
دانلود رایگان مقاله راهبردهای پیشرفته یادگیری
10.1: ذخیره سازی الگوهای همبسته
همان طور که در بخش 3.1 و 4.3 بحث کردیم توانایی بیادآوری صحیح خاطره ها اگر عددp از الگوهای ذخیره شده از یک حد معین بیشتر شود تجزیه می شود(از بین می رود.).هنگامی که پیوندهای سیناپسی بر طبق قانون Hebb تعیین شده هستند،این کار در تراکم (چگالی)ذخیره سازی اتفاق می افتدα=p/N=0.138 .دلیل این رفتار،تاثیردیگر الگوهای ذخیره شده که با ضابطه اختلال نوسان در(3.13)بیان می شود،می باشد.همان طور که در انتهای بخش 3.1 اشاره کردیم،اگر الگوها بر یکدیگر متعامد باشند همانند انچه که در بخش (3.16) بیان شد،این اثر دقیقا ناپدید خواهد شد.به عبارت دیگر توان تجدیدخاطره روبه وخامت می رود حتی قبل از آنکه الگوهای ذخیره شده شدیدا با یکدیگر مرتبط شوند.درباره نمایش گرافیکی حروف رومی فکر کنید،جایی که E شباهت نزدیکی به F داردو C شبیه G است یا درباره لیست معمولی از اعداد کتابچه تلفن،که احتمالا بسیار به هم مرتبط هستند، فکرکنید.
از برنامه ASSO برای یادگیری و بیادآوری 26 حرف حروف الفبا استفاده کنید:A-Z مقادیر زیر را انتخاب کنید:(26/26/0/1) و (1//0/0/1;2) برای مثال آپدیت متوالی،دما و آستانه صفر و آزمایش با مقدار مجاز اختلال(صدا).آیا حرف خاصی پایدار است؟آزمایش را با 6 حرف اول الفبا و مطالعه توانایی شبکه در به یادآوردن حروف مشابه E و F تکرارکنید.
ماهیت مساله از آنچه که در بخش قبلی در ارتباط با شبکه های لایه ای تغذیه مستقیم مطرح شد،فرق نمی کند.ضابطه یادگیری پرسپترون راهبرد یادگیری کامل برای پرسپترون های ساده بدون لایه های مخفی نورون ها فراهم می کند.با این حال،این طرح ها در عمل قابل استفاده نیستند چون حتی در حل مسایل بسیار ساده هم شکست می خورند.به همین دلیل است که مفاهیم پرسپترون برای بیست سال کنارگذاشته شد،اگرچه پرسپترون های چندلایه با لایه های پنهان نورون از چنین مشکلی رنج نمی برد.اما بدون الگوریتم یادگیری عملی،که درابتدا با خطای پس انتشار در دسترس است،یک جایگزین عملی فراهم نخواهد شد.
به طورمشابه بعضی از مشکلات عملی برخورد شده با شبکه های حافظه انجمنی ماهیت طبیعی ندارند،بلکه در عوض نتیجه نارسایی شکل اولیه قانون(ضابطه) یادگیری Hebb می باشند.قانون هب (Hebb)بر پایه مفاهیم اندازه گیری فاصله هامینگ(Hamming) بین الگوهای مختلف نهاده شده است.در اصطلاح ریاضی اندازه فاصله یا سنجش،متریک اقلیدسی(Euclidean metric) در فضای الگوها نامیده می شود.عموما بیشتراندازه گیری ها از فاصله بین الگوهای مختلف امکان پذیر است و اگرالگوها با یکدیگر ارتباط داشته باشند(همبسته باشند) ممکن است مفید باشد.برای مثال در مورد حرف های E و F فاصله اندازه گیری شده منحصرا بر پایه بخش پایین حرف است که به راحتی بین الگوها موردتبعیض واقع می شود.با این حال همان طور که حرف های K و R نشان می دهد،این انتخاب ساده هنوز یک جواب عمومی فراهم نکرده است و نه حتی برای الفبا.
