
دانلود رایگان مقاله مدل سازی پیش بینی مدیریت درآمدها
چکیده
این مطالعه به کشف مدیریت درآمدهای واقعی و اینکه آیا ویژگی مدل پیش فرض بر اساس متدلوژی Z-Score برای شرکت های چینی را بهبود بخشیده می پردازد. مدل ارائه شده توسط Altman (1968) Z- Score و احتمال بقا برای شرکت هایی که درگیر دستکاری افزایش حقوق پرتکاپو (مقدار کم یا هیچ) بوده را زیاد در نظر گرفته (ناچیز در نظر گرفتن) است. در مقابل، دربر گیری متغیر اشاره برای مدیریت درآمدهای واقعی، قدرت توضیحی فاکتورهای Z- Score برای بقا یا پیش فرض شرکت را افزایش می دهد. با توجه به توانایی پیش بینی پیش فرض خارج از نمونه، یافته ها نشان می دهند که مدل امتیاز بندی اعتباری مبتنی بر حسابداری که برای مدیریت درآمدهای واقعی تنظیم شده میزان دقیق پیش بینی را افزایش و میزان عدم وام کاذب را نسبت به مدل امتیاز بندی تنظیم شده برای شرکت های مناسب از نظر مالی کاهش می دهد.
1. مقدمه
این مطالعه به بررسی بهبود ویژگی مدل پیش بینی پیش فرض بر اساس متدلوژی امتیاز دهی توسط Altman (1968) برای شرکت های چینی می پردازد. با توجه به جمع آوری اقدامات حسابداری گزارش شده از جمله سرمایه در گردش، درآمدهای انباشته، سودها و مخارج مالیات، نسبت بدهی به دارایی خالص و گردش دارایی ها، مدل Altman از Z- Score گرفته شده که از وزن های ثابت و نمونه خاص عوامل تعیین کننده استفاده می کند که بدون در نظر گرفتن کیفیت درآمدها مربوط به ضرایب پیش بینی شده می باشد. هر چه Z- Score بزرگتر باشد، احتمال ورشکستگی کمتر می باشد. شرکت ها قبل از وضعیت نامناسب مالی، دارای محرک های قوی جهت کاهش مخارج یا ضامن مدیریت سودها می باشند. در نتیجه عوامل تعیین کننده مبتنی بر حسابداری که از صورت حساب های مالی حاصل شده ممکن است برای ریسک های اعتباری فاکتورهای سودار باشند.
مدیریت درآمدهای واقعی را قبل از وضعیت نا مناسب مالی در نظر گرفته تا به اهمیت تنظیم مدل های پیش بینی پیش فرض مبتنی بر حسابداری پرداخته شود. شرکت ها ممکن است از تخفیفات، طرح های بارگیری اولیه، استفاده کرده یا تارخ های پرداخت را تجدید کرده تا درآمدهای بودجه ای گزارش شده را افزایش دهد. در نتیجه میزان سود فروش نسبت به سرمایه کل که به عنوان متغیر در مدل امتیاز دهی عمل میکند احتمالا افزایش یافته اما عملکرد جریانات نقدی ممکن است با سرعت کمی نسبت به منافع افزایش یابد. افزایش فروش برای این شرکت ها ممکن است به سود آوری آینده اشاره نکند اما Z- Score را افزایش داده و پیش فرض پیش بینی شده در مدل Z- Score را کاهش می دهد. چنین مفهومی مطابق با یافته های گراهام و همکاران (2005) می باشد، آنها با بیش از 400 مدیر اجرایی مصاحبه کردند که حدود %78 برآوردن یا افزایش معیارهای درآمد در عملکرد طولانی را ترجیح می دهند.
