
دانلود رایگان مقاله الگوریتم بهینه سازی عملکرد برای پیکربندی مجدد کنترلر در کنترل پیش بینی مدل توزیع شده
چکیده
در این مقاله یک الگوریتم بهینهسازی عملکرد برای پیکربندی مجدد کنترلر در کنترل پیشبینی مدل توزیعشده با تحملپذیری خطا برای سیستمهای بزرگ مقیاس ارائه شده است. پس از تشخیص خطا در سیستم، چند پیکربندی دیگر برای کنترلر بهعنوان اقدامات اصلاحی برای جبران خسارت خطا انجام میگیرد. راهحلِ مجموعهای از مسائل بهینهسازی محدود با فعالکنندههای مختلف استفاده از یک رویکرد اصلی و بهرهبرداری از اطلاعات مربوط به محدودیت فعال در زیرسیستمهای غیرمعیوب است. بنابراین، مسئله بهینهسازی به دو زیر مسئله بهینهسازی تقسیم میشود، که انجام محاسبات آنلاین تا حد زیادی کاهش مییابد. پس از آن، کارآیی پیکربندیهای مختلف محاسبه شده و از میان آنها پیکربندی با اجرای بهتر انتخاب شده و برای جبران خطا به کار گرفته شده است. تاثیر رویکرد پیشنهاد شده با استفاده از رویکرد Alkylation of benzene، نشان داده شده است که یک فرآیند معیار برای کنترل پیشبینی مدل توزیعشده است.
1. معرفی
افزایش رقابت جهانی، نیاز به محصولات با کیفیت بالاتر و مقررات زیست محیطی، روند صنعت را مجبور میکند تا بهطور مداوم بهرهوری و سودآوری بهینه شود. استراتژیهای پیشرفته کنترل، از جمله کنترل پیشبینی مدل (MPC)، این امکان را به وجود آوردهاند که اجرای فرآیندها نزدیک به کیفیت و محدودیتهای ایمنی با افزایش سودآوری و اطمینان از کیفیت بهتر محصول نهایی و افزایش ایمنی باشند [26]. در مهندسی، معمولا MPC متمرکز نمیتواند کل فرایند در مقیاس بزرگ را مدیریت کند. در عوض، ممکن است MPC ها با هم و بهصورت توزیعشده به تبادل اطلاعات هر سیستم برای دستیابی به اهداف کنترل عمل کنند. برای این منظور، روشهای کنترل توزیعشدهی کارآمد بسیاری در دهههای گذشته توسعه یافتهاند. بهعنوان مثال، Scheu و Marquardt [28] یک روش کنترل پیشبینی مدل توزیعشده (DMPC) براساس الگوریتم بهینهسازی توزیعشده ارائه دادهاند که به هماهنگی در استفاده از حساسیتهای مرتبه اول توابع هدف سیستمهای همسایه متکی است. DMPC پیشنهاد شده میتواند بهطور موثر بار محاسباتی را کاهش دهد و بر محدودیتهای ارتباطی ممکن است در MPC متمرکز غلبه کند. طرحهای DMPC دیگری براساس نظریه بازی [19]، نظریه بازی چانهزنی [1]، و تجزیه پی در پی مسئله متمرکز، طراحی شدهاند [22]. DMPC ها بهطور گسترده در سیستمهای کنترل مختلفی، از جمله فرآیند جدا کردن راکتور، alkylation of benzene [15]، فرآیندهای خنککننده [42]، فرآیند خنککننده تست شتاب دکل [41]، شبکههای حملونقل [22] و شکلگیری رباتهای تک چرخه [8] مورد استفاده قرار گرفتهاند. بنابراین، به یک روش معمول برای استفاده از استراتژی DMPC در فرآیندهای بزرگ مقیاس تبدیل شدهاند (به [4،27،23] نگاه کنید).