10.1.1 قانون تجسم
با این وجود روشن است که مشکل تبعیض بین الگوهای مرتبط یک جواب ساده مهم دارد که حتی به ذخیره گاه p=N اجازه می دهد به طور اختیاری الگوهای همبسته را انتخاب کند تا زمانی که به طور خطی مستقل باشند.برای دیدن اینکه چگونه کار می کند ماتریس ضرب اسکالر بین جفت الگوها(σ_i^μ=±1) را تشکیل می دهیم:
Q_μv=1/N ∑_i〖σ_i^μ σ_i^v 〗 (1≤μ,v≤p) (10.1)
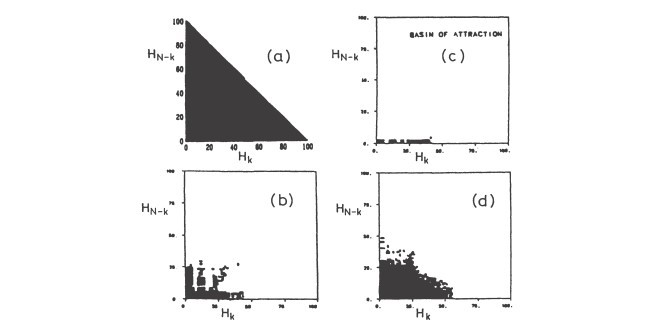
کیفیت به یاد آوری الگو با افزایش دما و استفاده از حافظه α=p/N رو به تحلیل می رود.همانند مورد قانون Hebb کیفیت بازیابی با پارامتر m تعریف شده در(4.15) می باشد. m=1 نشان دهنده یادآوری کامل حافظه است با این حال m=0 نشان دهنده فراموشی کامل است.ناحیه کارآیی و فراموشی حافظه با مقدار m در مرز فاز در شکل 10.1 نشان داده شده است.شعاع جذب R الگوی ذخیره شده در شکل 10.2 به عنوان تابعی از تراکم ذخیره α برای مدل های کانتر و سامپولینسکی و پرسوناز،نشان داده شده است.در اینجا شعاع جذب با رابطه R=1-m0 تعریف شده است که m0 کمترین همپوشانی الگوی si که می تواند با الگوی ذخیره شده σ_i داشته باشد،که به طور قطعی توسط شبکه تشخیص داده می شود.همان طور که می بینیداز بین رفتن جفت های مورب ω_ij در مدل [Ka87] منحنی (a) اثر موثرتری(بهینه تر) دارد.
10.1.2 طرح یادگیری تکرار شونده
کاربردهای عملی قاعده آموزش تصویری برای شبکه های بزرگ حافظه اشباع شده از نیاز مبرم تبدیل p×p ماتریس Q_μv که مشکل عددی دشواری را دربرخواهد داشت،رنج می برد.خوشبختانه تبدیل معکوس ماتریس فقط یکبار انجام می شود وقتی الگوها در داخل شبکه ذخیره شده اند.حافظه ریشه دوانده می تواند اغلب مطابق انتظار بدون تلاش اضافی یادآوری کند.روش عملی اجرای قاعده (قانون)تصویربرپایه طرح تکرارشونده بنانهاده شده است که پیوندهای سیناپسی صحیح به یکدیگر متصل شده اند تا الگوهای وابسته را در برابر یکدیگر پایدار کنند.به خاطرساده سازی این روش را فقط برای شبکه قطعی(T=0) نشان می دهیم.
10.1.3 یادگیری مکرر Hebbian
10-1-3:برای بیشتر اهداف عملی لازم نیست که دقیقا از جفت های سیناپسی بهینه ω ̃_ij استفاده کنیم یا به عبارت دیگرلازم نیست که سمت چپ معادله (10.7) را دقیقا برابر با یک بدست آوریم.یادآوری می کنیم که نقطه شروع ملاحظات ما،این خواسته بود که عبارت σ_i^μ h_i را به طور چشمگیری بزرگتر از آستانه صفر پایداری-بحرانی بدست آوریم.این شرط نیز اگرپیوند سیناپسی را طوری تصحیح کنیم که سمت چپ (10.7) بزرگتر یا مساوی با آستانه ĸ داده شده باشد که ممکن است با یک برابر باشد یا نباشد،نیز صدق خواهد کرد.این رابطه یک مزیت مهمی دارد که فرایند تکرارشونده بعد از چندمرحله محدود قطعا به پایان خواهد رسید و بالاترین ظرفیت حافظه را ایجاد خواهد کردα_c=2.
10.1 Storing Correlated Patterns
As we discussed in Sects. 3.1 and 4.3, the ability to recall memories correctly breaks down if the number p of stored patterns exceeds a certain limit. When the synaptic connections are determined according to Hebb's rule (3.12), this happens at the storage density a = piN = 0.138. The reason for this behavior was the influence of the other stored patterns as expressed by the fluctuating noise term in (3.13). As we already pointed out at the end of Sect. 3.1, this influence vanishes exactly if the patterns are orthogonal to each other as defined in (3.16). On the other hand, the power of recollection deteriorates even earlier if the stored patterns are strongly correlated. Unfortunately, this happens in many practical examples. Just think of the graphical representation of roman letters, where "E" closely resembles "F" and "e" resembles "G", or of a typical list of names from the telephone book, which are probably highly correlated.