بمنظور کشف میزان تحریف مدل های مبتنی بر حساب که به دلیل تغییر درآمدها ایجاد شده، این مطالعه میزان فعالیتهای مدیریت درآمد واقعی با هم ترکیب کرده تا اجازه دهد وزن عوامل با انحراف فروش، تولید و تحلیل فعالیت ها تغییر کنند. سپس به بررسی مدل های تنظیم شده که عملکرد پیش بینی پیش فرض خارج از نمونه را بهبود می بخشد می پردازیم. در می یابیم که در مقایسه با پیش بینی ایجاد شده بوسیله مدل Z- Score، احتمال بقا و Z- Score برگرفته از مدل تنظیم نشده برای شرکت هایی که مخارج را کاهش داده یا تشخیص فروش ها را سرعت بخشیده به مقدار زیاد بر آورد شده است. در مقابل، احتمال بقا و Z- Score گرفته شده از مدل تنظیم نشده برای شرکت های دیگر ناچیز پنداشته شده است. در ارتباط با توانایی پیش بینی پیش فرض خارج از نمونه، یافته ها مدیریت درآمدهای واقعی در مورد تخمین ضریب مدل Z- Score توضیح می دهد، و تسویه های مربوطه قدرت پیش بینی متدلوژی Z- Score را افزایش می دهد.
مطالعات ما به ادبیات به دو طریق کمک می کند. تفاوت در کیفیت درآمدها در میان شرکت ها سودمندی مدل مبتنی بر حسابداری Z- Score را تعیین می کند که بمنظور ارزیابی ریسک اعتباری بطور گسترده استفاده می گردد. دوم اینکه متغیرهای مدیریت درآمد واقعی را گنجانده و مشخصه مدل پیش بینی پیش فرض را بر اساس متدلوژی Z- Score گسترش می دهیم. بدون تنظیمات و تسویه ، مدل Z- Score پیش فرض را بیشتر از حد برای شرکت های درگیر در مدیریت درآمدهای واقعی فرض کرده اما پیش فرض برای شرکت های دیگر را ناچیز می پندارد. در نظر نگرفتن تاثیر مدیریت درآمدهای واقعی بر پیش بینی پیش فرض، احتمال بقا %53/4 برای شرکت هایی با مدیریت درآمدهای واقعی و %26/3 برای شرکت هایی با مدیریت درآمدهای واقعی کمتر پیش بینی کرده است و نیاز به تعدیل مدل های پیش بینی پیش فرض مبتنی بر حسابداری می باشد. تفاوت های مربوط به شرکت ها با مدیریت درآمد قابل توجه منفی هستند. یافته ها را می توان در قیمت گذاری وام بکار برد.
مابقی این مطالعه بصورت زیر سازماندهی شده است: بخش دو ادبیات مرتبط را مرور می کند. بخش 3 فرضیه ها را توسعه می دهد. بخش 4 طراحی طرح پژوهش و تسویه پیشنهادی را برای مدل های پیش بینی پیش فرض را توضیح می دهد. بخش 5 یافته ها و نتایج پیش بینی خارج از نمونه را ارائه می دهد. و قسمت 6 نتیجه گیری می کند.
2. بررسی ادبیات
مطالعه ما مربوط به تحقیق (i) بوده که جهت مدل پیش بینی پیش فرض و پیش بینی پذیری برای مدل ها را خارج از نمونه توسعه داده و (ii) تحقیق در مورد سود شرکت ها و یا مدیریت مخارج می باشد. در مباحث زیر مطالعات متدلوژی های پیش بینی مدیریت درآمدهای فعالیت واقعی را بررسی می کنیم.
