
دانلود رایگان مقاله تحمل پذیری خطا در یک سیستم مدیریت توزیع
چکیده
این مطالعه مهمترین مفهوم فراگرفته شده از اجرای یک سیستم مدیریت ارتباط از راه دور توزیعشده را (DTM ها)، که یک سیستم ارتباط صوتی شبکهشده را کنترل میکند بیان میکند. الزامات اساسی مورد نیاز برای DTM ها تحملپذیری خطا در برابر شکستهای سایت یا شبکه، امنیت کاربردی و قابلیت اعتماد ماندگار است. بهمنظور ارائه توزیع و ماندگاری هر دو مفهوم شفافیت و مقاومت در تحملپذیری خطا، معماری دو لایه الگوریتم تکرار را معرفی میکنیم. درمیان مفاهیم فرارگرفته شده: مهندسی نرمافزار براساس مولفهها، با سربار اولیه قابلتوجهی همراه است اما در دراز مدت باارزش است. سرویس تحملپذیری در برابر خطا یکی از نیازهای کلیدی برای توزیع خرابی امن است. دانه دانه شدگی منطقی برای کنترل مقاومت و همزمانی کل شی است. تکرار ناهمزمان در لایه پایگاه داده نسبت به تکرار همزمان در سطح بالاتری از نظر استحکام و قوام قرار دارد؛ مقاومت نیمهساختاریافته با XML دارای اشکالاتی در مقاومت، عملکرد و راحتی؛ در مقابل مدل شی دارد، ساختار سلسله مراتبی قویتر و امکانپذیرتر است. یک موتور پرسوجو به وسیلهای برای انتقال از طریق مدل شی اتلاق میشود؛ در نهایت انتشار عملیات حذف در مدل شیگرایی پیچیدهتر م شود. بنا به مطالب فرا گرفته شده ما قادر به ارائه پلتفرم توزیع دردسترس برای سیستمهای شی مقاوم هستیم.
1. مفاد سیستم
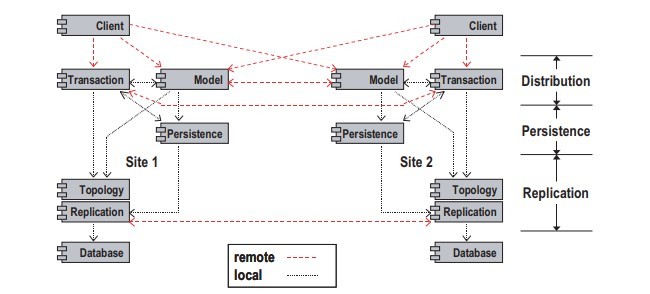
دردسترس بودن بالا نه تنها برای ایمنی بحرانی سیستم ارتباط صوتی شبکه نیاز است (VCS) بلکه برای کنترل سیستمهای مدیریت نیز ضروری است. در این مطالعه، شبکههای VCS توسط یک سیستم مدیریت ارتباط از راه دور توزیعشده (DTM ها) همانند شکل 1 مدیریت میشوند. سرورهای متعدد DTM از طریق یک شبکه گسترده WAN به هم متصل هستند و هر سرور DTM، سیستمهای VCS مرتبط با آن را تنظیم، کنترل و نظارت میکند. هر DTM پارامتر VCS را با استفاده از یک مدل شیگرا نگهداری میکند.
بهطورکلی پیروی از اصول طراحی مهندسی نرمافزار براساس اجزا (CBSE) [6] مانند انسجام دائم اجزاء قوی و استانداردهای با تعامل خوب، شرایط زیر را میطلبد که مربوط به دردسترس بودن است:
تحملپذیری خطا: سیستم در برابر خطاها تحملپذیر است. این کار از طریق تکرار شی در سایتهای دیگر امکانپذیر است.
• همه اشیاء نیاز دارند تا در تمام مواقع حتی در حضور سناریوهای دلخواه سیستم جهت خواندن دردسترس باشند.
• برای دسترسی جهت نوشتن کافی است
اگر اشیاء در تمام سایتها در طول وضعیت سالم سیستم در دسترس هستند.
اگر اشیاء در یک سایت خاص در طول وضعیت تخریب سیستم (که ما سایت را فراخوانی میکنیم) دردسترس هستند.