طرحهای کنترل معمولی بنا به این فرض که سنسورها و فعالکننده ها عاری از خطا هستند توسعه یافتهاند. بااینحال، وقوع خطا موجب افت کارآیی میشود و همچنین بر ایمنی، بهرهوری و اقتصاد گیاهی تاثیر میگذارد. بهعنوان نتیجه، پژوهش حاضر به تغییر مدیریت پیشرفتهی شرایط غیرطبیعی مانند اختلال و خطا متمرکز است، که هنوز هم فرصت عالی برای بهبود بیشتر کارآیی فراهم میکند. برای این منظور، در سالهای اخیر کنترل تحملپذیری خطا (FTC) توجه زیادی را در علوم مهندسی به خود جلب کرده است (به [2،20،40] مراجعه کنید). در این مقاله، کنترل پیشبینی مدل تحملپذیر خطا (FTMPC)، که خواص تحملپذیری خطا را در MPC جای داده است، بسیار مورد مطالعه قرار گرفته است [18]. اقدامات اصلاحی FTC را میتوان به دو دسته طبقهبندی کرد: تطبیق خطا و پیکربندی دوباره کنترلر، که تفاوت آنها در تغییرات تنظیمات کنترلر برای جبران خطا نهفته است. بهطورخاص، Pranatyasto و Qin [25] FTC مبتنی بر دادهها را با کاتالیزور سیال شبیهسازیشده، مورد مطالعه قرار دادهاند، که در آن سنسور خطا توسط اصول تحلیل مولفه و جایگزینی در MPC تشخیص داده شده است. در Prakash و همکارانش [24]، یک سیستم FTC تطبیق خطا براساس اطلاعات ارائه شده توسط روش نسبت عمومی احتمال توسعه داده شده است. در Kettunen و همکارانش [14]، Sourander و همکارانش [30] و Kettunen و Jämsä-Jounela [13]، راهحلهای مختلفی، از جمله FTMPC مبتنی بر داده با تطبیق خطا، در یک فرایند پیچیده پیشنهاد و تست شده است.
با وجود یک رویکرد جذاب، تطبیق خطا در بسیاری از موارد، بهویژه هنگامی که توانایی کنترل سیستم به دلیل فعالکننده خطا کاهش مییابد غیرعملی است. در نتیجه، یک رویکرد پیکربندی فعالکننده با هدف جایگزینی فعالکننده "کاهش یافته " پیشنهاد شده است. مثلا، Gani و همکارانش [11] دو کنترل تک ورودی و تک خروجی برای یک راکتور پلی اتیلن و دستکاری متغیرهای مختلف کنترل توسعه دادند: دمای جریان و نرخ جریان کاتالیزور. در مورد شکست فعالکننده، کنترل با تکیه بر فعالکننده سالم به کار گرفته میشود. بهطور مشابه، Chilin و همکارانش [5] دو فعالکننده خطا و دو کنترل backup توسعه دادند که به هنگام کشف خطا بهکار گرفته میشوند. بااینحال، در سیستمهای بزرگ مقیاس، استراتژیهای کنترل برای همهی خطاهای احتمالی دشوار و یا حتی غیر ممکن است، به همین دلیل یک مسئله مهم برای اطمینان ثبات پیکربندی مجدد کنترل است، در حالیکه از میان کاندیدهای پیکربندی مجدد انتخاب میشود. بهطور خاص، Gani و همکارانش [11] مناطق ثبات کنترل جایگزین را زمانی که یک فعالکننده خطا رخ میدهد تعیین کردند و Chilin و همکارانش [5] MPC اصلاح شده را برای اطمینان از ثبات به کار بردند. بااینکه هر دو روش قادر به حفاظت از ثبات هستند، یک تابع lyapunov مناسب باید در هر دو روش توسعه یابد، که باعث میشود استفاده آنها در سیستمهای بزرگ مقیاس دشوار باشد.
