual signal, which is the difference between the desired output and the module input, as shown in Figure 1a. It is shown that the residual structure of the networks allows for considerable increase in depth and width of the network leading to enhanced learning and eventually improved generation performance. Therefore, the proposed network does not require pre-processing of dimensionality reduction of the input data as opposed to the current state-of-the art techiniques.
To achieve the state-of-the art performance for HSI classification, it is essential that spectral and spatial features are jointly exploited. As can be seen in [1]–[3], [7], [8], the current state-of-the-art approaches for deep learning based HSI classification fall short of fully exploiting spectral and spatial information together. The two different types of information, spectral and spatial, are more or less acquired separately from pre-processing and then processed together for feature extraction and classification in [1], [7]. Hu et al. [2] also failed to jointly process the spectral and spatial information by only using individual spectral pixel vectors as input to the CNN. In this paper, inspired by [12], we propose a novel deep learning based approach that uses fully convolutional layers (FCN) [13] to better exploit spectral and spatial information from hyperspectral data. At the initial stage of the proposed deep CNN, a multi-scale convolutional filter bank conceptually similar to the “inception module” in [12] is simultaneously scanned through local regions of hyperspectral images generating initial spatial and spectral feature maps. The multi-scale filter bank is basically used to exploit various local spatial structures as well as local spectral correlations. The initial spatial and spectral feature maps generated by applying the filter bank are then combined together to form a joint spatio-spectral feature map, which contains rich spatio-spectral characteristics of hyperspectral pixel vectors. The joint feature map is in turn used as input to subsequent layers that finally predict the labels of the corresponding hyperspectral pixel vectors.
The proposed network1 is an end-to-end network, which is optimized and tested all together without additional pre- and post-processing. The proposed network is a fully convolutional network (FCN) [13] (Figure 1c) to take input hyperspectral images of arbitrary size and does not use any subsampling (pooling) layers that would otherwise result in the output with different size than the input; this means that the network can process hyperspectral images with arbitrary sizes. In this work, we evaluate the proposed network on three benchmark datasets with different sizes (145×145 pixels for the Indian Pines dataset, 610×340 pixels for the University of Pavia dataset, and 512×217 for the Salinas dataset). The proposed network is composed of three key components; a novel fully convolutional network, a multi-scale filter bank, and residual learning as illustrated in Figure 1. Performance comparison shows enhanced classification performance of the proposed network over the current state-of-the-art on the three datasets. The main contributions of this paper are as follows:
• We introduce the deeper and wider network with the help of “residual learning” to overcome sub-optimality in network performance caused primarily by limited amounts of training samples.
• We present a novel deep CNN architecture that can jointly optimize the spectral and spatial information of hyperspectral images.
• The proposed work is one of the first attempts to successfully use a very deep fully convolutional neural network for hyperspectral classification.
The remainder of this paper is organized as follows. In Section II, related works are described. Details of the proposed network are explained in Section III. Performance comparisons among the proposed network and current sate-of-the-art approaches are described in Section IV. The paper is concluded in Section V.
II. RELATED WORKS
A. Going deeper with Deep CNN for object detection/classification
LeCun, et al. introduced the first deep CNN called LeNet5 [15] consisting of two convolutional layers, two fully connected layers, and one Gaussian connection layer with additional several layers for pooling. With the recent advent of large scale image databases and advanced computational technology, relatively deeper and wider networks, such as AlexNet [16], began to be constructed on large scale image datasets, such as ImageNet [17]. AlexNet used five convolutional layers with three subsequent fully connected layers. Simonyan and Zisserman [18] significantly increased the depth of Deep CNN, called VGG-16, with 16 convolutional layers. Szegedy et al. [12] introduced a 22 layer deep network called GoogLeNet, by using multi-scale processing, which is realized by using a concept of “inception module.” He et al. [11] built a network substantially deeper than those used previously by using a novel learning approach called “residual learning”, which can significantly improve training efficiency of deep networks.
B. Deep CNN for Hyperspectral Image Classification
A large number of approaches have been developed to tackle HSI classification problems [4], [19]–[42]. Recently, kernel methods, such as multiple kernel learning [19]–[25], have been widely used primarily because they can enable a classifier to learn a complex decision boundary with only a few parameters. This boundary is built by projecting the data onto a highdimensional reproducing kernel Hilbert space [43]. This makes it suitable for exploiting dataset with limited training samples. However, recent advance of deep learning-based approaches has shown drastic performance improvements because of its capabilities that can exploit complex local nonlinear structures of images using many layers of convolutional filters. To date, several deep learning-based approaches [1]–[6] have been developed for HSI classification. But few have achieved breakthrough performance due mainly to sub-optimal learning caused by the lack of enough training samples and the use of relatively small scale networks.
چکیده
1. مقدمه
2. کارهای مرتبط
A. ارائهی مسیری عمیقتر با CNN برای شناسایی اشیا / طبقهبندی
CNN .B عمیق برای طبقهبندی تصویر
3. شبکههای عصبی عمیق
A. شبکه عصبی مصنوعی عمیق
B. معماری شبکه پیشنهادی
.C بانک فیلتر چندمقیاسی
.Dقابلیت بانک فیلتر چندمقیاسی
.Eیادگیری شبکه پیشنهادی
4. نتایج تجربی
A. مجموعه دادهها و پایهها
B. طبقهبندی HSI
.C پیدا کردن عمق و عرض مطلوب شبکه
.D اثربخشی بانک فیلتر چندمقیاسی
.E اثربخشی یادگیری وابسته
.F تغییرات عملکرد با توجه به حجم مجموعه آموزش
.G تجزیه و تحلیل مثبتهای کاذب
5. نتیجهگیری
منابع
Abstract
1. INTRODUCTION
2. RELATED WORKS
A. Going deeper with Deep CNN for object detection/classification
B. Deep CNN for Hyperspectral Image Classification
3. THE CONTEXTUAL DEEP CONVOLUTIONAL NEURAL NETWORK
A. Deep Convolutional Neural Network
B. Architecture of the Proposed Network
C. Multi-scale Filter Bank
D. Residual Learning
E. Learning the Proposed Network
4. EXPERIMENTAL RESULTS
A. Dataset and Baselines
B. HSI Classification
C. Finding the Optimal Depth and Width of the Network
D. Effectiveness of the Multi-scale Filter Bank
E. Effectiveness of Residual Learning
F. Performance Changes according to Training Set Size
G. False Positives Analysis
5. CONCLUSION
REFERENCES