
دانلود رایگان مقاله یک روش مبتنی بر خوشه بندی برای بهبود کارایی در سیستم های توصیه گر
چکیده
در سیستم های توصیه گر مشارکت محور، محصولات به عنوان ویژگی شناخته میشوند و از کاربران درخواست میگردد تا به محصولات خریداری شده، رأی دهند. با آموختن رتبهبندی ارائه شده توسط کاربران، سیستم توصیه گر میتواند محصولات جالبی را به کاربران توصیه نماید. با این حال، معمولاً محصولات بسیار زیادی در تجارت الکترونیک وجود دارد و ممکن است این راهکار چندان کارآمد نباشد، به خصوص در زمانهایی که لازم است هر محصول قبل از ساخت در سیستم توصیه گر قرار گیرد. ما یک روش جدید را پیشنهاد میکنیم که یک الگوریتم خوشهبندی خودکار را برای کاهش ابعاد مرتبط با تعداد محصولات در بردارد. محصولات مشابه در خوشهای یکسان قرار میگیرند و محصولات نامشابه، در خوشههای متفاوتی قرار میگیرند. کارهای پیشنهادی سپس با نتیجه خوشهبندی انجام میگیرد. در نهایت، انتقال مجدد انجامشده و لیست مرتب شده از محصولات پیشنهادی به هر کاربر پیشنهاد میگردد. با روش پیشنهادی، زمان پردازش برای تهیه پیشنهاد کاهش مییابد. نتایج آزمایشها، نشان میدهد که کارایی سیستم های پیشنهادی میتواند، بدون به خطر انداختن کیفیت توصیهها بهبود یابد.
1. مقدمه
با توجه به توسعه سریع تجارت الکترونیکی، امروزه تعداد زیادی خریدار و فروشنده آنلاین وجود دارد و مقدار زیادی محصولات وجود دارد که کاربران میتوانند برای خرید انتخاب کنند. به هر حال، وظیفه بررسی و انتخاب محصولات مناسب از جمله تعداد زیادی از محصولات، نه تنها گیجکننده، بلکه وقتگیر است. سیستم های توصیه گر [1،2] برای کمک به مردم در یافتن محصولات جالبتوجه و ذخیره زمان جستجوی محصولات کمک میکنند. برای یک کاربر، چنین سیستمی میتواند از تجربیات ذخیرهشده برای تمام مشتریها و توصیههای یک لیست اولویت از محصولات به کاربران استفاده کنند. در طول چند سال گذشته، سیستم های پیشنهاددهنده به صرعت در حال تحول هستند. بسیاری از سیستم های توصیه گر توسعه یافتهاند.
در اصل میتوان آنها را در دو دسته طبقهبندی کرد: محتوا محور و مشارکت محور. اگر چه گرایش به سمت سیستم های ترکیبی [3] در سالهای اخیر افزایش یافته است. سیستم توصیه گر مبتنی بر محتوا [4] به کاربر بر اساس محتوایی که ممکن است شامل دستهها و یا ویژگیهای دیگر محصولات باشد، پیشنهاد میدهد. همچنین ممکن است به عادات، منافع و یا تنظیمات کاربران مراجعه کند. با تجزیه و تحلیل این دادهها با برخی از فناوریها از جمله مدلسازی بیزین [8،9]، محتوای مبتنی بر سیستم پیشنهاددهنده جذاب تر خواهد بود. به طور کلی، سیستم های مبتنی بر محتوا نیاز به اطلاعات دقیق در مورد محصولات و کاربران ندارند. محصولات جدید را نیز میتوانند به کاربران توصیه نمایند. با این حال، رسیدن به اطلاعات مورد نیاز سخت و یا زیاد است. محصولات یا کاربران دارای ویژگیهای خود هستند. مشکل جمعآوری ویژگیها از تمام محصولات و کاربران در هر صورت وجود دارد. علاوه بر این، اطمینان از اینکه یک محصول یا یک کاربر، را میتوان با دادههای جمعآوری شده نمایش داد، مشکل است. یک سیستم توصیه گر مشارکت محور، نیازی به جزئیات اطلاعات درباره ویژگیهای محصولات یا کاربران ندارد. به جای آن، آن با اجرای تعاملات بین اطلاعات کاربران و محصولات توصیه میکند. همواره، اطلاعات تعامل به عنوان رتبهبندی کاربر برای محصولات خریداری شده بیان میشود. با یادگیری این رتبهبندی، چنین سیستم پیشنهاددهندهای، میتواند محصولات را بر اساس نظرات ثبتشده سایر کاربران و ترجیحات خود کاربر مدنظر انجام دهد. به طور کلی، سیستم های توصیه گر مشارکت محور، ساده و موثر هستند و در جامعه تجارت، جذاب تر و عملی تر هستند.