علاوه براین با استفاده از فعالکننده اضافی، روش دیگری برای کنترل پیکربندی مجدد شامل تعریف یک نقطه جدید تعیین شده برای سیستم معیوب است. در واقع، شرایط عملیاتی فرایند اسمی میتواند گاهی اوقات به دلیل خطا سیستم اتفاق بیافتد، در چنین مواردی، یک نقطه عامل جدید باید تعریف شود. بنابراین، Chilin و همکارانش [5] استفاده از حالت پایدار امکانپذیری در نزدیکی حالت پایدار اسمی سیستم را بهعنوان نقطه هدف جدید پیشنهاد کردند. سابق بر این، Gandhi و Mhaskar [9] رویکرد "safe- parking" را پیشنهاد کرده بودند که نقطه عامل جدید را از میان حالت دایمی و امکانپذیر سیستم توسط کنترل پیکربندی مجدد بدون بیثبات کردن سیستم انتخاب میکرد. Gandhi و Mhaskar [10] همچنین انتخاب نقطه عامل جدید را از واحد معیوب بنا به واحدهای پایین دستی که میتواند در شرایط فرایند اسمی و محدودیتهای اضافی تحمیل شده بر نقاط عامل جدید سیستمهای معیوب ادامه یابد پیشنهاد کرده بودند. در نتیجه، نقطه عامل حاضر در تشخیص خطا، که معمولا به حالت ثابت اسمی نزدیک است، باید به حالت ثبات کنترل پیکربندی مجدد که در شرایط فرآیند جدید به کار گرفته میشود توسعه یابد. اشکال این امر این است که بهدست آوردن ثبات خیلی دشوار است. بنابراین، هنگامی که چندین کنترلر پیکربندی مجدد در دسترس برای جبران خطا داریم، تقاضای روشنی برای راهحلهای عملی، برای ارزیابی پیکربندی کنترل و برای انتخاب بهترین اجرا در یک زمان و به شیوهای مطلوب وجود دارد.
بهتازگی، توانایی شناخته شدهای از MPC برای رسیدن به ردیابی بدون offset در حضور مدل برای توسعه کنترل تحملپذیری خطا استفاده شده است. در Zhang و همکارانش [37]، یک رویکرد بهبودیافته خطی درجه دوم مقاوم در برابر کنترل تحملپذیری خطا طراحی شده است که به یک فرآیند گروهی با فعالکننده جزئی خطا اعمال شده است. مدل زمان گسسته، با حالاتی شامل خطای خروجی ردیابی و تغییر حالت از مدل فرایند واقعی در نظر گرفته شده است. این رویکرد به سیستمهای خطی با تاخیر ورودی-خروجی در Zhang و همکارانش [38،39] و به MPC با استفاده از مدل فضای حالت ورودی و خروجی در Tao و همکارانش [31] اعمال شده است. تحملپذیری خطا میتواند از طریق طراحی کنترل مقاوم، که اغلب به LMIs [33] متکی است بهدست میآید. علاوه براین، Wang و همکارانش [35] یک رویکرد کنترل تحملپذیر خطا برای فرآیندهای دستهای با فعالکننده خطا، براساس کنترل تکرار یادگیری و نمایش دوبعدی پیشنهاد کردند. همین رویکرد قبلا توسط Wang و همکارانش [34] در یک فرآیند گروهی با تاخیر حالت استفاده شده است. وحید نقوی و همکارانش [32] FTMPC غیرمتمرکزی پیشنهاد دادهاند، به این معنی که هیچ تبادل اطلاعاتی بین کنترل محلی مربوط به زیرسیستم وجود ندارد. هر دو طرح کنترل تحملپذیری فعال و غیرفعال خطا در نظر گرفته شده است. با استفاده از روش تابع lyapunov، نشان داده شده است که روش پیشنهادی ثبات ورودی به حالت را تضمین میکند. به منظور تسهیل توسعه یک کنترل پیکربندی مجدد در مورد یک فعالکننده خطا، Luppi و همکارانش [17] بر بهینهسازی ساختار کنترل، که شامل انتخاب متمرکز کنترل و متغیرهای دستکاری شدهی جفت است تمرکز دارند. تحقق شرط کافی کنترل غیرمتمرکز برای تضمین ثبات جستجو شده است. از طریق مطالعه موردی Tennessee Eastman، نشان داده شده است که روش پیشنهادی ساختارهای کنترل غیرمتمرکز مناسبی برای سیستمهای پیکربندی مجدد FTC تولید میکند.