علاوه براین، خود چارچوب بهطورکامل توزیعشده است. چارچوب منحصربه فرد تک جزء نباید بهمنظور جلوگیری از هرگونه شکستی در سراسر کل سیستم وجود داشته باشد.
تراکنش: اشیاء باید قادر به شرکت در تراکنش باشند. بهطور معمول، نوشتن کوچک و خواندن بزرگ تراکنشها اغلب نیاز به اجرا دارد.
تداوم: دادهی شی مقاوم، باید در منبعی پایدار ذخیره شود.
شفافیت: مشتریان نباید از مسائل توزیعشدگی، تکرار و تداوم آگاه باشند، در نتیجه شفاف برای مشتریان وجود دارد.
در مطالعه ما، هر دو مورد توزیعشدگی و مقاومت یا تداوم، باید شفاف و مقاوم در برابر تحملپذیری خطا باشند، که تحملپذیری خطا توانایی یک سیستم برای ادامه عملکرد در مواقعی است که شکست هنوز ترمیم نشده و یا حتی غیر قابل تشخیص است [7].از آنجا که تحملپذیری خطا نیاز به گنجانده شدن در معماری سیستم دارد، ما شی حفظ شده را، بهمنظور ارائه اطلاعات اضافی برای جایگزینی پویای هر شی شکست خوردهای به دیگر سایتها تکرار میکنیم. در بهترین حالت، برنامه قابل دسترس خواهد بود اگر هر سایتی در دسترس باشد، زیرا درحال حاضر اشیاء را میتوان در هر سایتی ذخیره کرد.
تکرار بهعنوان وسیلهای برای ارائه تحملپذیری خطا مناسب است و مجموعهای از پروتکلهای تکرار وجود دارد. چگونه تا به حال، بهکارگیری تکرار نیازمند مدیریت شی تکرار شده و معرفی نیازمندیهای جدید به شفافیت تکرار بود. علاوه بر این، اگر تداوم و توزیع نرمافزار سیستم در یک سیستم شیگرا متمرکز باشد، مدیریت فیزیکی متعدد به مفاهیم متعارف خود از چنین سیستمی که معمولا برای در یک نسخه واحد طراحی شده است بستگی دارد:
• حفظ ثبات در میان اشیاء منطقی
• دسترسی همزمان به اشیاء منطقی
• دسترسی تراکنشی به اشیاء منطقی
• به دست گیری هویت شی، که در میان اشیاء منطقی منحصر به فرد است
• به دست گیری هویت شی، که در میان اشیاء منطقی منحصر به فرد است
سهم این مطالعه، توصیف منطق اصلی برای تصمیمگیریهای کلیدی و استنتاج کلی است، که از نظر ما، میتوان از تجارب به دست آورد.
مهمترین یافتهها عبارتند از:
• توزیع و تکرار نیاز به نصب معماری دو لایه دارد. به این ترتیب، مکانیسم توزیع معمولی را میتوان بدون تغییر مستقر کرد.
• سرویس نامگذاری خرابی امن یک شرط کلیدی برای توزیع شکست امن است.
• عملکرد موردنیاز برای اطمینان از پیچیدگی سیستم سخت است.
هر دو نویسنده به شدت درگیر طرح توسعه DTMS بودند:
Karl M. Goeschka دانشمند ارشد در Frequentis Nachrichtentechnik GmbH با دفتر مرکزی آن در اتریش و چندین شعبه در کشورهای دیگر (آمریکا، کانادا، آلمان) است. Frequentis رهبر بازار جهان برای ارتباطات صوتی بسیار سریع و دردسترس در کنترل ترافیک هوایی است. همچنین محصولات آن برای امنیت عمومی و ارتباطات امن استفاده میشود. با توجه به شخصیت خلاقانه توسعهی DTMS او همچنین مدیر مسئول این پروژه نیز است.
Robert Smeikal دستیار تحقیق در دانشگاه وین در اتریش است. او در حالحاضر دورهی دکترای خود را میگذارند و درگیر مشاوره در تیم توسعه Frequentis در مسائل عملی و مفهومی مهندسی نرمافزار است.
