
دانلود رایگان مقاله چارچوبی برای ارزیابی رفتار کشش سرویس ابری
چکیده
سرویس های ابری پیچیده برای مواجهه با حجم کارها و تغییرات مورد نیاز پویا بر فرآیندهای کنترل مختلف کشش متکی هستند. با این حال، اجرای فرآیند کنترل کشش در یک سرویس ابری به دلیل پیچیدگی ساختار سرویس، راهبردهای استقرار، و پویایی اصولی زیرساخت، از نظر کیفیت یا هزینه همیشه منجر به بهره وری بهینه نمی شود. بنابراین توانایی پیشین در برآورد و ارزیابی رابطه بین رفتار کشش سرویس ابری و فرآیندهای کنترل کشش برای انتخاب زمان اجرای فرآیند های مناسب کنترل کشش حیاتی است. در این مقاله، ADVISE را با چارچوبی برای ارزیابی و برآورد رفتار کشش سرویس ابری ارائه می کنیم. ADVISE ، ساختار سرویس، استقرار، زمان اجرای سرویس، فرآیندهای کنترل و اطلاعات زیرساخت ابری را جمع آوری می کند. بر اساس این اطلاعات، ADVISE از تکنیک های دسته بندی استفاده می کند تا رفتار کشش ابری که با کنترل کشش ایجاد شده را شناسایی کند. آزمایش های ما نشان می دهد که ADVISE می تواند رفتار کشش مورد انتظار بموقع را برای سرویس های مختلف ابری برآورد کند در نتیجه ابزار مفیدی برای کنترل کننده های کشش در بهبود کیفیت تصمیمات زمان اجرای کنترل کشش می شود.
1. مقدمه
یکی از ویژگی های کلیدی که باعث محبوبیت رایانش ابری می شود کشش است که در پاسخ به زمان اجرای نوسان حجم کارها، توانایی سرویس های ابری برای به دست آوردن و راه اندازی منابع بنا به تقاضا است. از دیدگاه مشتری، منابع با مقیاس بندی خودکار ابری می توانند زمان اجرای کار را به حداقل برسانند، بدون اینکه از بودجه اختصاص یافته بیشتر شود. از دیدگاه ارائه دهندگان ابری، تامین کشش کمک می کند تا بهره وری مالی آنها به حداکثر برسد هنگامیکه مشتریان خود را راضی نگه می دارند و هزینه های اجرایی را کاهش می دهند. با این حال، تأمین خودکار کشش یک کار ساده و جزیی نیست.
هنگامی که یک آستانه متریک دچار اختلال می شود رویکرد معمول که توسط بسیاری از کنترل کننده های کشش استفاده می شود (1، 2) برای نظارت سرویس ابری و تامین نمونه های مجازی است. این رویکرد ممکن است برای مدل های ساده سرویس کافی باشد، اما با در نظرگیری سرویس های ابری توزیع شده با مقیاس بزرگ با وابستگی های متقابل مختلف، درک عمیق تر از رفتار کشش ضروری می شود. به همین دلیل، کار موجود [2، 3] تعدادی از فرآیندهای کنترل کشش را برای بهبود عملکرد و کیفیت سرویس ابری شناسایی کرده است، حال آنکه به طور اضافی تلاش در کاهش هزینه می کند. با این حال هنوز یک سوال مهم بدون پاسخ باقی مانده است: مناسب ترین فرآیند کنترل کشش برای یک سرویس ابری در زمان اجرای یک وضعیت خاص کدام است؟ هم مشتریان و هم ارائه دهندگان ابری می توانند از اطلاعات روشنی بهره ببرند مانند اینکه چگونه اضافه کردن نمونه جدید به یک سرویس ابری بر حاصل کار استقرار کل و بر هر بخشی از سرویس ابری بصورت جداگانه تاثیر خواهد گذاشت. بدین ترتیب، آگاهی از رفتار کشش سرویس ابری تحت کنترل و حجم کارهای مختلف، برای کنترل کننده های کشش در بهبود تصمیم گیری زمان اجرا بسیار مهم است.