2.1 مدل پیش بینی پیش فرض
در 40 سال گذشته پژوهشگران ریسک اعتباری متدلوژی های موثری را بمنظور پیش بینی عدم پرداخت بدهی وام گیرندگان یا شکست اقتصادی کشف کردند. اقدامات تاثیر گذار در این زمینه توسط Beaver (1967)و Altman (1968) صورت گرفته است که مدل های مبتنی بر حسابداری از نسبت های مالی جهت پیش بینی شکست های تجاری استفاده می گردد. با بکارگیری 14 نسبت مالی برای طبقه بندی ناکامی یک شرکت در برابر یک نمونه همسان، Beaver از آزمون طبقه بندی دو مقوله ای جهت شناسایی میزان خطا که یک طلبکار بالقوه تجربه کرده ساتفاده می کند. در مقابل، Altman یک روش تحلیل چند تایی جدا کننده (MDA) جهت حل مشکل بی ثباتی مربوط به مدل یک متغیری Beaver بکار میگیرد. Altman 22 نسبت مالی سودمند مالی را جهت شناسایی پیش فرض شرکت های تولیدی بکار برد که در نصف آنها درخواست ورشکستگی را اصلاح می کنند. او سپس 5 نسبت از 22 نسبت را که بهترین قدرت را جهت پیش بینی ورشکستگی شرکت فراهم کرده انتخاب می کند. این 5 متغیر مربوط به نقدینگی، سود آوری، نسبت بدهی به دارایی خالص، پرداخت بدهی و نسبت های فعالیت می باشند. مطالعات ریسک اعتباری از MAD Altman (Altman et al., 1977, 1995; Blum, 1974; Deakin, 1972; Edmister, 1972; Eisenbeis, 1977; Gombola et al., 1987; Lussier, 1995; Micha, 1984; Piesse and Wood, 1992; Taffler and Tisshaw, 1977). استفاده می کند. بر اساس اکثر مطالعات مذکور فرضیات اولیه MDA نقض شده است.
بمنظور رسیدگی به مشکلات مربوط به MDA، Ohlson (1980) یک مدل لاجیت شرطی پیشنهاد می دهد. مزیت های کاربردی مدل لاجیت شرطی اینست که هیچ فرضیه ای لازم نمی باشد. بنابراین Ohlson نمونه شرکت های ورشکسته و غیر ورشکسته را با استفاده از 7 نسبت مالی و دو متغیر باینری بررسی می کند. دقت نتیجه پیش بینی از دقت MDA کمتر می باشد Altman, 1968; Altman et al., 1977)). بدنبال اقدام پیشگام Ohlson، محققان از مدل های لاجیت جهت پیش بینی پیش فرض استفاده کردند (Altman and Sabato, 2007; Aziz et al., 1988; Becchetti and Sierra, 2002; Gentry et al., 1985; Keasey andWatson, 1987;Mossman et al., 1998; Ooghe et al., 1995; Platt and Platt, 1990; Zavgren, 1983) متغیر وابسته باینری اشاره می کند که آیا پیش فرض شرکت با رگرسیون لجستیک مطابقت دارد. نیتجه بین صفر و یک بوسیله رگرسیون لجستیک بدست آمده و سودمند می باشد زیرا بطور مستقیم احتمال پیش فرض هدف تشخیص داده را نشان می دهد. ضرایب برآورد شده در مورد تاثیر هر متغیر مستقل بر پیش بینی پیش فرض اطلاعات معنی دار را ارائه می دهد.
Abstract
This study explores whether taking into account real earnings management improves specification of the default prediction model based on the Z-score methodology for Chinese listed companies. We demonstrate that the model proposed by Altman (1968) overestimates (underestimates) the Z-score and thus the survival probability for firms engaging in aggressive (minor or no) income-increasing manipulation. By contrast, our inclusion of the indicator variable for real earnings management considerably enhances the explanatory power of Z-score factors for firm survival/default. With respect to the ability to predict out-of-sample default, our findings suggest that the accounting-based credit scoring model adjusted for real earnings management unanimously yields a greater prediction accuracy rate and a lower false loan rejection rate than the unadjusted scoring model for financially non-distressed firms.
1. Introduction
This study examines whether and how taking account of earnings management improves specification of the default prediction model based on the scoring methodology proposed by Altman (1968) for Chinese listed companies. Collecting reported accounting measures including working capital, retained earnings, earnings before interests and tax expenses, leverage ratios, and assets turnover, the Altman model derives the Z-score using either fixed or sample-specific weights of the determinants that are assigned by the estimated coefficients, regardless of the quality of earnings. Specifically, the greater the Z-score is, the lower the probability of bankruptcy becomes. However, prior to financial distress, firms may have strong incentives to reduce expenditures or even strategically engage in earnings management. Consequently, accounting-based determinants retrieved from financial statements may be biased factors for credit risk.
