
دانلود رایگان مقاله تولید مورد تست جهش رانده شده با استفاده از جهش همزمان کوتاه مدت
چکیده
در زمینه تست جعبه سیاه، موارد تست تولید از طریق مدل کردن جهش ، برای تولید مجموعه تست قدرتمند شناخته شده است، اما معمولا مشکل گران بودن را دارد. این مقاله یک نسخه جدید از ابزار MoMuT::UML را ارائه می دهد، که یک نسخه مقیاس پذیر از تولید مورد تست جهش رانده شده (MDTCG) را پیاده سازی می کند. آن قادر به کنترل مدل های UML با اندازه صنعتی شامل شبکه هایی از قبیل 2800 تعامل دستگاه های دولتی است. برای رسیدن به مقیاس پذیری مورد نیاز، الگوریتم پیاده سازی شده همزمانی را در MDTCG بکار می برد و آن را با یک استراتژی تولید مبتنی بر جستجو ترکیب می کند. برای ارزیابی، ما هفت مورد از حوزه های کاربردی مختلف با افزایش سطح دشواری را استفاده می کنیم، توقف در یک مدل از یک ایستگاه راه آهن در شبکه راه آهن اتریش.
1. مقدمه
برای سیستم های انفعالی، به ویژه در حوزه حیاتی ایمنی و در مواردی که بروزرسانی ها گران قیمت هستند، تست مناسب الزامی است. در حوزه پیشین، استانداردهای ایمنی در واقع نیازمند انواع خاصی از تست برای انجام شدن بود و بعضی استانداردها بسیار استفاده از روش های رسمی و تست مبتنی بر مدل را توصیه می کند. تولید مورد تست جهش رانده شده (MDTCG)، که یک شکل مبتنی بر نقص است [13]، می تواند در رضایت بخشی نیازمندی های مطرح شده توسط استانداردها کمک کند – اگر آن به اندازه کافی با مدل های با اندازه صنعتی کار می کرد.
در این کار، ما توقف مرزهای آنچه را می تواند با MDTCG انجام شود با پرداختن به مسائل مربوط به عملکرد ناشی از ماهیت خاص از مدل مبتنی بر مسئله تست جهش را مورد خطاب قرار می دهیم. برای این کار، ما از محل جهش برای اکتشاف خود بهره می بریم و از اکتشاف مبتنی بر جهش برای هدایت یک روش مبتنی بر جستجو در سرتاسر طرح های جهش استفاده می کنیم. به عنوان یک معیار، ما از هفت مدل مختلف UML با اندازه صنعتی استفاده می کنیم. توجه داشته باشید که ما نمی توانیم بیشتر از این با نسخه های قبلی مان از MoMuT::UML بکار ببریم [1]. مدل هم توسط مهندسان صنعتی در شرکت های همکار و یا در همکاری نزدیک با آنها ساخته شده است. کوچکترین مدل، رفتار یک سیستم دزدگیر ماشین معمولی را توصیف می کند، در حالی که بزرگترین مدل، مدل یک ایستگاه راه آهن با اندازه متوسط در شبکه راه آهن ملی اتریش است. مدل دارای ویژگی های مختلف است: برخی روش های نمادین مطلوب، برخی شمارشی های مطلوب، برخی از آنهایی که بسیار همزمان هستند، برخی به صورت سریال شده هستند، برخی از زمان گسسته استفاده می کنند، در حالی که دیگران استفاده نمی کنند.
