
دانلود رایگان مقاله فناوری های اطلاعات بزرگ و مدیریت
چکیده
دوران دادههای بزرگ منجر به توسعه و کاربرد فناوریها و روشهایی شد که به طور مؤثر با استفاده از حجم وسیع دادهها به پشتیبانی تصمیمگیری و فعالیتهای کشف دانش کمک میکنند. در این مقاله، پنج V داده بزرگ، حجم، سرعت، تنوع، صحت و ارزش، و همچنین فناوریهای جدید شامل پایگاه داده NoSQL که مطابق با نیازهای ابتکاری دادههای بزرگ ارائه شده، بررسی میشوند. سپس نقش مدلسازی مفهومی برای دادههای بزرگ بررسی شده و پیشنهاداتی درباره تلاشهای مدلسازی مفهومی مؤثر با توجه به دادههای بزرگ ارائه میشود.
1. مقدمه
دادههای بزرگ به طور گسترده به عنوان مقادیر بسیار زیاد دادهها شناخته میشوند، ساختاریافته و غیرساختاریافته، که در حال حاضر سازمانها قادر به دستیابی و تلاش برای تحلیل معنیدار بودن آنها هستند به طوری که تحلیل تصمیمگیری بر پایه داده ها و بینش عملی بدست میآید. انجام این کار مستلزم توسعه تکنیکها و روشهای تحلیل، ایجاد روشهای جدید برای ساخت دادهها و برنامه های جالب در علم و مدیریت است (به عنوان مثال، [1، 8، 19]). با وجود به چالش کشیدن ارزش دادههای بزرگ، چشم انداز دادهها همچنان رشد میکند [28].
هدف این مقاله بررسی پیشرفت دادههای بزرگ در تلاش برای شناسایی چالشهای موجود است؛ و نقشی که مدلسازی مفهومی می تواند در پیشبرد کار در این حوزه مهم بازی کند را تعیین می کند. بخش بعدی، توصیف دادههای بزرگ و ویژگی های ذاتی شناخته شده است. سپس، پیش از تحلیل نقش به خصوصی که مدلسازی مفهومی در درک و پیشرفت تحقیق و کاربرد دادههای بزرگ بازی می کند، فناوری دادههای جدید و در حال ظهور ارائه میشوند.
2. دادههای بزرگ
حجم دادهها در دهه گذشته به طور نمایی افزایش یافته است، تا جایی که مدیریت دارایی دادهها با استفاده از روشهای سنتی امکانپذیر نیست (ریبریو و همکاران، 2015). همان طور که در شکل 1 نشان داده شده است، روند پیشرفت دادهها با پیشرفت فناوریهای محاسباتی امکانپذیر شده است که منجر به انفجار ناگهانی دادههای منابع مختلف مانند وب، رسانههای اجتماعی و سنسورها شده است. سیل دادهها سبب ظهور الگویی مبتنی بر دادهها شد تا از فناوریهای جدید محاسبات در دسترس استفاده شود. فناوریهای دادههای بزرگ، منجر به الگوی مبتنی بر دادهها میشود و آن را به طور فزایندهای پیچیدهتر و مفیدتر میکند.
دادههای بزرگ به حجم بالا، سرعت و انواع داراییهای اطلاعاتی اشاره می کنند که به پردازشهای جدید و نوآورانه برای تصمیم گیری پیشرفته، بینش کسب و کار و بهینه سازی روند کار احتیاج دارد [23]. به عنوان مفهوم نسبتاً جدید، مفهوم اصلی دادههای بزرگ شامل تکنیکها و فناوریهای مورد نیاز برای مدیریت حجم بسیار زیاد دادهها است. علاوه بر فناوری، برای تحلیل و طراحی با مهارت لازم جهت مدیریت این منبع، متخصصان ماهر مورد نیاز هستند [2 و 21].
مایر- اسچونبرگر و کوکیر (2013) استدلال کردند که دادههای بزرگ باعث تغییر رفتار افراد، کار و تفکر میشوند، هر چند که لازم است بسیاری از موانع برطرف شوند. دادهها باید بدست آمده، پردازش شوند و به طور مؤثر مورد استفاده قرار گیرند، موضوعات مربوط به چگونگی نمایش دادهها و مدلسازی دادهها افزایش مییابد. هر چند که درک چالشهای مرتبط با نمایش و مدلسازی دادههای بزرگ، ابتدا به درک ویژگیهای دادههای بزرگ نیاز دارد.