در بسیاری از کارهای گذشته در مورد سیستمهای FTC براساس MPC، برای کل فرایند تنها چندین تلاش برای ایجاد یک استراتژی FTC براساس DMPC در سیستمهای پیچیده وجود دارد [10،7،6]. بااینحال، در تمام این کارها، تنظیمات کنترل توزیعشده تنها در تجزیهوتحلیل پایداری استفاده میشود، نه در انتخاب پیکربندی کنترلر. در این مقاله بهمنظور پر کردن شکاف بین FTC و DMPC، چارچوبی برای طراحی یک استراتژی کنترل مدل پیشبینی توزیعشدهی تحملپذیر خطا (FTDMPC) ارائه شده است. پس از تشخیص خطا، عنصر کلیدی FTDMPC توسعه یافته در این مقاله یک الگوریتم بهینهسازی عملکرد فراهم میکند که راهحل مجموعهای از مسائل بهینهسازی با فعالکنندهی ممکن و مختلف و پیکربندی نقطه تعیین است. الگوریتم بهینهسازی عملکرد از اطلاعات بر روی محدودیتهای فعال زیرسیستمهای غیرمعیوب و مسئله بهینهسازی MPC با تقسیم آن به دو زیرمسئله تودرتو بهره میگیرد. در این مسیر، بار محاسباتی on-line تا حد زیادی کاهش مییابد. متعاقبا، کارآیی پیکربندیهای مجدد کنترلر با کاندیدهای مختلف مقایسه میشود، کنترلر با بهترین اجرا انتخاب شده و پس از آن اجرا میشود، بهطوریکه تاثیر خطاها جبران شود. اثربخشی روش ارائه شده با استفاده از یک فرایند معیار benzene alkylation تایید میشود [15،28،5].
توجه داشته باشید، ما تاکید میکنیم که کار ما بر فعالکننده خطا تمرکز دارد و برای آن ایجاد انگیزه میکنیم. همانطور که از کارهای گذشته ذکر شده در بالا میتوان دریافت، خطاهای سنسور غالبا با استفاده از روش تطبیق خطا جبران میشوند، که به سنسور نرم یا یک تخمین حالت به استثنای اندازهگیری خطا متکی است. بنابراین، یک FTC مبتنی بر تطبیق میتواند با استفاده از دادههای مبتنی بر سنجش نرم و برآورد حالت رویکرد پیادهسازی شود. در مقابل، تطبیق خطا معمولا برای رسیدگی به فعالکننده خطا نامناسب است و اغلب منجر به تخریب عملکرد کنترل میشود. بنابراین شکست در بخشی از بهرهوری فعالکننده میتواند بااستفاده از روش FTC منفعل همانگونه که در ژانگ و همکاران [37،38] نشان داده شده است عمل کند. در این مورد، روشهای مختلف و قوی MPC میتواند برای توسعه FTC و lyapunov برای اطمینان از ثبات در حضور خطا به کار برده شود. بااینحال، فعالکننده خطا در میان خطاهای دشواری قرار دارد، همانگونه که تنها یک پیکربندی مجدد کنترل قادر به جبران اثرات خطا در این مورد است. درحال حاضر، FTCs مرتبط با فعالکننده خطا بیشتر به توسعه کنترل پس از تشخیص خطا میپردازد و روشهای دردسترس کمی برای پشتیبانی از توسعه کنترل پیکربندی مجدد وجود دارد. بنابراین، ما درنظر میگیریم که فعالکننده خطا، نیاز به کنترل آنلاین پیکربندی مجدد، بهعنوان یک مشکل چالشبرانگیز و جالب، به خصوص در مورد فرآیندهای بزرگ مقیاس دارد.
ادامه این مقاله به شرح زیر سازماندهی شده است. در بخش 2، یک ایده کلی از FTDMPC معرفی شده است، که بر عملکرد الگوریتم بهینهسازی عملکرد برای پیکربندی دوباره کنترلر تمرکز دارد. بخش 3 به DMPC برای سیستمهای متصل بدون خطا اختصاص دارد. بخش 4 نشان میدهد که چگونه فرمولبندی مسائلی مانند DMPC اصلی در حضور یک خطا، بهمنظور دربرگیری فعالکننده و نقطه تعیین پیکربندی مجدد اصلاح میشود و چگونه بار محاسباتی که توسط راهحل آن نتیجه شده است با معرفی فرضیات مناسب و انگیزه کاهش مییابد. در بخش 5، نتایج شبیهسازی فرآیند benzene alkylation برای نشان دادن اثرات روش ارائه شده بیان شده است. سرانجام، بخش 6 نتیجهگیری کلی را بیان میکند.