جدول 1 یک مرور کلی از سه تولید MoMuT::UML و تفاوت آنها را نشان می دهد. تولید اول حدود سال 2010 ظاهر شد و بر اساس یک چک کننده متابعت ورودی خروجی شمارشی مبتنی بر پرولوگ (ioco) [17]، به نام ulisses بود، که با یک موتور جهش UML جداگانه جفت می شود. تولید یک اثبات کرد به اندازه کافی قدرتمند است برای کنترل مدل های ساده به پیچیده [3]. تولید دوم MoMuT::UML روش اکتشاف را از شمارش تفسیر به اکتشاف مبتنی بر حل کننده SMT تغییر داد. اگرچه پایان اثبات مبتنی بر SMT باعث کارآمدتر شدن نسبت به موتور تولید اول می شود و یک تاثیر عملکرد بزرگ با یک نوع خاص از مدل ایجاد می کند، نبود لیست پشتیبانی آن و متغیر شیء به این معنا که آن نمی تواند مدل هایی را که ما در نهایت برای هدف قرار دادیم بکار برد. ما آن را به طور موفقیت آمیز برای یک مورد بکار بردیم که دوباره در این مقاله ارائه می شود. مقاله [2] خلاصه زیر از یافته های ما هنگام استفاده از تولید دوم MoMuT::UML را ارائه می دهد:
ارقام در زمان محاسبه ثابت می کند که ما بیش از 60% از کل زمان TCG چک کردن معادل مدل جهش. ... داده ها همچنین نشان می دهند که موتور جهش ما نیاز به بهبود یافتن برای تولید جهش معنی دارتر است ... 80% از جهش مدل توسط موارد تست تولید شده برای 2% از آنها پوشیده شده است.
در آن زمان، مجموع مدت زمان TCG در بیش از 44 ساعت برای موارد تست با یک عمق 25 تداخل تولید شده از یک مدل UML شامل یک نمونه، و 64 ویژگی بود. هدف ما این بود که مدل ها را در بیش از 2000 نمونه، 3000 ویژگی رسیدگی کنیم و موارد تست بسیار عمیق تر در زمان کمتر تولید کنیم. بنابراین، برای MoMuT::UML 3.0، ما از چک کردن همزمانی رسمی به یک استراتژی اکتشاف مبتنی بر جستجو با جهش کوتاه مدت تغییر یافتیم که در [3] معرفی شده است:
... نویسندگان برای ترکیب اکتشاف تصادفی جهت دار و تولید مورد تست مبتنی بر جهش بر روی پرواز تلاش می-کنند. ایده این است که در طول اکتشاف از سیستم، جهش هایی که به وضعیت فعلی نزدیک هستند، به صورت پویا قرار داده شوند و همزمانی بررسی شود. ...
سهم این مقاله سه مرحله است. اول، ما تکنیک های استفاده شده در آخرین نسخه از MoMuT::UML را شرح می دهیم که به ما اجازه بالا بردن مقیاس MDTCG برای اندازه مدل صنعتی مربوطه را می دهد. دوم ما چهار مورد گرفته شده از صنعت اولین و سومین بار را ارائه می دهیم. ما رویکردمان را بر طبق سؤالات پژوهشی زیر ارزیابی می کنیم. سؤال پژوهشی 1: آیا ما می توانیم MDTCG برای مدل های صنعتی شده در هزینه (زمان و منابع) که کاربر مایل به قبول کردن باشد را استفاده کنیم؟ سؤال پژوهشی 2: آیا ما پوشش نقص کافی برای ابزار برای مفید شدن را حفظ می کنیم؟ سؤال پژوهشی 3: با توجه به دو روش هدایت اکتشافی مختلف، آیا هر دو روش به یک اندازه مناسب است؟
مقاله به صورت زیر مرتب شده است. بخش 2 مسئله تولید مورد تست مبتنی بر جهش را معرفی می کند، اشاره می کند به مشکلات اصلی مرتبط با آن، یک لیست از عملگرهای جهش مورد استفاده برای آزمایش های معروف را فراهم می کند، و یک مقدمه کوتاه از زبان مدل سازی سیستم های عمل شیء گرا را ارائه می دهد. بخش 3 معماری اصلی سیستم MoMuT::UML را ارائه می دهد، موتور جهش را با جزئیات مورد بحث قرار می دهد، و الگوریتم جهش کوتاه مدت را معرفی می کند. بخش 4 هفت مورد مطالعه را ارائه می دهد و توسط یک ارزیابی در بخش 5 دنبال می شود. مقاله با بحث پیرامون کارهای مرتبط در بخش 6 و نتیجه گیری در بخش 7 پایان می یابد.