معمولاً محصولات بسیار زیادی برای بررسی در سیستم های توصیه گر وجود دارند و این امر میتواند بسیار ناکارآمد باشد، اگر هر محصول نیاز داشته باشد قبل از دریافت توصیه بررسی گردد. روش کاهش ابعاد برای تولید سریع توصیه باکیفیت بالا و مجموعههایی با مقیاس بزرگ استفاده میگردد. در [26]، یک روش K-means به نام الگوریتم خوشهبندی K-means برای گروهبندی کاربران درون گروههای متفاوت ارائه شده است. همسایگان هر کاربر به دنبال تقسیم بندی کاربران، برای دریافت توصیه از سیستم توصیه گر از نتایج سایر کاربران هم گروه با خود بهره میگیرند. ژو و همکارانش [27] یک رویکرد مبتنی بر Smooth ارائه کردند که از خوشههای تولید شده از دادههای آموزشی برای تهیه خوشهها و همسایگان هر خوشه بهره میگیرد. Honda و همکارانش [28]، یک روش خوشهبندی برای انتخاب همسایگان بر اساس یک نظریه تعادل ساختاری ارائه کردند. کاربران و محصولات بر اساس متعادل کردن گراف ترکیبی، به خوشههایی تقسیم میشوند.
Be و همکارانش [29]، کاربران را در خوشههایی مطابق با صفات آنان خوشهبندی کردند، به عنوان مثال، بر اساس جنسیت، سن و شغل. سپس ماتریس امتیاز کاربر به هر کالا را تجزیه و تحلیل کرده و شباهت کاربران به یکدیگر را محاسبه کردند. سیستم iExpand [30]، مشارکت محور بودن سیستم های توصیه گر را توسط علایق کاربران و رتبهبندی شخصی هر کاربر انجام داد. معرفی یک طرح سه لایهای، برای کمک به فهم تعاملات بین کاربران، محصولات و کاربران توسط آنان انجام شد. LDA، برای تقسیمبندی محصولات به خوشههایی ارائه گردید. در [31]، خوشهبندی فازی در کاربران، به تشکیل گروههای کاربران منجر شد. یک بردار خصوصیت گروهی برای هر کاربر ساخته میشود. هر بردار خصوصیت کاربر را میتوان به عنوان یک بردار نمایشدهنده میزان اهمیت و کارایی محصولات برای آن کاربر در نظر گرفت. Sarwat و همکارانش [32]، سیستم توصیه گری را پیشنهاد دادند که از یک طبقهبندی کننده با سه نوع نرخ مبتنی بر مکان استفاده میکند. در PRM2 [33]، منابع شخصی، شباهت علایق فردی و نفوذ فردی تجمیع شده و توسط روش SVD، کاهش بعد یافته و مورد استفاده قرار میگیرند. BiFu [34] یک مفهوم از محصولات محبوب را شناسایی کرده و برای توصیه در اختیار سیستم های توصیه گر قرارداد.
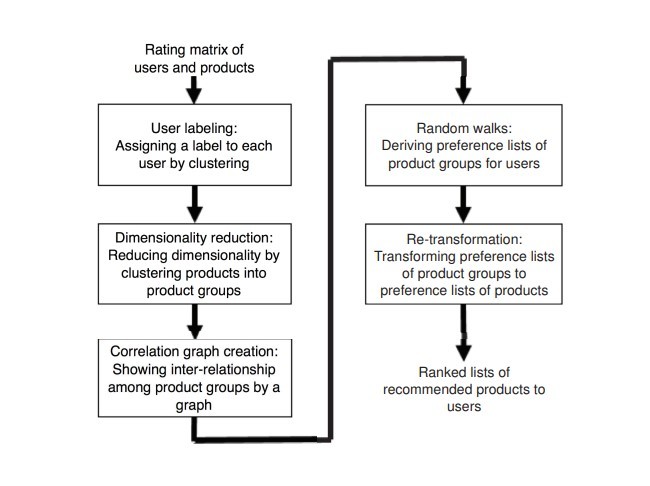
برای کاهش ابعاد ماتریس رتبهبندی، K-means [35] برای گروهبندی کاربران و محصولات درون خوشههایی استفاده شده است. همچنین از روش smoothing and fusion برای غلبه بر پراکندگی دادهها و تنوع امتیاز استفاده میگردد. ICRRS [36]، یک الگوریتم تکراری است که نه تنها مبتنی بر ارزیابی، بلکه مبتنی بر مقایسه و تقریب زنی است. سیستم های توصیه گر مبتنی بر کاهش ابعاد ذکر شده در بالا، دارای برخی معایب هستند. برخی از سیستم ها [29، 32]، نیاز به ویژگیهای اضافی دیگری در مورد کاربران و یا محصولات دارند. این ویژگیها معمولاً برای دستیابی به کاربرد عملی ضروری است. به عنوان مثال، [26]، [27] و ][31]، نیاز به خوشههای بیشتری برای پیشبرد هدف دارند. همچنین شباهت اندازهگیری شده، اکثراً برای سیستم های اتخاذ شده در زمینه کاهش ابعاد مورد استفاده