2.1. Vهای داده های بزرگ
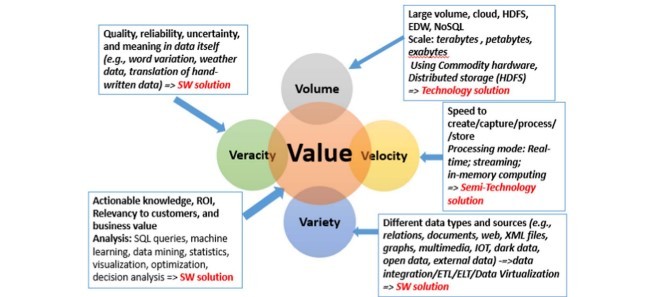
دادههای بزرگ به طور سنتی با استفاده از سه V حجم، تنوع و سرعت مشخص میشود که برگرفته از پیشرفت در سنجش، ارزیابی و فناوری های محاسبات اجتماعی است (Gartner.com). علاوه بر این Vها، درستی (دقت) و به ویژه ارزش، مهم هستند. هر یک ار ارزشها دارای چالش های منحصر به فردی هستند. حجم بیش از حد بزرگ به انواع تحلیل ساختاریافته و غیرساختاریافته احتیاج دارد و سرعت بسیار بالا حتی ممکن است منجر به عدم تشخیص سؤالات معقول شود [14]. درستی منجر به عدم اطمینان می شود، و حجم با سرعت رقابت میکند [34]. با این وجود، این حجم برای استخراج وقت گیرتر است، و برای اطمینان دشوار است. شکل 2 خلاصه ای از چالشهای پنج V را در عملکردهای دادههای بزرگ و تلاشهای تحقیقاتی نشان میدهد.
حجم: حجم زیاد دادهها موجب دسترسی به دادهها در جریانهای دادهای متنوع میشود و اغلب به موقعیت مکانی وابسته است که شامل انواع مختلفی داده میشود که با سرعت بسیار بالا از بانکهای بزرگ سنسورهای فیزیکی، دیجیتال و انسانی ایجاد میشود [16]. منابع داده شامل فناوریهای قابل پوشش، خدمات مبتنی بر ابر (به عنوان مثال، خدمات وب آمازون)، انبار دادههای سازمانی (EDW) و پایگاههای داده NoSQL است. مقیاس در حال حاضر ترابایت، پیتربیت و اکوبایت است. چالش حجم با استفاده از سخت افزار و سیستم فایل توزیع شده Hadoop (HDFS) از نظر تکنیکی مورد توجه قرار گرفته است.
سرعت: سرعت، سرعت ایجاد، ضبط، استخراج، پردازش و ذخیره دادهها است. برای مقابله با چالش سرعت، راهحل نیمه تکنولوژی با بخش راهحل نرمافزاری مورد نیاز است که دارای پردازش در زمان واقعی، جریان و محاسبات حافظه، است.
انواع: انواع دادهها و منابع مختلف روابط (از پایگاه دادههای ارتباطی)، اسناد، دادههای وب، فایلهای XML، دادههای سنسور، فایلهای چندرسانهای و غیره را ارائه میدهند. چالشهای گوناگون عمدتاً با راهحلهای پیچیده حل میشوند، زیرا ادغام دادههای ناهمگن به تلاش گسترده برای بررسی انواع مختلف نیاز دارد.
ABSTRACT
The era of big data has resulted in the development and applications of technologies and methods aimed at effectively using massive amounts of data to support decision-making and knowledge discovery activities. In this paper, the five Vs of big data, volume, velocity, variety, veracity, and value, are reviewed, as well as new technologies, including NoSQL databases that have emerged to accommodate the needs of big data initiatives. The role of conceptual modeling for big data is then analyzed and suggestions made for effective conceptual modeling efforts with respect to big data.
1. Introduction
Big data is widely recognized as referring to the very large amounts of data, both structured and unstructured, that organizations are now capable of capturing and attempting to analyze in a meaningful way so that data-driven decision analysis and actionable insights can be obtained. Doing so has required the development of techniques and methods for analysis, new ways to structure data, and interesting applications in science and in management (e.g., [14,5,1]). Although the value of big data has sometimes been challenged, the big data landscape continues to grow [22].
The objective of this paper is to examine the progression of big data in an effort to: identify the challenges that exist; and specify the role that conceptual modeling can play in advancing work in this important area. The next section defines and describes big data and its recognized, inherent characteristics. Then, new and emerging big data technologies are presented before analyzing the specific role that conceptual modeling can play in understanding and advancing research and applications of big data.
2. Big Data
The volume of data has grown exponentially over the past decade, to the point where the management of the data asset by traditional means is no longer possible [26]. As shown in Fig. 1, big data trends have been enabled by advances in computing technologies, which facilitated the sudden explosion of data from various sources such as the Web, social media, and sensors. The flood of data brought about the emergence of a data-driven paradigm to take advantage of the newly available computing technologies. Big data technologies materialized the data-driven paradigm, making it increasingly sophisticated and useful.
