
دانلود رایگان مقاله الگوهای پایگاه داده توزیع شده
مدیران برنامههای کاربردی وب بهطور سنتی، بههنگام تقاضای برنامهای بیش از ظرفیت پایگاهداده، دو راه بیشتر ندارند: مقیاسگذاری با افزایش قدرت سرورهای شخصی، یا مقیاسگذاری با اضافه کردن سرورهای بیشتر. برای بسیاری از پایگاهدادههای رابطهای، مقیاسگذاری با افزایش قدرت سرورهای شخصی گزینه عملیتری بود. اخیرا پایگاهدادههای رابطهای، گزینهی خوشهبندی را فراهم نمیکردند، درحالیکه پردازنده و حافظه عرضه شده توسط یک سرور بهطور مداوم و بهصورت تصاعدی و بنا به قانون Moore در حال افزایش بود. در نتیجه، مقیاسگذاری با اضافه کردن سرورهای بیشتر نهتنها عملی نیست بلکه لازم هم نیست.
بااینحال، زمانیکه حجمکار پایگاهداده از برنامههای کلاینت سرور درحال اجرا به پشت دیوار آتش برنامههای کاربردی وب با دامنه بالقوه جهانی منتقل میشود، پشتیبانی از حجمکار و دسترسی به نیازمندیها بر روی تک سرور بهطور فزایندهای دشوار میشود. علاوه براین، برنامههای کاربردی اینترنت اغلب در معرض رشد غیرقابل پیشبینی و عظیمی در حجمکار هستند: بنابراین برای یک نرمافزار، "go viral" امکانپذیر میشود و بهطور ناگهانی رشد نمایی در تقاضا را تجربه میکند. نقطه شیرین اقتصادی برای سختافزار کامپیوتر و الزامات رشد فزایندهای در خوشههای سرور به جای تک سرور داشته است. بنابراین یک راهحل مقیاسپذیر برای پایگاهداده ضروری به نظر میرسد.
برای پرداختن به خواستههای برنامههای کاربردی در مقیاس وب، نسل جدیدی از پایگاهدادههای رابطهای توزیعشده پدید آمدند. در این فصل، معماری این سیستم پایگاهداده توزیع شده بحث شده است.
پایگاهدادههای رابطهای توزیعشده
سیستمهای پایگاهداده برای اولین بار برای اجرا بر روی یک کامپیوتر طراحی شده بودند. در واقع، قبل از انقلاب کلاینت سرور، تمام اجزای برنامههای کاربردی از جمله پایگاهدادههای اولیه، تماما در یک سیستم واحد اجرا میشدند: پردازنده مرکزی.
در این مدل متمرکز، تمام کدهای برنامه برروی سرور اجرا میشود و کاربران با کد برنامه از طریق پایانههای dump (پایانهها "dump" هستند چرا که حاوی هیچ کد نرمافزاری نیستند) ارتباط برقرار میکنند. در مدل کلاینت سرور، منطق کسبوکار به اجرا درآمده معمولا رایانههای شخصی ویندوز هستند-که با یک تماس پایان، با سرور پایگاهداده ارتباط برقرار میکنند. در برنامههای کاربردی اینترنت، منطق کسبوکار در یک یا چند سرور برنامههای تحت وب اجرا میشد، درحالیکه منطق ارائه شده بین مرورگر وب و سرور برنامه کاربردی، به اشتراک گذاشته میشود و هنوز هم تقریبا همیشه با یک سرور پایگاهداده ارتباط برقرار میکند.
تکرار
تکرار پایگاهداده ،در ابتدا بهعنوان وسیلهای برای رسیدن به دسترسی بالا استفاده میشد. با استفاده از تکرار، مدیران پایگاهداده میتوانند یک پایگاهداده آماده به کار را که میتواند بر روی پایگاهداده اولیه در صورت شکست عمل کند پیادهسازی میکنند.
تکرار پایگاهداده اغلب از تراکنشهای صورت گرفته در بسیاری از پایگاهدادههای رابطهای برای حمایت از تراکنشهای ACID استفاده میکند. در این مقاله الگوی تراکنشهای ورودی در مورد حافظه پایگاهدادهها در فصل 7 معرفی شده است. هنگامی که یک تراکنش در یک پایگاهداده ACID سازگار باشد، رکورد تراکنش بلافاصله پس از ورود به لاگ تراکنش برای حفاظت در برابر شکست نوشته میشود. نظارت بر فرآیند تکرار در لاگ تراکنشها میتواند منجر به تغییرات پشتیبانگیری در پایگاهداده گردد، در نتیجه یک کپی ایجاد میکند.
شکل 8-2 روش تکثیر مبتنی بر ورود به سیستم را نشان میدهد. تراکنشهای پایگاهداده در یک فایل پایگاهدادهی ناهمزمان "تنبل" نوشته میشود (1)، اما تراکنش پایگاهداده بلافاصله وارد حالت commit میشود (2). روند تکرار بر ورود تراکنشها و اعمال معاملات همانند نوشتن فقط خواندنی در پایگاهداده نظارت میکند (3). تکرار معمولا ناهمزمان است، اما در برخی از پایگاهدادهها commit میتواند تا تکرار تراکنش به تعویق بیافتد.
همانطور که در فصل 3 دیدیم، تکرار، اولین گام به سوی پایگاهدادهی توزیعشده در سرورهای متعدد است. با استفاده از تکرار، حجمکار خواندن را میتوان برای توزیع مقیاسگذاری کرد، اگر چه تراکنشهای پایگاهداده هنوز هم باید به نسخه اصلی اعمال شود.