برای این منظورطیف گسترده ای از رویکردها متکی هستند بر نمایه سازی سرویس و یا یادگیری از اطلاعات گذشته [3-5] که پیشنهاد شده است. با این حال، این رویکردها تصمیمات خود را فقط برای ارزیابی متریک های سطح پایین VM (به عنوان مثال استفاده از CPU و حافظه) محدود می کنند و از تصمیمات کشش مبتنی بر رفتار سرویس ابری در چندین سطح پشتیبانی نمی کنند (به عنوان مثال، در هر گره، لایه، کل سرویس). علاوه بر این، رویکردهای کنونی فقط بکارگیری از منابع را بدون در نظر گرفتن کشش به عنوان یک ویژگی چند بعدی متشکل از سه بعد (هزینه، کیفیت، و کشش منابع) ارزیابی می کنند. در نهایت رویکردهای موجود، نتیجه فرایند کنترل بر سرویس کلی را در نظر نمی گیرند جاییکه اجرای یک فرآیند کنترل در بخش اشتباه سرویس ابری می تواند منجر به اثرات جانبی مانند افزایش هزینه یا کاهش عملکرد سرویس کل شود. در کار قبلی که انجام دادیم، با مفاهیم فضا و مسیر کشش (6) بر رفتار پیشین و کنونی مدلسازی یا استفاده از الگوریتم های مختلف برای تعیین زمان اجرا در رفتار مشاهده شده تمرکز کردیم اما بدون اینکه رفتار مورد انتظار از بخش های مختلف سرویس را مدلسازی کنیم (به عنوان مثال با تعیین نقطه تغییر).
در این مقاله بر عنوان کردن محدودیت های فراتر از چارچوب ADVISE ( ارزیابی رفتار کشش سرویس ابری) تمرکز می کنیم که رفتار کشش سرویس ابری را با استفاده از انواع مختلف اطلاعات مانند ساختار سرویس، راهبرد های استقرار و زیرساخت های اصولی پویا در هنگام استفاده از محرک های مختلف خارجی برآورد می کند (به عنوان مثال، فرایندهای کنترل کشش). در هسته ADVISE یک فرآیند ارزیابی مبتنی بر دسته بندی است که از این نوع اطلاعات برای محاسبه رفتار کشش مورد انتظار در بخش های مختلف سرویس استفاده می کند. برای ارزیابی اثربخشی ADVISE، آزمایش ها بر یک بستر ابری عمومی با یک تست بد testbed متشکل از دو سرویس ابری متفاوت انجام گرفت. نتایج نشان می دهد که ADVISE رفتار کشش مورد انتظار را برای سرویس های مختلف با برآورد میزان خطای کم حاصل می¬کند. ADVISE همراه با کنترل کننده های کشش خود می تواند با ارائه دهندگان ابری یکی شود تا کیفیت تصمیم خود را بهبود بخشد و یا توسط ارائه دهندگان سرویس ابری استفاده شود تا ارزیابی و درک کند چگونه فرآیندهای مختلف کنترل کشش بر سرویس خود تاثیر قرار می گذارند.
بقیه این مقاله به شرح زیر است: در بخش 2 اطلاعات مربوط به سرویس ابری ارائه می شود. در بخش 3 فرایند ارزیابی رفتار کشش را ارائه می کنیم. در بخش 4 اثربخشی چارچوب ADVISE را ارزیابی می کنیم. در بخش 5 درباره کار مرتبط صحبت می کنیم. بخش 6 این مقاله را به پایان می رساند.
2. ساختار سرویس ابری و اطلاعات زمان اجرا
2.1 اطلاعات سرویس ابری
در این مطالعه دنباله شرح سرویس موجود [7] در برنامه ابری را بگونه سرویس ابری اشاره می کنیم. یک سرویس ابری را می توان به توپولوژی های سرویس تقسیم کرد (مثلا رشته ایی از تجارت یا بخشی از یک جریان کاری) که گروهی از واحدهای خدماتی بصورت لغوی مربوط به هم را نشان می دهد. یک واحد خدماتی (به عنوان مثال سرویس وب) یک ماژول با ارائه قابلیت محاسبات یا داده را نشان می دهد. به منظور اینکه به این ساختارهای سرویس ابری در سطح جهانی اشاره کنیم از اصطلاح بخش های سرویس (SP) استفاده می کنیم.
