
دانلود رایگان مقاله کاهش تعداد الگوهای مشابه مکرر بدون از دست دادن اطلاعات
چکیده
استخراج الگوهای مکرر یک کار، کلیدی برای کشف اطلاعات مفید است. با وجود کیفیت راه حل های داده شده توسط الگوریتم های یافتن الگوهای مکرر ، اکثر آنها با چالش چگونگی کاهش تعداد الگوهای مکرر بدون از دست رفتن اطلاعات مواجه می شوند. یافتن مجموعه های مکرر این مشکل را با کشف یک مجموعه کاهش یافته از مجموعه مکرر، به نام مجموعه های مکرر بسته، که از آن می توان تمام مجموعه الگوی مکرر را بازیابی کرد، حل می کند. با این حال، برای یافتن نمونه های مکرر مشابه، که در آن تعداد الگوها حتی از مجموعه یابی مکرر بزرگتر هستند، این مشکل هنوز حل نشده است. در این مقاله، ما مفهوم یافتن الگوی مشابه مکرر بسته را برای کشف تعدادی از الگوهای مکرر مشابه بدون از دست دادن اطلاعات معرفی می کنیم. علاوه بر این،یک الگوریتم جدید یافتن الگوی مشابه مکرر بسته با نام CFSP-Miner پیشنهاد شده است. الگوریتم، الگوهای مکرر را با عبور از یک درخت که شامل تمام الگوهای مشابه شبیه بسته است، می یابد. برای انجام این کار به صورت موثر، چندین لم برای پر کردن فضای جستجو معرفی و اثبات شده است. نتایج نشان می دهد که CFSP-Miner کارآمدتر از الگوریتم های مورد استفاده یافتن الگوی مشابه مکرر است، مگر اینکه در مواردی که تعدادی از الگوهای مشابه مکرر و الگوهای مشابه مکرر بسته تقریبا برابر باشند. با این حال، CFSP-Miner قادر به پیدا کردن الگوهای مشابه بسته، تولید اندازه کاهش یافته از الگوی مشابه مکرر کشف شده بدون از دست دادن اطلاعات است. همچنین، CFSP-Miner در حین عملکرد قابل قبول در حین اجرا، مقیاس پذیری خوبی را نشان می دهد.
1. مقدمه
یافتن الگوهای مکرر یک تکنیک است که شامل یافتن الگوهایی است (یعنی مجموعه های ویژگی با مقادیر مربوطه) که اغلب رخ می دهد (بیشتر یا برابر با حداقل آستانه تکرار) در یک مجموعه داده. این یک کار کلیدی در داده کاوی به دلیل استفاده از آن برای کشف اطلاعات مفید است مانند عوامل خطر (Li، Fu و Fahey، 2009؛ Li و همکاران، 2005؛ ناهار، امام، تلخه و چن، 2013) پروفایل های کاربر (Chiu، Yeh، & Lee، 2013)، رفتار انسان (Wen، Zhong، & Wang، 2015)، نرم افزارهای مخرب (Fan، Ye، & Chen، 2016) و غیره. علاوه بر این، یافتن الگوی مکرر را می توان به عنوان قدم قبلی یا داخلی برای سایر وظایف استخراج داده ها، مانند استخراج قواعد مرتبط (Alatas، Akin & Karci، 2008؛ Kalpana & Nadarajan، 2008؛ Lopez، Blanco، Garcia، Cano، & مارین، 2008)، طبقه بندی (هرناندز-لون، کاراسکو-اوچوا، مارتینز-ترینیداد و هرناندز-پالانکار، 2012؛ نگوین و نگوین، 2015) و خوشه بندی (Beil، Ester، Xu، 2002) استفاده کرد.