2. تولید تست ها از مدل جهش
تولید مورد تست جهش رانده شده برای تولید به طور خودکار موارد تست تلاش می کند که قادر به تشخیص نقص ("جهش یافته") نسخه هایی از یک مشخصه داده شده ("مدل") هستند. تحقیقات نشان می دهند که این روش قدرتمند است و می تواند دیگر معیارهای پوشش را شامل شود، مانند پوشش شرایط [15]، با توجه به مجموعه صحیح از عملگرهای جهش. علاوه بر نیاز به یک مدل، اشکال اصلی MDTCG پیچیدگی محاسباتی در یافته های داده تست است که قادر به آشکار ساختن یک مدل نقص ("قابل جهش") است. این چالش به راحتی به عنوان یک مسئله مدل چک کردن معین می شود. با این حال، با استفاده از مدل چک کننده برای تست کردن تولید (نسل)، مسائل خاص خود را دارد [6]، مانند، مدل های بزرگ و غیر قطعی.
علاوه بر پیچیدگی کلی محاسباتی مسئله، موضوع دیگری که باعث افزایش بیشتر هزینه محاسباتی می شود، جهش معادل است. جهش معادل جهشی است که هیچ تفاوتی در رفتار را نشان نمی دهد. به عبارت دیگر، آنها معادل مدل اصلی هستند. این جهش ها، که نمی توانند به یک مورد تست منجر شوند، حداکثر جریمه را برای روش های TCG مبتنی بر اکتشاف جامع تحمیل می کنند. برای مثال، در نسخه قبلی MoMuT::UML، ما 60% از زمان کلی محاسبات در چک کردن جهش معادل صرف کردیم.
Abstract
In the context of black-box testing, generating test cases through model mutation is known to produce powerful test suites but usually has the drawback of being prohibitively expensive. This paper presents a new version of the tool MoMuT::UML, which implements a scalable version of mutation-driven test case generation (MDTCG). It is able to handle industrial-sized UML models comprising networks of, e.g., 2800 interacting state machines. To achieve the required scalability, the implemented algorithm exploits the concurrency in MDTCG and combines it with a search based generation strategy. For evaluation, we use seven case studies of different application domains with an increasing level of difficulty, stopping at a model of a railway station in Austria’s national rail network.
1 Introduction
For reactive systems, especially in the safety critical domain and in contexts where updates are expensive, proper testing is mandatory. In the former domain, safety standards actually require certain forms of testing to be conducted and some standards highly recommend the use of formal methods and model-based testing. Mutation-driven test case generation (MDTCG), which is a form of fault-based testing [13], could help in satisfying the requirements posed by the standards – if it worked well enough with industrial sized models.
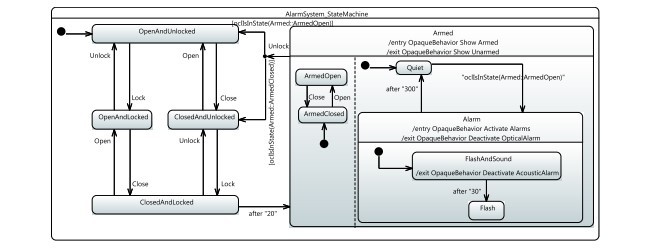
In this work, we address pushing out the boundaries of what can be done with MDTCG by addressing performance issues caused by the specific nature of the model-based mutation testing problem. To do so, we take advantage of the locality of mutations for the exploration itself and use mutation based heuristics for guiding a search based approach over mutant schemata. As a benchmark we use seven industrial sized UML models of different domains. Notice that we could not handle most of these with our previous versions of MoMuT::UML 1 [1]. The models were built either by industry engineers at partner companies or in close cooperation with them. The smallest model describes the behaviour of a typical car alarm system, while the largest is a model of a mid-sized railway station in the national rail network of Austria. The models have different characteristics: some favour symbolic approaches, some favour enumerative ones, some are highly concurrent, some are serialized, some use discrete time, while others do not.