Abstract
This paper presents a performance optimization algorithm for controller reconfiguration in fault tolerant distributed model predictive control for large-scale systems. After the fault has been detected and diagnosed, several controller reconfigurations are proposed as candidate corrective actions for fault compensation. The solution of a set of constrained optimization problems with different actuator and setpoint reconfigurations is derived by means of an original approach, exploiting the information on the active constraints in the non-faulty subsystems. Thus, the global optimization problem is split into two optimization subproblems, which enable the online computational burden to be greatly reduced. Subsequently, the performances of different candidate controller reconfigurations are compared, and the better performing one is selected and then implemented to compensate the fault effects. Efficacy of the proposed approach has been shown by applying it to the benzene alkylation process, which is a benchmark process in distributed model predictive control.
1. Introduction
Increased global competition, higher product quality requirements and environmental regulations have forced the process industry to continuously optimize efficiency and profitability. Advanced control strategies, such as model predictive control (MPC), have made it possible to run processes close to the quality and safety limits thereby increasing profitability, whilst ensuring better end product quality and enhancing safety in plants [26]. In the engineering practice, one centralized MPC usually cannot handle the whole large-scale process; instead, several MPCs may work together in a distributed manner to exchange the information of each system to achieve the control objectives. To this end, highly efficient distributed control methods have been developed over the past decades. For instance, Scheu and Marquardt [28] have developed a distributed model predictive control (DMPC) methodology based on a distributed optimization algorithm, which relies on a coordination mechanism using the first-order sensitivities of the objective functions of neighboring systems. This proposed DMPC can effectively reduce the computational burden and overcome possible communication limitations of the centralized MPC. Several other DMPC schemes have been designed based on cooperative game theory [19], bargaining game theory [1], and serial decomposition of the centralized problem [22]. DMPCs are more and more widely applied to various control systems, such as reactorseparator processes [16], alkylation of benzene [15], hot-rolled strip laminar cooling processes [42], accelerated cooling process test rig [41], transportation networks [22], and formation of unicycle robots [8]. Thus, it has become a common practice to utilize DMPC strategies in large-scale processes (see also [4,27,23]).
Conventional control schemes are developed under the assumption that sensors and actuators are free from faults. However, the occurrence of faults causes degradation in the closed-loop performance and also has an impact on safety, productivity and plant economy. As a result, the research focus is shifting towards advanced management of abnormal situations, such as process disturbances and faults, which still provides great possibilities for further improvement of the process efficiency. To this end, fault tolerant control (FTC) has attracted much attention in the area of engineering practice in recent years (see, e.g., [2,20,40]). In this context, fault tolerant model predictive control (FTMPC), which incorporates fault tolerance properties into MPC, has been extensively studied ever since the earlier contribution by Maciejowski [18]. The corrective actions of FTC can be categorized into two types: fault accommodation and controller reconfiguration, whose difference lies in whether the controller settings will change for the compensation of fault effects or not. In particular, Pranatyasto and Qin [25] studied the data-based FTC with a simulated fluid catalytic cracking unit, where the sensor faults were detected by principal component analysis and accommodated in the MPC. In Prakash et al.[24], a fault-accommodation based FTC system was developed on the basis of diagnostic information provided by the generalized likelihood ratio method. In Kettunen et al.[14], Sourander et al.[30] and Kettunen and Jämsä-Jounela [13], various solutions, including data-based FTMPC with fault accommodation, were proposed and tested in a complex dearomatization process.
Despite being an attractive approach, fault accommodation is infeasible in many cases, especially when the ability to control the system degrades because of an actuator fault. As a result, an actuator reconfiguration approach was proposed, aiming to replace the “dropped out” actuator by means of redundant ones. For example, Gani et al. [11] developed two alternative single-input singleoutput controls for a polyethylene reactor, manipulating different control variables: the temperature of a feed flow and a catalyst flow rate. In the case of an actuator failure, the control relying on the healthy actuator is applied. Similarly, Chilin et al.[5] considered two actuator faults and developed two back-up controls which are applied when the respective fault is discovered. However, in largescale systems, it is difficult, or even impossible, to develop back-up control strategies for all possible faults, that is why it is an important issue to ensure plant stability under an on-line reconfigured control, while selecting among the candidate reconfigurations. In particular, Gani et al. [11] determined the stability regions of the alternative controls when an actuator fault occurs, and Chilin et al. [5] utilized a modification of MPC to ensure stability. Even though both approaches were able to safeguard stability, a suitable Lyapunov function must be developed in both methods, which makes them difficult to use in case of large-scale systems.