از سال 1990، اکثر الگوریتم های یافتن الگوی مکرر بر اساس تطابق دقیق ویژگی های بولین برای مقایسه و شمارش الگوها بود. این زیرمجموعه الگوریتم های یافتن الگوهای مکرر، یافتن اقلام مکرر نامیده می شود (به عنوان روش معمول برای یافتن الگوی مکرر). با این حال، اشیاء واقعی زندگی مانند اشیاء در جامعه شناسی (Ruiz-Shulcloper & Fuentes-Rodríguez، 1981)، زمین شناسی (گومز-هررا، رودریگز مورن، والاداراس آمرو و همکاران، 1994)، پزشکی (Ortiz-Posadas، Vega - Alvarado، & Toni، 2009) یا بازیابی اطلاعات (Baeza-Yates، Ribeiro-Neto و همکاران، 1999)) به ندرت مساوی هستند و یا با ویژگی های غیر بولین توصیف می شوند. به این ترتیب، توابع تشابه متفاوت از تطبیق دقیق برای مقایسه توصیف های شیء ارائه شده است که به ایجاد یک رویکرد جدید به نام یافتن الگوی مشابه مکرر می پردازد که می تواند مجموعه داده های حاوی ویژگی های غیر بولین را با استفاده از توابع شباهت کنترل کند(Danger، Ruiz-Shulcloper، & Llavori، 2004؛ رودریگز گونزالز، مارتینز-ترینیداد، کاراسکو-اوچوا و رویز شولکلپر، 2008؛ 2011؛ 2013). این روش الگوهایی را ایجاد می کند که نمی تواند توسط آن الگوریتم ها بر اساس تطابق دقیق پیدا شود. الگوهای مکرر که با استفاده از یک تابع شباهت به دست می آیند، نامهای مرسوم مشابهی دارند (Rodríguez-González، Martínez Trinidad، Carrasco-Ochoa، & Ruiz-Shulcloper، 2013).
با وجود کیفیت راه حل های داده شده توسط یک الگوریتم یافتن اقلام مکرر و یا یک الگوریتم یافتن الگوهای مکرر مشابه، یک نقص مهم در هر دو روش این است که اگرچه یک مجموعه کامل از اقلام مکرر یا الگوهای مشابه مکرر می تواند یافت شود، تعداد الگوهای مکرر اغلب بیش از حد بزرگ است. (Burdick، Calimlim، و Gehrke، 2001؛ Hu، سونگ، Xiong و فو، 2008؛ Pei، هان، Mao و همکاران، 20 0 0؛ Rodríguez-González و همکاران، 2013؛ Zaki و Hsiao، 2002)
بنابراین، مفید است که مجموعه ای از تمام الگوهای مکرر را بدون از دست دادن اطلاعات بدست آورید (به عنوان مثال، از آنجا که کل مجموعه الگوی مکرر می تواند بازیابی شود). یکی از راه های انجام این کار، استفاده از یافتن اقلام مکرر بسته (Prabha، Shanmugapriya، & Duraiswamy، 2013) است. الگوریتم های استخراج مکرر بسته تعریف می کنند که یک مجموعه اقلام مکرر بسته شده است، اگر هیچ الگوی فوق العاده با همان فرکانس ندارد و از این تعریف برای پیدا کردن مجموعه های مکرر بسته استفاده می شود. از چنین مجموعه های بسته، مجموعه کامل مجموعه های مکرر می تواند بدون از دست دادن اطلاعات تولید شود. الگوریتم های استخراج الگوهای مکرر به اصطلاح بسته نیز دارای کارایی کارآمدتری نسبت به الگوریتم های استخراج مکرر اقلام هستند (Pei et al.، 20 0 0؛ Uno، Asai، Uchida، & Arimura، 2003؛ Zaki & Hsiao، 2002).