دیسک بهاشتراک گذاشته شده و به اشتراک گذاشته نشده
الگوی تکرار برای توزیع حجمکار پایگاهداده برای توزیع فعالیت خواندن توسط سرورهای متعدد به خوبی عمل میکند، اما بارهای نوشتن تراکنشها توزیع نمیشود، که هنوز هم باید بهطور انحصاری به سرور اصلی ارسال شوند.
Administrators of web applications have traditionally had two choices when the application demand exceeds database capacity: scaling up by increasing the power of individual servers, or scaling out by adding more servers. For most of the relational database era, scaling up was the more practical option. Early relational databases did not provide a clustering option, whereas the CPU and memory supplied by a single server was constantly and exponentially increasing in line with Moore’s law. Consequently, scaling out was neither practical nor necessary.
However, as database workloads shifted from client-server applications running behind the firewall to web applications with potentially global scope, it became increasingly difficult to support workload and availability requirements on a single server. Furthermore, Internet applications were often subject to unpredictable and massive growth in workload: it became possible for an application to “go viral” and to suddenly experience exponential growth in demand. The economic sweet spot for computer hardware and the imperatives of growth increasingly encouraged clusters of servers rather than single, monolithic proprietary servers. A scale-out solution for databases became imperative.
To address the demands of web-scale applications, a new generation of distributed nonrelational databases emerged. In this chapter, we’ll dive deep into the architectures of these distributed database systems.
Distributed Relational Databases
The first database systems were designed to run on a single computer. Indeed, prior to the client-server revolution, all components of early database applications—including all the application code—would reside on a single system: the mainframe.
In this centralized model, all program code runs on the server, and users communicate with the application code through dumb terminals (the terminals are “dumb” because they contain no application code). In the client-server model, presentation and business logic were implemented on workstations— usually Windows PCs—that communicated with a single back-end database server. In early Internet applications, business logic was implemented on one or more web application servers, while presentation logic was shared between the web browser and the application server, which still almost always communicated with a single database server.
Replication
Database replication was initially adopted as a means of achieving high availability. Using replication, database administrators could configure a standby database that could take over for the primary database in the event of failure.
Database replication often took advantage of the transaction log that most relational databases used to support ACID transactions. We introduced the transaction log pattern in the context of in-memory databases in Chapter 7. When a transaction commits in an ACID-compliant database, the transaction record is immediately written to the transaction log so that it is preserved in the event of failure. A replication process monitoring the transaction log can apply changes to a backup database, thereby creating a replica.
Figure 8-2 illustrates the log-based replication approach. Database transactions are written in an asynchronous “lazy” manner to the database files (1), but a database transaction immediately writes to the transaction log upon commit (2). The replication process monitors the transaction log and applies transactions as they are written to the read-only slave database (3). Replication is usually asynchronous, but in some databases the commit can be deferred until the transaction has been replicated to the slave.
As we saw in Chapter 3, replication is typically a first step toward distributing the database load across multiple servers. Using replication, the read workload can be distributed in a scale-out fashion, although database transactions must still be applied to the master copy.
Shared Nothing and Shared Disk
The replication pattern for distributing database workloads works well to distribute read activity across multiple servers, but it does not distribute transactional write loads, which still must be directed exclusively to the master server.
پایگاهدادههای رابطهای توزیعشده
تکرار
دیسک بهاشتراک گذاشته شده و به اشتراک گذاشته نشده
پایگاهدادهی توزیع شدهی غیررابطهای
MongoDB shardingو تکرار
sharding
مکانیزم sharding
تعادل خوشه
تکرار
نگرانی نوشتن و اولویت خواندن
HBase
جداول، مناطق، و RegionServers
ذخیره و محلیت داده
مرتبسازی Rowkey
انشعاباتRegionServer، حفظ تعادل و شکست
تکرار منطقه
Cassandra
شایعات بیاساس
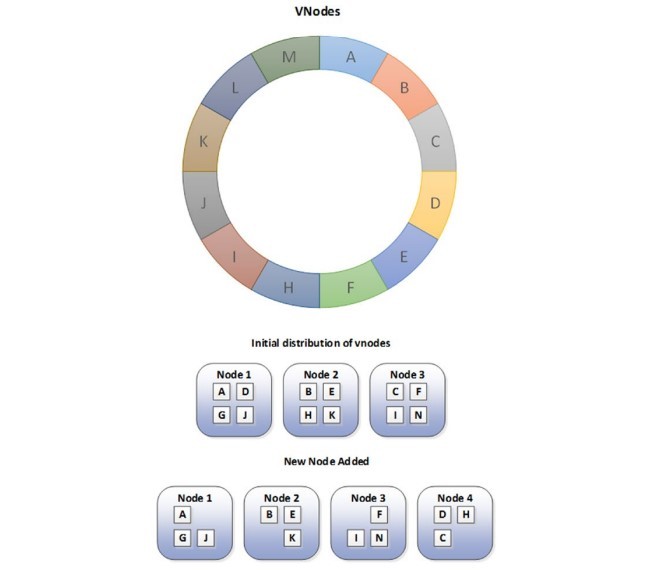
هش سازگار
پارتیشنبندی جهت محافظت از سفارشها
تکرارها
Snitches
خلاصه
Distributed Relational Databases
Replication
Shared Nothing and Shared Disk
Nonrelational Distributed Databases
MongoDB Sharding and Replication
Sharding
Sharding Mechanisms
Cluster Balancing
Replication
Write Concern and Read Preference
HBase
Tables, Regions, and RegionServers
Caching and Data Locality
Rowkey Ordering
RegionServer Splits, Balancing, and Failure
Region Replicas
Cassandra
Gossip
Consistent Hashing
Order-Preserving Partitioning
Replicas
Snitches
Summary