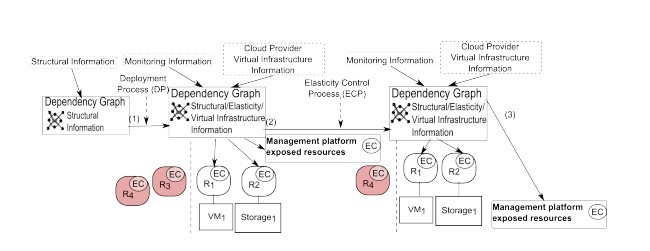
مدل سرویس ابری مفهومی که در [8] ارائه شده را با مجموعه غنی از انواع اطلاعات برای تعیین رفتار کشش ابری گسترش می دهیم. شکل 1، گسترش های ما را (پس زمینه سفید) در شامل کردن فرآیندهای کنترل کشش، رفتارهای بخش سرویس، و بخش های سرویس نشان می دهد. به طور کلی، این نمایه شامل این موارد است (i) اطلاعات ساختاری در توصیف ساختار معماری برنامه ای که در ابر اجرا می شود، (ii) اطلاعات سیستم زیرساختی که اطلاعات زمان اجرا در مورد منابع اختصاص یافته از بستر اصولی به سیستم ابری را توصیف می کند، و (iii) اطلاعات کشش، که برای توصیف متریک ها، الزامات، و قابلیت های کشش، هم با اطلاعات سیستم ساختاری و هم غیرساختاری مرتبط است.
Abstract
Complex cloud services rely on different elasticity control processes to deal with dynamic requirement changes and workloads. However, enforcing an elasticity control process to a cloud service does not always lead to an optimal gain in terms of quality or cost, due to the complexity of service structures, deployment strategies, and underlying infrastructure dynamics. Therefore, being able, a priori, to estimate and evaluate the relation between cloud service elasticity behavior and elasticity control processes is crucial for runtime choices of appropriate elasticity control processes. In this paper we present ADVISE, a framework for estimating and evaluating cloud service elasticity behavior. ADVISE gathers service structure, deployment, service runtime, control processes, and cloud infrastructure information. Based on this information, ADVISE utilizes clustering techniques to identify cloud elasticity behavior produced by elasticity control. Our experiments show that ADVISE can estimate the expected elasticity behavior, in time, for different cloud services thus being a useful tool to elasticity controllers for improving the quality of runtime elasticity control decisions.
1 Introduction
One of the key features driving the popularity of cloud computing is elasticity, that is, the ability of cloud services to acquire and release resources ondemand, in response to runtime fluctuating workloads. From customer perspective, resource auto-scaling could minimize task execution time, without exceeding a given budget. From cloud provider perspective, elasticity provisioning contributes to maximizing their financial gain while keeping their customers satisfied and reducing administrative costs. However, automatic elasticity provisioning is not a trivial task.
A common approach, employed by many elasticity controllers [1, 2] is to monitor the cloud service and (de-)provision virtual instances when a metric threshold is violated. This approach may be sufficient for simple service models but, when considering large-scale distributed cloud services with various interdependencies, a much deeper understanding of its elasticity behavior is required. For this reason, existing work [2, 3] has identified a number of elasticity control processes to improve the performance and quality of cloud services, while additionally attempting to minimize cost. However, a crucial question still remains unanswered: which elasticity control processes are the most appropriate for a cloud service in a particular situation at runtime? Both cloud customers and providers can benefit from insightful information such as how the addition of a new instance to a cloud service will affect the throughput of the overall deployment and individually on each part of the cloud service. Thus, cloud service elasticity behavior knowledge under various controls and workloads is of paramount importance to elasticity controllers for improving runtime decision making.