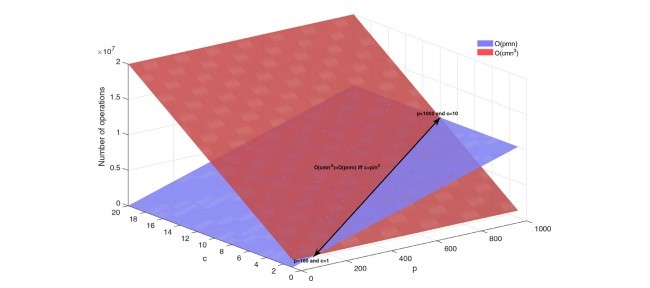
با این حال، مفهوم الگوهای بسته شده برای الگوهای مکرر مشابه به بهترین دانش ما مورد بهره برداری قرار نگرفته است. در این مقاله مفهوم یک الگوی مشابه مکرر مشابه و یک الگوریتم معکوس الگوریتم مشابه مکرر بسته به نام CFSP-Miner معرفی شده است که مجموعه ای از بسته های کاهش یافته از الگوهای مشابه مکرر را بدون از دست دادن اطلاعات پیدا می کند (به شکل زیر نگاه کنید محدوده کار ما) نتایج نشان می دهد که این الگوریتم پیشنهادی، CFSP-Miner، Runtimes کارآمد تر از الگوریتم های یافتن الگوهای مشابه است که به طور مداوم در حال پیشرفت است، به جز زمانی که تعداد الگوهای مشابه مکرر و الگوهای شبیه بسته های مکرر تقریبا برابر است. از دیدگاه مقیاس پذیری، الگوریتم CFSP-Miner همچنین الگوهای شبیه نمونه های مکرر بسته را در یک زمان قابل قبول، بدون در نظر گرفتن اندازه، می یابد.
طرح کلی این مقاله به شرح زیر است: در بخش 2 کار مربوطه بررسی شده است. بخش 3 مفاهیم پایه را فراهم می کند. در بخش 4 مفاهیم متعددی معرفی و تعریف شده اند که نتیجه آن ترکیب مفهوم الگوی مشابه بسته و مفاهیم الگوی بسته است. در بخش 5 یک الگوریتم جدید برای یافتن الگوهای مشابه مکرر بسته پیشنهاد شده است. بخش 6 نتایج تجربی و بحث را ارائه می دهد و در نهایت در بخش 7 برخی نتایج و کارهای آینده مورد بحث قرار می گیرد.
2. کارهای مرتبط
این مسئله استخراج الگوی مکرر موجب توجه جامعه پژوهشی داده کاوی به دلیل کاربرد بالقوه آن در بسیاری از حوزه های مختلف شده است. یک خط تحقیق بر کشف الگوهای مکرر در داده های مخلوط (مجموعه داده هایی که اشیاء آنها با ویژگی های عددی و غیر عددی توصیف می شوند) با استفاده از توابع شباهت برای مقایسه و شمارش اشیاء متمرکز است (الگوهای مکرر مشابه) (Danger et al.، 2004؛ Rodríguez González et al .، 2008؛ 2013). یک خط تحقیق دیگر متکی بر به دست آوردن یک مجموعه کاهش یافته از تمام الگوهای مکرر در مجموعه داده های بولی بدون از دست دادن اطلاعات است (مجموعه های مکرر بسته) (Prabha et al.، 2013؛ Uno et al.، 2003؛ Zaki & Hsiao، 2002).
نتایج این خطوط تحقیق مربوط به کار فعلی در زیر بخش های زیر ارائه شده است.
2.1 استخراج الگوی مشابه مکرر
در پیشینه دو الگوریتم برای استخراج ذکر شده وجود دارد: ObjectMiner (Danger et al.، 2004) و STreeDCMiner (Rodríguez-González et al.، 2013). هر دو الگوریتم کل مجموعه ای از الگوهای مشابه مکرر را با استفاده از توابع شباهت بولین پیدا می کنند. مجموعه ای از الگوهای ردیابی معمولا شامل الگوهای پنهان به رویکرد سنتی است.