Let us consider the following example of real earnings management prior to financial distress to address the importance of adjusting accounting-based default prediction models. Firms may use discounts, pre-loading schemes, or extended payment dates exclusively to increase reported revenues. As a result, the ratio of sales revenue to total assets, which serves as a variable in the scoring model, may be boosted, but the operating cash flows may increase at a slower rate than for the revenues. The sales increases for these firms may thus fail to indicate strong future profitability but raise the Z-score and lower the predicted default likelihood in the Z-score model. Such a notion is consistent with the findings of Graham et al. (2005), who interviewed more than 400 executives, among whom approximately 78% admit that they prefer meeting or exceeding earnings benchmarks at the expense of long-run performance.
To explore the extent of the distortion of accounting-based models caused by earnings manipulation, this study incorporates measures of real earnings management activities to allow weights of the determinants to vary with the deviation of the sales, production, and spending activities from the norm. We then examine whether our adjusted model enhances the performance of the out-of-sample default prediction. Consistently, we find that, compared with predictions generated by our adjusted Zscore model, both the Z-score and the survival probability derived from the unadjusted Z-score model are overestimated for firms that excessively reduce expenses or accelerate sales recognition. By contrast, the Z-score and the survival probability derived from the unadjusted model are both underestimated for other firms. With respect to the out-of-sample default predictability, our findings suggest that real earnings management measures help explain the Z-score model coefficient estimates, and thus the corresponding adjustment considerably enhances the predictive power of the Z-score methodology.
Our study contributes to the literature in two ways. First, it shows that the differences in earnings quality among firms can help determine the usefulness of the accounting-based Z-score model, which is widely adopted to assess credit risk. Second, we include real earnings management variables and notably enhance the specification of the default prediction model based on the Z-score methodology. Specifically, without adjustments, the Z-score model appears to overestimate the default likelihood for firms engaging in aggressive real earnings management, but underestimates the default likelihood for other firms. With the failure to take into account the effect of real earnings management on the default prediction, the survival probability is overestimated by 4.53% for firms with aggressive real earnings management and is underestimated by 3.26% for firms with lower real earnings management, consistent with the contention that there is a need to adjust accounting-based default prediction models. The differences are unanimously negative for the group of firms with more pronounced earnings management measures. Our findings may be applied to the practice of loan pricing.
The remainder of this study is organized as follows: Section 2 reviews the related literature. Section 3 develops our hypotheses. Section 4 describes the research design and our proposed adjustment for default prediction models. Section 5 presents the findings and the out-of-sample prediction results. Section 6 concludes.
2. Literature review
Our study relates to (i) research that develops default prediction models and the out-of-sample predictability for the models and (ii) research on firms' revenue and/or expense management. In the following discussion, we review studies of default prediction methodologies and real activity earnings management.
2.1. Default prediction model
Over the last 40 years, credit risk scholars have explored effective methodologies for predicting borrowers' default or business failure. Influential steps in this field include those made by Beaver (1967) and Altman (1968), whose accounting-based models adopt financial ratios to predict business failures. By employing 14 financial ratios to classify an individual firm's failure against a matched sample, Beaver adopts a dichotomous classification test to identify the error rates that a potential creditor would experience. Altman, in contrast, develops a multiple discriminant analysis (MDA) method to solve the inconsistency problem related to Beaver's univariate model. Altman adopts 22 potentially useful financial ratios to detect default for his sample manufacturing firms, among which one-half file a bankruptcy petition. He then selects 5 ratios among the 22 that provide the best overall power to predict corporate bankruptcy.1 These five variables concern liquidity, profitability, leverage, solvency, and activity ratios. Credit risk studies commonly apply Altman's MDA (Altman et al., 1977, 1995; Blum, 1974; Deakin, 1972; Edmister, 1972; Eisenbeis, 1977; Gombola et al., 1987; Lussier, 1995; Micha, 1984; Piesse and Wood, 1992; Taffler and Tisshaw, 1977). However, most of the aforementioned studies observe that the basic assumptions of MDA are often violated.