Abstract
Our case study provides the most important conceptual lessons learned from the implementation of a Distributed Telecommunication Management System (DTMS), which controls a networked voice communication system. Major requirements for the DTMS are fault-tolerance against site or network failures, transactional safety, and reliable persistence. In order to provide distribution and persistence both transparently and fault-tolerant we introduce a two-layer architecture facilitating an asynchronous replication algorithm. Among the lessons learned are: component based software engineering poses a significant initial overhead but is worth it in the long term; a fault-tolerant naming service is a key requirement for fail-safe distribution; the reasonable granularity for persistence and concurrency control is one whole object; asynchronous replication on the database layer is superior to synchronous replication on the instance level in terms of robustness and consistency; semi-structured persistence with XML has drawbacks regarding consistency, performance and convenience; in contrast to an arbitrarily meshed object model, a accentuated hierarchical structure is more robust and feasible; a query engine has to provide a means for navigation through the object model; finally the propagation of deletion operation becomes more complex in an object-oriented model. By incorporating these lessons learned we are well underway to provide a highly available, distributed platform for persistent object systems.
1. System Context
High availability is not only demanded for safety-critical networked voice communication systems (VCS) but also for the management systems controlling them. In our case, these VCS networks are managed by a Distributed Telecommunication Management System (DTMS) as illustrated in figure 1. Multiple DTMS servers are connected via a WAN and every DTMS server configures, controls and monitors its associated VCS systems. Every DTMS stores VCS parameter data using an object-oriented model.
Following the general design principles of Componentbased Software Engineering (CBSE) [6] like strong component coherence and well-defined interaction standards, we consider the following requirements, which are relevant for availability considerations:
Fault-tolerance: The system has to be tolerant against network and site failures. This is achieved through replicating object-states to other sites.
• All objects need to be available for read access at any available site at all times even in presence of arbitrary system degradation scenarios.
• For write access it is sufficient
– if objects are available at all sites during periods of healthy system condition.
– if objects are available at a particular site (which we call their home site) during periods of degraded system condition.
Moreover, the framework itself has to be fully distributed. A single unique framework component must not exist in order to avoid any single point of failure throughout the whole system.
Transaction: The objects shall be able to participate in transactions. Typically, small write and large read transactions need to be performed frequently.
Persistence: The persistent objects’ data shall be written to a stable storage.
Transparency: Clients shall not be aware of distribution, replication and persistence issues, which are therefore transparent to clients.
In our case, both, distribution and persistence, have to be transparent and fault-tolerant, where fault-tolerance is the ability of a system to continue functioning while a failure is still unrepaired or even undetected [7]. Since fault-tolerance needs to be incorporated into the system architecture itself, we replicate the persisted object to other sites, in order to provide enough redundant information to replace any failed object dynamically. In the best case, the application is available if any site is available, because now objects can be restored at every site.
Replication as a means to provide fault-tolerance is well suited and a plethora of replication protocols exist. However, the deployment of replication requires the management of the replicated object data and introduces the new requirement of transparency of the replication. Moreover, if deployed in an object-oriented, persistent and distributed software system, managing multiple physical copies that constitute the state of a single logical copy poses problems on conventional concepts of such systems, which are usually designed to operate on a single copy:
• the preservation of consistency among different logical objects
• the concurrent access to logical objects
• the transactional access to logical objects
• handling of object identities, which are unique among logical objects
The contribution of this case study is to describe the major rationale for the key decisions and to derive general lessons, which we believe can be learned from our experience.
The major findings are:
• Distribution and replication need to be installed as twolayer architecture. This way, conventional distribution mechanisms can be deployed unaltered.
• Fail-safe naming services are a key requirement to failsafe distribution.
• Performance requirements are more difficult to ensure due to the complexity of the systems.
Both authors have been heavily involved in the DTMS development project:
Karl M. Goeschka is Chief Scientist at Frequentis Nachrichtentechnik GmbH with headquarters in Austria and several subsidiaries in other countries (USA, Canada, Germany). Frequentis is world market leader for fast and highly available voice communications in air traffic ontrol. The products are also used for public safety and safe communications. Due to the innovative character of the DTMS development he is also the responsible manager of this project.
Robert Smeikal is a research assistant at the Vienna University of Technology in Austria. He is currently working on his Ph.D. and engaged in consulting the development team at Frequentis concerning practical and conceptual software engineering issues.
چکیده
1. مفاد سیستم
2. معماری DTMS و اجزا آن
3. مطالب فراگرفته شده
4. کارهای آینده
منابع
Abstract
1. System Context
2. DTMS Architecture and Components
3. Lessons learned
4. Future work
References