Besides using redundant actuators, another approach to controller reconfiguration consists in defining a new setpoint for the faulty system. Indeed, the nominal process operating conditions can sometimes become infeasible because of the fault and, in such a case, a new operating point must be defined. Thus, Chilin et al. [5] proposed to use the feasible steady state closest to the nominal steady state of the system as the new target operating point. Formerly, Gandhi and Mhaskar [9] had suggested a “safe-parking” approach which selects new operating points from amongst the feasible steady states of the system achievable by the reconfigured control without destabilizing the system. Gandhi and Mhaskar [10] had also proposed the selection of new operating points of the faulty unit in a way that the downstream units could continue operating at the nominal process conditions and this was implemented as additional constraints imposed on the new operating points of the faulty systems. As a result, the operating point at the moment of fault diagnosis, which is typically close to the nominal steady state, must belong to the stability region of the reconfigured control that is developed to operate at new process conditions. The drawback is that this makes stability even more difficult to obtain. Therefore, when we have several controller reconfigurations available to compensate for the fault effects, there is a clear demand for more practical solutions to evaluate the possible controller reconfigurations and to select the better performing one in a timely and optimal manner.
Lately, the well-known ability of MPC to achieve offset-free tracking in the presence of plant-model mismatch has been utilized for fault tolerant control development. In Zhang et al. [37], an improved linear quadratic fault-tolerant control approach has been designed and applied to a batch process with partial actuator faults. A discrete-time augmented model has been considered, with the state including the output tracking error and the change of the state of the actual process model. This approach has been extended to linear systems with an input-output delay in Zhang et al. [38,39] and to MPC utilizing the input-output state-space model in Tao et al. [31]. Alternatively, fault tolerance can be achieved through robust control design, which frequently relies on LMIs [33]. Moreover,Wang et al.[35] has proposed a fault tolerant control approach for batch processes with actuator faults, based on iterative learning control and 2D model representation. The same approach has been formerly applied by Wang et al. [34] to a batch process with a state delay. Vahid Naghavi et al. [32] has proposed a decentralized FTMPC, meaning that there is no information exchange between the local controllers relating to subsystems. Both passive and active fault tolerant control designs have been considered. Using Lyapunov function approach, it has been shown that the proposed method guarantees input-to-state stability. In order to facilitate the development of a reconfigured control in case of an actuator fault, Luppi et al.[17]has focused on the optimization of the control structure, which includes the selection of controlled and manipulated variables as well as their pairings. The fulfillment of a sufficient condition for decentralized integral controllability is searched to guarantee stability. Through the Tennessee Eastman case study, it has been shown that the proposed methodology produces suitable decentralized control structures for reconfigurable FTC systems.
As most of the FTC systems in the literature are based on a centralized MPC for the whole process, there have been only a few attempts to establish a FTC strategy based on DMPC for complex industrial systems [10,7,6]. However, in all these works, the distributed control settings are only used in stability analysis, not in the choice of controller reconfigurations. In order to bridge the gap between FTC and DMPC, a framework for the design of a fault tolerant distributed model predictive control (FTDMPC) strategy is presented herein. After the fault has been detected and diagnosed, the key element of the FTDMPC developed in this work is the performance optimization algorithm, which provides the solution of a set of constrained optimization problems with different, possible actuator and setpoint reconfigurations. The performance optimization algorithm utilizes the information on the active constraints in the non-faulty subsystems and tackles the global MPC optimization problem by splitting it into two nested subproblems. In this way, the on-line computational burden is greatly reduced. Subsequently, the performances of the different candidate controller reconfigurations are compared, the best performing controller is selected and then implemented, so as to compensate the effects of the fault. The effectiveness of the proposed method has been verified by applying it to a benchmark benzene alkylation process [15,28,5].