Abstract
Frequent pattern mining is considered a key task to discover useful information. Despite the quality of solutions given by frequent pattern mining algorithms, most of them face the challenge of how to reduce the number of frequent patterns without information loss. Frequent itemset mining addresses this problem by discovering a reduced set of frequent itemsets, named closed frequent itemsets, from which the entire frequent pattern set can be recovered. However, for frequent similar pattern mining, where the number of patterns is even larger than for Frequent itemset mining, this problem has not been addressed yet. In this paper, we introduce the concept of closed frequent similar pattern mining to discover a reduced set of frequent similar patterns without information loss. Additionally, a novel closed frequent similar pattern mining algorithm, named CFSP-Miner, is proposed. The algorithm discovers frequent patterns by traversing a tree that contains all the closed frequent similar patterns. To do this efficiently, several lemmas to prune the search space are introduced and proven. The results show that CFSP-Miner is more efficient than the state-of-the-art frequent similar pattern mining algorithms, except in cases where the number of frequent similar patterns and closed frequent similar patterns are almost equal. However, CFSP-Miner is able to find the closed similar patterns, yielding a reduced size of the discovered frequent similar pattern set without information loss. Also, CFSP-Miner shows good scalability while maintaining an acceptable runtime performance.
1. Introduction
Frequent pattern mining (Agrawal, Imielinski, ´ & Swami, 1993; Agrawal, Srikant et al., 1994) is a technique that consists of finding patterns (i.e., feature sets with their corresponding values) that frequently occur (more than or equal to a minimum frequency threshold) in a dataset. It is considered a key task in data mining because of its application to discover useful information, such as risk factors (Li, Fu, & Fahey, 2009; Li et al., 2005; Nahar, Imam, Tickle, & Chen, 2013), user’s profiles (Chiu, Yeh, & Lee, 2013), human behavior (Wen, Zhong, & Wang, 2015), malicious software (Fan, Ye, & Chen, 2016) among others. In addition, Frequent pattern mining can be used as a previous or internal step for other data mining tasks, like association rule mining (Alatas, Akin, & Karci, 2008; Kalpana & Nadarajan, 2008; Lopez, Blanco, Garcia, Cano,& Marin, 2008), classification(Hernández-León, Carrasco-Ochoa, Martínez-Trinidad, & Hernández-Palancar, 2012; Nguyen & Nguyen, 2015) and clustering (Beil, Ester, & Xu, 2002).
Since 1990, most of the frequent pattern mining algorithms were based on the exact matching of boolean features to compare and count patterns. This subclass of frequent pattern mining algorithms was called frequent itemset mining (considered as the traditional approach for frequent pattern mining). However, real life objects, such as objects in sociology (Ruiz-Shulcloper & FuentesRodríguez, 1981), geology (Gómez-Herrera, Rodríguez-Morn, Valladares-Amaro et al., 1994), medicine (Ortiz-Posadas, VegaAlvarado, & Toni, 2009) or information retrieval (BaezaYates, Ribeiro-Neto et al., 1999)), are rarely equal or they can be described by non boolean features. Thus, similarity functions different from the exact matching were proposed to compare object descriptions giving rise to a new approach named frequent similar pattern mining which can handle datasets containing non boolean features by using similarity functions (Danger, Ruiz-Shulcloper, & Llavori, 2004; Rodríguez-González, Martínez-Trinidad, Carrasco-Ochoa, & Ruiz-Shulcloper, 2008; 2011; 2013). This approach produces patterns which can not be found by those algorithms based on exact matching. The frequent patterns found using a similarity function are named frequent similar patterns (Rodríguez-González, MartínezTrinidad, Carrasco-Ochoa, & Ruiz-Shulcloper, 2013).
Despite the quality of solutions given by a frequent itemset mining algorithm or a frequent similar pattern algorithm, a critical drawback to both these approaches is that, although a complete set of frequent itemsets or frequent similar patterns can be found, the number of frequent patterns is often too big (Burdick, Calimlim, & Gehrke, 2001; Hu, Sung, Xiong, & Fu, 2008; Pei, Han, Mao et al., 2000; Rodríguez-González et al., 2013; Zaki & Hsiao, 2002).