To address the problems associated with MDA, Ohlson (1980) proposes a conditional logit model. The practical advantages of the conditional logit model are that no assumptions are required. Therefore, Ohlson examines samples consisting of both bankrupt and non-bankrupt firms using seven financial ratios and two binary variables. The resulting prediction accuracy is lower than that of MDA (Altman, 1968; Altman et al., 1977). However, following Ohlson's (1980) pioneering work, researchers largely adopt logit models to predict default (Altman and Sabato, 2007; Aziz et al., 1988; Becchetti and Sierra, 2002; Gentry et al., 1985; Keasey and Watson, 1987; Mossman et al., 1998; Ooghe et al., 1995; Platt and Platt, 1990; Zavgren, 1983). The binary dependent variable indicates whether a firm's default inherently fits well in the logistic regression. A result between zero and one yielded by the logistic regression is practically useful because it directly suggests a probability of default of a diagnosed target. The estimated coefficients also provide meaningful information regarding the influence of each independent variable on the default prediction.
چکیده
1.مقدمه
2. بررسی ادبیات
2.1 مدل پیش بینی پیش فرض
2.2 اقدامات مدیریت درآمدهای واقعی
3. گسترش نظریه
4. طراحی های تحقیق بمنظور برآورد تاثیر مدیریت درآمدها بر کارایی مدل ارزیابی ریسک
4.1 مدیریت درآمد واقعی
2.4 مدل تجربی و اندازه های متغیر
4.1 منابع داده ها معیارهای نمونه
4.2 4.5 آمارهای توصیفی
5. نتایج تجربی
1.5. تاثیر مدیریت درآمدها بر مدل Z-score
2.5 پیش بینی های خارج از نمونه برای بحران های مالی
3.5. احتمال بقا از مدل مبتنی بر حسابداری تنظیم شده برای دهک های مدیریت درآمدهای واقعی
6. تحلیل های اضافه
1.6 تست افزایش اختیاری
2.6 استفاده از مدل Ohlson جهت پیش بینی بحران مالی
3.6. تاثیر مالی بحران مالی جهانی
7. نتیجه گیری
منابع
Abstract
1. Introduction
2. Literature review
2.1. Default prediction model
2.2. Real earnings management measures
3. Hypothesis development
4. Research designs for estimating the effect of earnings management on the effectiveness of the risk assessment model
4.1. Real earnings management
4.2. Empirical model and variable measurements
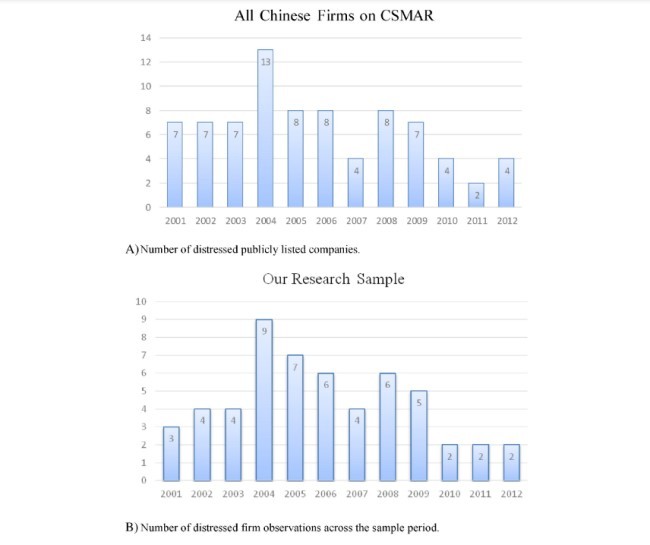
4.1. Data source and sample criteria
4.2. 4.5. Descriptive statistics
5. Empirical results
5.1. Effect of earnings management on the Z-score model
5.2. Out-of-sample predictions for financial distress
5.3. Survival probability from accounting-based model adjusted for real earnings management deciles
6. Additional analyses
6.1. Test for discretionary accruals
6.2. Adopting Ohlson's model to predict financial distress
6.3. Impact of global financial crisis
7. Conclusion
References