قرار میگیرد. نادیده گرفتن واریانس خوشهبندی، ممکن است منجر به نتایج نادرستی گردد. در این مقاله، یک رویکرد مبتنی بر خوشهبندی خودساخته برای اعمال پیشنهاد با هدف کاهش ابعاد مرتبط با تعداد محصولات ارائه شده است. محصولات مشابه در هر خوشهبندی، برای انجام توصیه در همان خوشه مورد استفاده قرار میگیرند. نمودار همبستگی نشان میدهد که ارتباط متقابل میان گروه محصولات ایجادشده ضروری و مهم است. الگوریتم random walk، اجراشده و لیست اولویتهای محصولات، گروهبندی شده و مورد استفاده قرار میگرند. پس از آن، لیست اولویت، مجدداً به لیست اولویتهای فردی از محصولات تبدیل میگردد. در نهایت، با روش پیشنهادی، خوشهبندی کاملا بر اساس ماتریس اولویت دهی بدون نیاز به جمعآوری صفات اضافی درباره محصولات و کاربران انجام میگیرد. خوشهها به صورت خودکار تولید شده و یک تعداد خوشه از پیش تعیین شده توسط کاربر ایجاد میگردد. علاوه بر این، در هنگام نیاز به اندازهگیری شباهت برای خوشهبندی، ما از واریانس مراکز خوشهها استفاده میکنیم. با توجه به گاهش ابعاد در تعداد محصولات، زمان پردازش برای ساخت توصیه توسط رویکرد ما بسیار کاهش مییابد. نتایج تجربی نشان میدهد که بهره وری سیستم پیشنهادی را میتوان بدون کاهش کیفیت، تا حد زیادی بالا برد. ادامه مقاله به شرح زیر سازماندهی شده است. مسئلهای که باید حل شود، در بخش 2 نشان داده شده است. یک سیستم توصیه گر مشارکت محور، ItemRank [17]، در بخش 3 معرفی شده است. روش پیشنهادی ما برای بهبود کارایی ItemRank، با جزئیات در بخش 4 ارائه شده است. یک مثال در بخش 5 نشان داده شده است. نتایج آزمایشها در بخش 6 نمایش داده شده است. در نهایت، بخش پایانی، نتیجهگیری را نشان میدهد.
2. بیان مسئله
فرض کنید یک مجموعه از N کاربر به صورت 1<i<N وجود دارد و یک مجموعه از M محصول pj، 1<j<M وجود دارد. یک کاربر ui، ارزیابی خود از محصولات pj را با تهیه یک نرخ rij نمایش میدهد. همواره، یک مقدار بزرگتر برای نمایش یک بازخورد از کاربر شروری است. اگر کاربر ui، اولویت و یا امتیازی را برای محصول pj وارد نکند، rij=0. چنین اطلاعاتی را میتوان توسط ماتریس R زیر نمایش داد.
3. ItemRank
ItemRank [17] یکی از روشهای اساسی برای مشارکت بودن سیستم های توصیه گر است. آن ِک الگوریتم امتیازدهی مبتنی بر random-walk، برای پیشنهاد محصولات مطابق با اولویت کاربر استفاده میکند. ItemRank در مطالعات ما استفاده شده است، زیرا دارای پیچیدگی کمتر و کارایی بالاتر در مصرف پول و هزینه محاسباتی نسبت به سایر سیستمها است . ماتریس اولویت نمایش داده شده در رابطه (1)، دارای فرآیند ItemRank با دو گام است، ایجاد گراف همبستگی و random walk [38]. در گام ایجاد گراف همبستگی، یک گراف همبستگی ساخته میشود. هر محصولی به عنوان یک محصول در داخل گراف است و یک گراف همبستگی از اولویتهای داده شده ساخته میشود. هر محصولی، به عنوان یک نود در گراف است. یال بین هر دو نود، pi و pj، دارای وزن wij است که نشانگر تعداد کاربرانی است که به هر دو محصول، امتیاز یکسانی داده بودند. توجه داشته باشند یک کاربر uk، اولویت هر دو محصول را تعیین میکند.