Use the program ASSO (see Chapt. 22) to learn and recall the 26 letters of the alphabet: A-Z. Choose the following parameter values: (26/26/0/1) and (1/0/0/1;2), i.e. sequential updating, temperature and threshold zero, and experiment with the permissible amount of noise. Is any letter stable? Repeat the exercise with the first six letters of the alphabet and study the network's ability to recall the similar letters "E" and "F".
The nature of the problem is not so different from that encountered in the previous section in connection with layered feed-forward networks. The perceptron learning rule provides the perfect learning strategy for simple perceptrons without hidden layers of neurons. However, these devices are not particularly useful in practice, since they fail to solve even some very simple tasks. This is the reason why the perceptron concept fell out of grace for almost twenty years, although multilayered perceptrons with hidden neurons do not suffer from such ailments. But without a practical learning algorithm, which became first available with error back-propagation, they did not provide a practical alternative.
Similarly, some of the practical difficulties encountered with associativememory networks are not of a fundamental nature, but rather a consequence of the inadequacy of the elementary form (3.12) of Hebb's learning rule. As we discussed in Sect. 3.1, Hebb's rule is based on the concept of the Hamming measure (3.1) of distance between different patterns. In mathematical terms, this distance measure or metric is called the Euclidean metric in the space of patterns. More general measures of the distance between different patterns are conceivable and may be more useful if the patterns are correlated. For example, in the case of the letters "E" and "F" a distance measure based solely on the bottom part of the letter would easily discriminate between the patterns. However, as the letters "K" and "R" show, this simple choice does not yet provide a general solution, not even for the alphabet.
10.1.1 The Projection Rule
Nonetheless, it turns out that the problem of discriminating between correlated patterns has a remarkably simple solution, which even permits the storage of p = N arbitrarily correlated patterns, as long as they are linearly independent. To see how it works, we form the matrix of scalar products between all pairs of patterns (O'f = ± 1):
Q_μv=1/N ∑_i〖σ_i^μ σ_i^v 〗 (1≤μ,v≤p) (10.1)
The quality of pattern recall deteriorates with growing temperature T and memory utilization a = piN [Ka87].1 As in the case of Hebb's rule the quality of recollection is described by the parameter m defined in (4.15). m = 1 denotes perfect memory recall, whereas m = 0 indicates total amnesia. The regions of working and confused memory are shown, together with the value of m at the phase boundary, in Fig. 10.1. The radius of attraction R of the stored patterns is shown in Fig. 10.2 as function of storage density a for the models of Kanter and Sompolinsky [Ka87] (curve a) and Personnaz et al. [Pe86b] (curve b). Here the radius of attraction is defined as R = 1 - mo, where mo is the smallest overlap a pattern Si can have with a stored pattern (/i to be recognized with certainty by the network. As one sees, the elimination of the diagonal couplings Wii in the model of [Ka87J, curve (a), has a very beneficial effect.
10.1.2 An Iterative Learning Scheme
The practical application of the projection learning rule for large, memorysaturated networks suffers from the need to invert the (p x p)-matrix QjJ.v, which poses a formidable numerical problem. Fortunately, the matrix inversion need be performed only once, when the patterns are stored into the network. The ingrained memory can then be recalled as often as desired without additional effort. A practical method of implementing the projection rule is based on an iterative scheme, where the "correct" synaptic connections are strengthened in order to stabilize the correlated patterns against each other [Di87]. For the sake of simplicity, we demonstrate this method only for the deterministic network (T = 0).
10.1.3 Repeated Hebbian Learning
For most practical purposes it is not necessary to use precisely the optimal synaptic couplings Wij, or, in other words, it is not essential to render the left-hand side of (10.7) exactly equal to one. We recall that the starting point of our considerations was the desire to make the expression O'f hi significantly greater than the critical-stability threshold zero. This condition is also satisfied if we modify the synaptic connection in such a way that the left-hand side of (10.7) is greater than or equal to a given threshold K" which mayor may not be taken equal to 1. This condition has the important advantage that the iteration process is guaranteed to come to an end after a finite number of steps, and it yields a maximal memory capacity ac = 2.
10.1 ذخیره سازی الگوهای همبسته
10.1.1 قانون تجسم
10.1.2 طرح یادگیری تکرار شونده
10.1.3 یادگیری مکرر Hebbian
10.2 قانون یادگیری خاص
10.2.1 ارتقاء حافظه را فراموش کنید!
10.2.2 قانون یادگیری غیرخطی
10.2.3 رقت سیناپس
10.1 Storing Correlated Patterns
10.1.1 The Projection Rule
10.1.2 An Iterative Learning Scheme
10.1.3 Repeated Hebbian Learning
10.2 Special Learning Rules
10.2.1 Forgetting Improves the Memory!
10.2.2 Nonlinear Learning Rules
10.2.3 Dilution of Synapses