On a last introductory note, we underline that our work is focused on actuator faults and we provide the motivations for this. As it can be seen from the literature review presented above, sensor faults are frequently compensated by means of the fault accommodation approach, which relies on a soft sensor or a state estimation with excluding the faulty measurement. Thus, an accommodation-based FTC can be implemented utilizing the welldeveloped disciplines of data-based soft-sensing and process state estimation. In contrast, fault accommodation is usually unsuitable to handle actuator faults, frequently leading to major control performance degradation. Instead, a partial failure of actuator efficiency can be treated using the passive FTC approach, as is shown, for instance, in Zhang et al. [37,38]. In this case, various robust MPC methods can be employed for FTC development and the Lyapunov function approach is commonly used to ensure stability in the presence of a fault. However, the stuck actuator faults are among the most difficult failures to handle, as only a control reconfiguration is able to compensate fault effects in this case. At the moment, FTCs dealing with actuator faults mostly switch to a pre-developed back-up control after fault detection, and there is little methodology available to support reconfigured control development. Thus, we consider the actuator faults, requiring online control reconfiguration, as a challenging and interesting problem, especially in the case of large-scale processes.
The remainder of this paper is organized as follows. In Section 2, a general idea of FTDMPC is introduced, which focuses on the function of the performance optimization algorithm for the controller reconfiguration. Section 3 is devoted to the DMPC for faultless interconnected systems. Section 4 shows how the formulation of the original DMPC is modified in the presence of a fault, in order to encompass actuator and setpoint reconfiguration, and how the computational burden implied by its solution is reduced with the introduction of suitable, motivated assumptions. In Section 5, simulation results from a benzene alkylation process are provided to demonstrate the effectiveness of the devised approach. Finally, Section 6 outlines the overall conclusions.
چکیده
1. معرفی
2. نمای کلی درکنترل پیشبینی مدل توزیعشده با تحملپذیری خطا
3. مسئله کنترل پیشبینی مدل توزیعشده برای سیستمهای بزرگ مقیاس بیعیب
4. مسئله کنترل پیشبینی مدل توزیعشده برای سیستمهای بزرگ مقیاس معیوب، با فعالکننده و پیکربندی مجدد نقطه تعیین
5. نتایج شبیهسازی
5.1. شرح فرایند
5.2. استراتژی MPC توزیعشده
5.3. تشخیص خطا و روش تشخیص
5.4. تست عملکرد FTDMPC مبتنی بر بهینهسازی
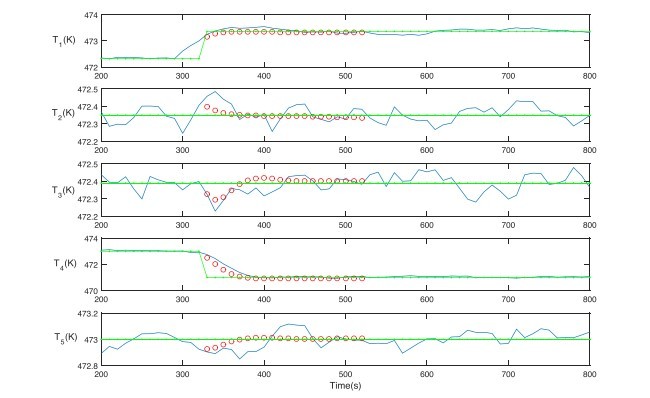
5.4.1. مطالعه موردی 1: ارزیابی فعالکنندهی کاندید
5.4.2. مطالعه موردی 2: چک کردن نقطه عاملی که بهتازگی تعریف شده
5.4.3. یک نکته در مورد بار محاسباتی
6. نتیجهگیری
منابع
ABSTRACT
1. Introduction
2. Outline of the fault tolerant distributed model predictive control
3. The distributed model predictive control problem for the faultless large-scale system
4. The distributed model predictive control problem for the faulty large-scale system, with actuator and setpoint reconfiguration
5. Simulation results
5.1. Process description
5.2. Distributed MPC strategy
5.3. Fault detection and diagnosis approach
5.4. Testing of the performance optimization-based FTDMPC
5.4.1. Case study 1: evaluating candidate actuator reconfigurations
5.4.2. Case study 2: checking newly defined operating point
5.4.3. A note on the computational burden
6. Conclusions
References