Abstract
In collaborative filtering recommender systems, products are regarded as features and users are requested to provide ratings to the products they have purchased. By learning from the ratings, such a recommender system can recommend interesting products to users. However, there are usually quite a lot of products involved in E-commerce and it would be very inefficient if every product needs to be considered before making recommendations. We propose a novel approach which applies a self-constructing clustering algorithm to reduce the dimensionality related to the number of products. Similar products are grouped in the same cluster and dissimilar products are dispatched in different clusters. Recommendation work is then done with the resulting clusters. Finally, re-transformation is performed and a ranked list of recommended products is offered to each user. With the proposed approach, the processing time for making recommendations is much reduced. Experimental results show that the efficiency of the recommender system can be greatly improved without compromising the recommendation quality.
1. Introduction
Due to the fast development of E-commerce, nowadays there are a large number of on-line shoppers and a huge amount of products from which people can choose online. However, the task of examining and choosing appropriate products from such a large number of products can be not only confusing but also time-consuming. Recommender systems [1, 2] have thus been developed to help people find the products they are interested in and save their time in the search process. For a user, such systems can learn from the recorded experience of all the customers and recommend a preference list of products to the user. During the past several years, recommender systems have been evolving rapidly. Many recommender systems have been developed. In essence, they can be classified into two categories, content-based and collaborative filtering, although a tendency toward hybrid systems [3] has been growing in recent years.
A content-based recommender system [4, 5, 6, 7] makes recommendations to a user based on the content which may include the categories or other attributes of the prod ucts. It may also refer to the habits, interests, or preferences of the users. By analyzing these data with some technologies such as Bayesian modeling [8, 9], a content-based recommender system recommends to the user those products that are most appealing. In general, content-based systems require detailed information about products and users. New products can be recommended to the users. However, the informa tion needed is either enormous or hard to get. The products or users have their own attributes. It’s difficult to collect the attributes of all the products and users. Furthermore, making sure a product or a user is uniquely represented by the collected attributes is also hard.
A collaborative filtering recommender system [10, 11, 12, 13, 14, 15, 16, 17, 18, 25 19, 20, 21, 22, 23, 24, 25], on the other hand, does not require detailed information about the attributes of the products or the users. Instead, it makes recommendations by applying the interaction information between users and products. Usually, the interaction information is expressed as the user ratings for the purchased products. By learning from the ratings, such a recommender system can recommend a product to a user based on the opinions of other like-minded users on that product. In general,collaborative filtering recommender systems are simpler and more implementable, and tend to be more appealing and practical in the E-commerce community.
There are usually quite a lot of products to be considered in a recommender system. It would be very inefficient if every product needs to be considered before making recommendations. Dimensionality reduction techniques have been incorporated to produce quickly quality recommendations for large-scale problems. In [26], a variant of K-means called the bisecting K-means clustering algorithm is adopted to group the involved users into different partitions. The neighborhood of a given user is selected by looking into the partition to which the user belongs, and is used for making recommendations to the user. Xue et al. [27] present a smoothing-based approach which employs clusters generated from the training data to provide the basis for data smoothing and neighborhood selection. Honda et al. [28] apply a clustering method for selecting neighbors based on a structural balance theory. Users and products are partitioned into clusters by balancing a general signed graph composed of alternative evaluations on products and users. Ba et al. [29] group the users into clusters according to the attributes, e.g., gender, age, and occupation. Then the user-product rating matrix is decomposed and recombined into a new rating matrix to calculate the similarity between any two users. The iExpand system [30] enhances collaborative filtering by user interest expansion via personalized ranking. It introduces a three-layer representation scheme to help the understanding of the interactions among users, products, and user interests. Latent Dirichlet allocation (LDA) is applied to partition the involved products into clusters. In [31], fuzzy clustering is conducted on users to form user groups. A user group typicality vector is thus constructed for each user. Representing a user by a user group typicality vector instead of product vector can be regarded as a dimension reduction on user representation. Sarwat et al. [32] produce recommendations using a taxonomy of three types of location-based ratings within a single framework. User partitioning and travel penalty are exploited to favor recommendation candidates closer to querying users. In PRM2 [33], personal interest, interpersonal interest similarity, and interpersonal influence are fused into a unified personalized recommendation model, and singular value decomposition (SVD) is used to produce a low-dimensional representation of the original user-product space. BiFu [34] introduces the concepts of popular products and frequent raters to identify the rating sources for recommendation. To reduce the dimensionality of the rating matrix, K-means [35] is applied to group the users and products into clusters. It also employs the smoothing and fusion technique to overcome the data sparsity and rating diversity. ICRRS [36] is an iterative rating algorithm which is not based on comparing submitted evaluations to an approximation of the final rating scores, and it entirely decouples credibility assessment of the cast evaluations from the ranking itself.