Big data refers to the high volume, velocity, and variety of information assets that demand new, innovative forms of processing for enhanced decision making, business insights, and process optimization [18]. As a relatively new concept, the basic notion of big data includes the techniques and technologies required to manage very large quantities of data. In addition to the technologies, skilled professionals are needed with analysis and design skills to appropriately manage this resource [2,16].
Mayer-Schonberger and Cukier [21] argue that big data will change the way people live, work, and think, although it requires that many obstacles be overcome. The data must be obtained, processed, and effectively used, raising related issues on how big data will be represented and modelled. Understanding the challenges associated with big data representation and modeling, though, first requires an understanding of the characteristics of big data.
2.1. The Vs of big data
Big data, as traditionally characterized by the “3Vs” of volume, variety, and velocity, have emerged from advances in sensing, measuring, and social computing technologies (Gartner.com). In addition to these Vs, veracity (accuracy) and, especially, value, are important. Each of the Vs has its own unique challenges. The volume is too big, the variety requires both structured and unstructured analysis, and the velocity is so fast that we might not even have time to identify reasonable questions to ask [8]. The veracity leads to uncertainty, and the volume competes with velocity [27]. It is the value, however, that is the most time-consuming to extract, and difficult to ascertain. Fig. 2 summarizes the “5 V” challenges dominant in big data practice and research efforts.
Volume: The large volume of data has resulted in data availability coming from diverse, often location-dependent, data streams containing various kinds of data that are being generated at a very high velocity from huge banks of physical, digital, and human sensors [10]. The data sources include wearable technologies, cloud-based service (e.g., Amazon web services), enterprise data warehouses (EDW), and NoSQL databases [40]. The scale is now terabytes, petabytes, and exabytes. The volume challenge is being addressed, technologically, by using commodity hardware and the Hadoop Distributed File System (HDFS).
Velocity: The velocity is the speed to create, capture, extract, process, and store data. A semi-technology solution is needed to deal with the velocity challenge, with the software solution portion having real-time processing, streaming and in-memory computing.
Variety: Different data types and sources provide relations (from relational databases), documents, Web data, XML files, sensor data, multimedia files, and so forth. The variety challenge is primarily addressed by software solutions because the integration of heterogeneous data requires an extensive software effort to handle the variety.
چکیده
1. مقدمه
2. دادههای بزرگ
2.1. Vهای داده های بزرگ
2.2. زیرساخت مدیریت دادههای بزرگ
2.3. الگوهای مبتنی بر دادهها
2.4. رشد و چالشها
3. فناوری پایگاه داده جدید برای دادههای بزرگ
3.1. چه چیزی در سیستمهای مدیریت پایگاه داده ارتباطی سنتی اشتباه است؟
3.2. Hadoop
3.2.1. Apache spark
3.3. پایگاههای داده NOSQL و NewSQL
3.3.1. محاسبات در حافظه
3.3.2. محاسبه ابر ترکیبی
3.3.3. روند ETL در مقابل ELT
3.4. خلاصهای از فناوریهای داده بزرگ
4. پایگاه داده NoSQL
4.1. مدلسازی پایگاه داده NoSQL
4.2. انواع پایگاه داده NoSQL
4.2.1. ذخیره کلید- ارزش
4.2.2. ذخیره ستون
4.2.3. ذخیره سند
4.2.4. پایگاه داده گراف
4.3. مسائل و موارد استفاده از پایگاههای داده NoSQL
5. مدلسازی مفهومی و مدیریت دادههای بزرگ
5.1. چالشها
5.2. چرخه حیات تحلیل دادهها
6. بررسی
7. نتیجهگیری
منابع
ABSTRACT
1. Introduction
2. Big Data
2.1. The Vs of big data
2.2. Infrastructure to manage big data
2.3. Data-driven paradigm
2.4. Growth and Challenges
3. New database technologies for big data
3.1. What’s wrong with traditional RDBMSs?
3.2. Hadoop
3.2.1. Apache spark
3.3. NOSQL and NewSQL databases
3.3.1. In-memory computing
3.3.2. Hybrid cloud computing
3.3.3. Trend: ETL versus ELT
3.4. Summary of big data technologies
4. NoSQL databases
4.1. NoSQL database modeling
4.2. Types of NoSQL databases
4.2.1. Key-value Store
4.2.2. Column store
4.2.3. Document store
4.2.4. Graph database
4.3. Problems and use cases of NoSQL databases
5. Conceptual modeling and big data management
5.1. Challenges
5.2. Data analytics lifecycle
6. Discussion
7. Conclusion
References