Table 1 provides an overview of the three MoMuT::UML generations and their differences. The first generation appeared around 2010 and was based on a Prolog-based enumerative input-output conformance (ioco)[17] checker, called Ulysses, that was paired with a separate UML mutation engine. Generation one proved powerful enough to handle simple to slightly complex models [3]. The second MoMuT::UML generation changed the exploration approach from interpreted enumeration to SMT-solver-based exploration. Although the SMTbased back end proved to be more efficient than the first generation engine and made a big performance impact with a particular type of model, its lack of list-support and object variables meant it could not handle the models we were ultimately aiming for. That said, we applied it successfully to a use-case that is also re-presented in this paper. The article [2] provides the following summary of our findings when applying the second generation MoMuT::UML:
The figures on the computation time prove that we spend more than 60% of the total TCG time checking equivalent model mutants. . . . The data also demonstrates that our mutation engine needs to be improved to generate more meaningful mutants as . . . 80% of the model mutants are covered by test cases generated for 2% of them.
Back then, the total TCG time was in excess of 44 hours for test cases with a depth of 25 interactions generated from an UML model comprising one instance, and 64 attributes. Our goal was to handle models in excess of 2000 instances, 3000 attributes, and to produce vastly deeper test cases in less time. So, for MoMuT::UML 3.0 we switched from formal conformance checking to a searchbased exploration strategy with short-lived mutants as announced in [3]:
. . . the authors attempt to combine directed random exploration and mutation based test-case generation on-the-fly. The idea is that during the exploration of the system, mutations which are close to the current
state are dynamically inserted and conformance is checked. . . .
The contributions of this paper are threefold. First, we describe the techniques used in the latest version of MoMuT::UML that allow us to scale up MDTCG to industry relevant model sizes. Second we present four case studies taken from industry the first time and, third, we evaluate our approach according to the following research questions. RQ1: Can we apply MDTCG to industrialsized models at a cost (time, resources) the user would be willing to accept? RQ2: Do we retain enough fault coverage for the tool to be useful? RQ3: Given our two different guidance heuristics, are both equally suitable?
The paper is organized as follows. Section 2 introduces the mutation-based test case generation problem, mentions the main difficulties associated with it, provides a list of mutation operators used for the presented experiments, and gives a brief introduction of the Object-Oriented Action Systems modelling language. Section 3 presents MoMuT::UML’s main system architecture, discusses the mutation engine in detail, and introduces the short-lived-mutant algorithm. Section 4 then presents the seven case studies and is followed by an evaluation in Section 5. The paper closes with a discussion of related work in Section 6 and concludes in Section 7.
2 Generating Tests from Model Mutants
Mutation-driven test case generation strives to automatically produce test cases that are able to detect faulty (”mutated”) versions of a given specification (”model”). Research has shown that this methodology is powerful and can subsume other coverage criteria, like condition coverage [15], given the right set of mutation operators. Besides requiring a model, the main drawback of MDTCG is the computational complexity involved in finding test data that is able to reveal a faulty model (”mutant”). This challenge is easily cast as a model-checking problem, however, using model-checkers for test generation has its own issues [6], e.g., with large and non-deterministic models.
Besides the general computational complexity of the underlying problem, another issue that further increases the computational cost is that of equivalent mutants. Equivalent mutants are mutants that do not show any difference in behaviour. In other words, they are observationally equivalent to the original model. These mutants, which cannot lead to a test case, carry the maximum penalty for TCG approaches based on exhaustive exploration. For example, in our previous MoMuT::UML version, we spent 60% of the overall computation time in checking equivalent mutants.
چکیده
1. مقدمه
2. تولید تست ها از مدل جهش
2.1 زبان ورودی: سیستم های عمل شیء گرا
3. یک معماری برای جهش کوتاه مدت
3.1 طرح جهش
3.2 تولید مورد تست با جهش کوتاه مدت
4. مطالعات موردی
5. ارزیابی آزمایشی
6. کارهای مرتبط
7. نتیجه گیری و چشم انداز
منابع
Abstract
1 Introduction
2 Generating Tests from Model Mutants
2.1 The Input Language: Object-Oriented Action Systems
3 An Architecture for Short Lived Mutants
3.1 Mutant Schemata
3.2 Test Case Generation With Short-Lived Mutants
4 Case Studies
5 Experimental Evaluation
6 Related Work
7 Conclusions and Outlook
References