The dimensionality reduction based recommender systems mentioned above have some disadvantages. Some systems [29, 32] require extra attributes about users or products to group the users into clusters. These attributes are usually hard to get in a practical application. Other systems, e.g., [26], [27], and [31], require the number of clusters be given in advance, which is a big burden on the user. Also, the similarity measure most systems adopted for dimensionality reduction only takes the centers of clusters into account. Ignoring the variances of clusters may lead to imprecise results. In this paper, we propose a clustering based approach which applies a self-constructing clustering algorithm to reduce the dimensionality related to the number of products. Similar products are grouped in the same cluster and dissimilar products are dispatched in different clusters. Recommendation work is then done with the resulting clusters called product groups. A correlation graph which shows the inter-relationship among the product groups is created. A series of random walks are then executed and a preference list of product groups is derived for each user. Subsequently, re-transformation, which transforms preference lists of product groups to preference lists of individual products, is performed, and a ranked list of recommended products is finally offered to each user. With the proposed approach, clustering is done totally based on the userproduct rating matrix without the necessity of collecting extra attributes about customers and products. Clusters are formed automatically and a pre-determined number of clusters provided by the user is not required. Besides, when measuring the similarity for clustering, we consider both the centers and variances of clusters, resulting in a similarity measure better than that proposed in other methods. Due to dimensionality reduction on the number of products, the processing time for making recommendations by our approach is much reduced. Experimental results show that the efficiency of the recommender system can be greatly improved without compromising the recommendation quality.
The rest of this paper is organized as follows. The problem to be solved is stated in Section 2. A collaborative filtering recommender system, ItemRank [17], is introduced in Section 3. Our proposed approach of efficiency improvement to ItemRank is described in detail in Section 4. An example for illustration is given in Section 5. Experimental results are presented in Section 6. Finally, a conclusion is given in Sec100 tion 7.
2. Problem Statement
Suppose there are a set of N users ui , 1 ≤ i ≤ N, and a set of M products pj , 1 ≤ j ≤ M. A user ui may express his/her evaluation to a product pj by providing a rating rij , a positive integer, for pj . Usually, a higher rating is assumed to indicate a more favorable feedback from the user. If user ui has not provided a rating for product pj , rij = 0. Such information can be represented by the following user-product rating matrix R.
3. ItemRank
ItemRank [17] is one of the baseline methods for collaborative filtering recommendation. It applies a random-walk based scoring algorithm to recommend products according to user preferences. ItemRank was chosen in our study since it is less complex, yet performs better, in terms of memory usage and computational cost, than other baseline systems [37]. Given the rating matrix shown in Eq.(1), ItemRank proceeds with two steps, correlation graph creation and random walks [38]. In the correlation graph creation step, a correlation graph is built from the given ratings. Each product is regarded as a node in the graph. The edge between any two nodes, node pi and node pj , 1 ≤ i, j ≤ M, has a weight wij which is the number of users who have provided ratings to both product pi and product pj . Note that a user uk has provided ratings to both products pi and pj if rki > 0 and rkj > 0.
چکیده
1. مقدمه
2. بیان مسئله
3. ItemRank
4. روش پیشنهادی
4.1. خوشهبندی خودساخته (SCC)
4.2. گام 1: برچسبگذاری کاربر
4.3. کاهش ابعاد
4.4. گام 3: ایجاد گراف همبستگی
4.5. گام چهارم: random walk
4.6. گام پنجم: Re-Transmision
4.7. آنالیز پیچیدگی
5. مثال
6. نتایج آزمایشها
6.1. مجموعه داده
6.2. نتایج و بحث
7. نتیجهگیری
منابع
Abstract
1. Introduction
2. Problem Statement
3. ItemRank
4. Proposed Approach
4.1. Self-Constructing Clustering (SCC)
4.2. Step 1: User Labeling
4.3. Step 2: Dimensionality Reduction
4.4. Step 3: Correlation Graph Creation
4.5. Step 4: Random Walks
4.6. Step 5: Re-Transformation
4.7. Complexity Analysis
5. Example
6. Experimental Results
6.1. Data Sets
6.2. Results and Discussion
7. Conclusion
References