It is helpful, therefore, to obtain a reduced set of all the frequent patterns without information loss (i.e., from which the entire frequent pattern set can be recovered). One way to do that, is through the use of closed frequent itemsets mining (Prabha, Shanmugapriya, & Duraiswamy, 2013). Closed frequent itemsets mining algorithms define that a frequent itemset is closed if it has no super-patterns with the same frequency, and use this definition to find the closed frequent itemsets. From such closed itemsets, the complete set of frequent itemsets can be generated without information loss. The so-called closed frequent itemsets mining algorithms also have more efficient runtimes than frequent itemset mining algorithms (Pei et al., 2000; Uno, Asai, Uchida, & Arimura, 2003; Zaki & Hsiao, 2002).
However, the concept of a closed patterns has not been exploited for the frequent similar patterns to the best of our knowledge. In this paper, we introduce the concept of a closed frequent similar pattern and a novel closed frequent similar pattern mining algorithm, named CFSP-Miner, that finds a reduced closed set of frequent similar patterns without information loss (see Fig. 1 to see the scope of our work). The results show that this proposed algorithm, CFSP-Miner, has more efficient runtimes than the state-of-the-art frequent similar pattern mining algorithms, except when the number of frequent similar patterns and the closed frequent similar patterns are almost equal. From the scalability point of view, the CFSP-Miner algorithm also finds the closed frequent similar patterns in an acceptable runtime, regardless of size.
The outline of this paper is as follows. In Section 2 related work is reviewed. Section 3 provides basic concepts. In Section 4 several concepts are introduced and redefined as a result of combining frequent similar pattern and closed pattern concepts. In Section 5 a novel algorithm for mining closed frequent similar patterns is proposed. Section 6 presents the experimental results and discussion, and finally, in Section 7 some conclusions and future work are discussed.
2. Related work
The frequent pattern mining problem has attracted the attention of the data mining research community because of its potential application in many different domains. One research line focuses on discovering frequent patterns in mixed data (datasets whose objects are described by numerical and non-numerical features) using similarity functions to compare and count objects (frequent similar patterns) (Danger et al., 2004; RodríguezGonzález et al., 2008; 2013). Another research line focuses on obtaining a reduced set of all the frequent patterns in boolean datasets without information loss (closed frequent itemsets) (Prabha et al., 2013; Uno et al., 2003; Zaki & Hsiao, 2002).
The results of these research lines related to the current work are presented in the following subsections.
2.1. Frequent similar pattern mining
In the literature there are two algorithms for mining frequent similar patterns: ObjectMiner (Danger et al., 2004) and STreeDCMiner (Rodríguez-González et al., 2013). Both algorithms find the whole set of frequent similar patterns by using boolean similarity functions. The discovered set of patterns usually contains patterns hidden to the traditional approach.
چکیده
1. مقدمه
2. کارهای مرتبط
2.1 استخراج الگوی مشابه مکرر
2.2 استخراج آیتم های مکرر بسته
3. مفاهیم و عبارات پایه
4. ترکیب مفهوم الگوی مشابه مکرر و الگوی مشابه مکرر بسته
5. الگوریتم الگوریتم مشابه الگوریتم مشابه (CFSP-Miner)
5.1. تجزیه و تحلیل پیچیدگی
6. نتایج تجربی
6.1. کارایی الگوریتم CFSP-Miner
6.2. مقیاس پذیری الگوریتم CFSP-Miner
7. نتیجه گیری
منابع
ABSTRACT
1. Introduction
2. Related work
2.1. Frequent similar pattern mining
2.2. Closed frequent itemset mining
3. Basic concepts and notations
4. Combining frequent similar pattern and closed frequent similar pattern concepts
5. Closed frequent similar pattern algorithm (CFSP-Miner)
5.1. Complexity analysis
6. Experimental results
6.1. Efficiency of CFSP-Miner algorithm
6.2. Scalability of CFSP-Miner algorithm
7. Conclusions
References