To this end, a wide range of approaches relying on service profiling or learning from historic information [3–5] have been proposed. However, these approaches limit their decisions to evaluating only low-level VM metrics (i.e., CPU and memory usage) and do not support elasticity decisions based on cloud service behavior at multiple levels (i.e., per node, tier, entire service). Additionally, current approaches only evaluate resource utilization, without considering elasticity as a multi-dimensional property composed of three dimensions (cost, quality and resource elasticity). In our previous work, we focused on modeling current and previous behavior with the concepts of elasticity space and pathway [6], or using different algorithms to determine enforcement times in observed behavior (e.g., with change-point detection), but without modeling expected behavior of different service parts, in time. Finally, existing approaches do not consider the outcome of a control process on the overall service, where often enforcing a control process to the wrong part of the cloud service, can lead to side effects, such as increasing the cost or decreasing performance of the overall service.
In this paper, we focus on addressing the above limitations by introducing the ADVISE (evAluating clouD serVIce elaSticity bEhavior ) framework, which estimates cloud service elasticity behavior by utilizing different types of information, such as service structure, deployment strategies, and underlying infrastructure dynamics, when applying different external stimuli (e.g., elasticity control processes). At the core of ADVISE is a clustering-based evaluation process which uses these types of information for computing expected elasticity behavior, in time, for various service parts. To evaluate ADVISE effectiveness, experiments were conducted on a public cloud platform with a testbed comprised of two different cloud services. Results show that ADVISE outputs the expected elasticity behavior, in time, for different services with a low estimation error rate. ADVISE can be integrated by cloud providers alongside their elasticity controllers to improve their decision quality, or used by cloud service providers to evaluate and understand how different elasticity control processes impact their service.
The rest of this paper is structured as follows: in section 2 we model relevant information regarding cloud services. In section 3, we present the elasticity behavior evaluation process. In section 4, we evaluate ADVISE framework effectiveness. In section 5 we discuss related work. Section 6 concludes this paper.
2 Cloud Service Structural and Runtime Information
2.1 Cloud Service Information
To follow existing common service descriptions [7], we refer to a cloud application in our study as a cloud service. A cloud service can be decomposed into service topologies (e.g., a business tier, or a part of a workflow) which represent a group of semantically connected service units. A service unit (e.g., a web service) represents a module offering computation or data capabilities. In order to refer to these cloud service structures globally, we use the term Service Parts (SP).
We extend the conceptual cloud service representation model proposed in [8] with a rich set of information types for determining cloud elasticity behavior. Fig. 1 depicts the extensions we made (white background) to include elasticity control processes, service part behaviors and service parts. Overall, this representation contains: (i) Structural Information, describing the architectural structure of the application to be deployed on the cloud, (ii) Infrastructure System Information, describing runtime information regarding resources allocated by the cloud service from the underlying cloud platform, and (iii) Elasticity Information, which is associated with both structural and infrastructure system information for describing elasticity metrics, requirements, and capabilities.
چکیده
1. مقدمه
2. ساختار سرویس ابری و اطلاعات زمان اجرا
2.1 اطلاعات سرویس ابری
2.2 فرایندهای کنترل کشش
2.3 کشش سرویس ابری در زمان اجرا
3. ارزیابی رفتار کشش سرویس ابری
3.1 فرایند یادگیری
3.2 تعیین رفتار کشش مورد انتظار
4. آزمایش ها
4.1 سرویس های آزمایشی
4.2 برآورد رفتار کشش
4.3 تاثیر موقتی ECP
4.4 کیفیت نتایج
5. کار مربوطه
6. نتیجه گیری و کار آینده
منابع
Abstract
1 Introduction
2 Cloud Service Structural and Runtime Information
2.1 Cloud Service Information
2.2 Elasticity Control Processes
2.3 Cloud Service Elasticity During Runtime
3 Evaluating Cloud Service Elasticity Behavior
3.1 Learning Process
3.2 Determining the Expected Elasticity Behavior
4 Experiments
4.1 Experimental Services
4.2 Elasticity Behavior Estimation
4.3 ECP Temporal Effect
4.4 Quality of Results
5 Related Work
6 Conclusions and Future Work
References