
دانلود رایگان مقاله پیش بینی قابلیت اطمینان نرم افزار با استفاده از روش محاسبات نرم
چکیده
در این مقاله، مدلهای گروهی برای دقت پیشبینی قابلیت اطمینان نرمافزار توسعه یافته است. روشهای آماری (رگرسیون خطی چندگانه و رگرسیون خطی چند متغیره) و تکنیکهای هوشمند (شبکه عصبی آموزش دیده پس انتشار، سیستم استنتاج عصبی-فازی پویا و TreeNet) گروهها را ارائه میدهند. سه گروه خطی و یک گروه غیرخطی طراحی و تست شده است. براساس آزمایش روی قابلیت اطمینان دادههای بدست آمده از نرمافزار، مشاهده شده است که مجموعه گروههای غیرخطی عملکرد بهتری نسبت به گروههای دیگر و همچنین روشهای آماری و هوشمند دارند.
1. معرفی
قابلیت اطمینان نرمافزار بهعنوان احتمال خطای عملیات نرمافزار برای یک دوره مشخص از زمان در یک محیط مشخص شده است (تعریف ANSI). مدلسازی قابلیت اطمینان نرمافزار اهمیت بسیاری در سالهای اخیر بهدست آورده است. بحران نرمافزار در بسیاری از برنامههای کاربردی حاضر رو به افزایش است. کاربرد شبکههای شبکه هوشمند و هیبرید عصبی بهجای روشهای آماری سنتی بهبود قابل توجهی در پیشبینی قابلیت اطمینان نرمافزار در سالهای اخیر نشان داده است. در میان روشهای هوشمند و آماری شناسایی بهترین آسان است زیرا عملکرد آنها با تغییر در داده متفاوت است.
در این مقاله، یک رویکرد مبتنی بر گروه برای پیشبینی قابلیت اطمینان نرمافزار تشریح شده است. بهطورخاص، شبکه عصبی غیرخطی پس انتشار با استفاده از گروه آموزش دیده (BPNN) ارائه شده است. روش پیشنهادی تمام قابلیتهای تکنیک پیشبینی را به سمت داده و اختصاص مناسب وزن به هر از تکنیکهای مبتنی بر عملکرد آنها برده است.
ساختار مقاله بهصورت ذیل سازمان یافته است. در بخش 2، بررسی مختصری از کاهای انجام گرفته در پیشبینی قابلیت اطمینان نرمافزار ارائه شده است. در بخش 3، روشهایی مختلف هوشمند که در این مقاله بهکار برده شده است بهطور خلاصه شرح دادیم. در بخش 4، چهار گروه توسعه داده شده ارائه شده است. در بخش 5 روش تجربی ارائه شده است. بحث در مورد نتایج را در بخش 6 بیان کردهایم. در بخش 7، کاربرد مدلسازی دقیق عملیاتی خطر در بانکها ارائه شده است. در نهایت، بخش 8 نتیجهگیری مقاله را بیان میکند.
2. کارهای گذشته
در سالهای اخیر بسیاری از مطالعات تحقیقاتی انجام شده در این زمینه در مورد مدلسازی قابلیت اطمینان نرمافزار و پیشبینی آن است. که شامل استفاده از شبکههای عصبی، مدل منطق فازی؛ الگوریتم ژنتیک (GA) براساس شبکههای عصبی، شبکههای عصبی راجعه، شبکههای عصبی بیزی و ماشین بردار پشتیبان (SVM) بر اساس تکنیکهایی، بهنام Cai و همکارانش (1991) برای حمایت از توسعهی مدل قابلیت اطمینان نرمافزار فازی بهجای مدل قابلیت اطمینان نرمافزار احتمالاتی (PSRMs) بود.
استدلال آنها در اثبات براساس قابلیت اطمینان نرمافزار فازی در طبیعت بود. همچنین چگونگی توسعهی یک مدل فازی برای توصیف قابلیت اطمینان نرمافزار ارائه شد. Karunanidhi و همکارانش (1992) یک مطالعهی دقیق برای توضیح استفاده از مدلهای پیشبینی در رشد قابلیت اطمینان نرمافزار انجام دادند. نتایج تجربی نشان داده است که مدلهای پیوندگرا انطباق خوبی در سراسر مجموعه دادههای مختلف دارند و نمایش بهتری در پیشبینی دقت نرمافزار نسبت به مدلهای قابلیت اطمینان تحلیلی شناخته شده دارند. Sitte (1999) یک مطالعهی مقایسهای در شبکههای عصبی و مدل پارامتری-کالیبراسیون مجدد در پیشبینی قابلیت اطمینان نرمافزار انجام داد و مشاهده کرد که شبکههای عصبی برای استفاده بسیار سادهتر هستند و همچنین پیشبینی بهتر دارند. همچنین، از طریق نتایج تجربی نشان داده که مدلهای شبکه عصبی پیشبینی روند بهتری دارند. Ho و همکارانش (2003) یک مطالعهی جامع از مدلهای پیوندگرا و کاربرد آنها در پیشبینی قابلیت اطمینان نرمافزار انجام داد و دریافت که این مدلها انعطافپذیرتر از مدلهای سنتی هستند. یک مطالعهی مقایسهای بین شبکههای عصبی راجعه پیشنهادی آنها، با شبکههای عصبی محبوبتر و مدل جردن و برخی از مدلهای نرمافزار اعتماد سنتی انجام گرفت. نتایج عددی نشان میدهد که معماری شبکهی پیشنهادی نسبت به مدلهای دیگر پیشبینی در شرایط بهتری قرار دارد. علیرغم پیشرفتهای اخیر در مدلهای رشدیافتهی قابلیت اطمینان نرمافزار مشاهده شد که مدلهای متفاوت دارای قابلیتهای پیشبینی متفاوتی هستند و همچنین هیچ الگوی واحدی تحت هر شرایطی مناسب نیست.
TianوNoore (2005a) یک مدل تطبیقی پیشبینی قابلیت اطمینان نرمافزار با استفاده از رویکرد تکاملی پیوندگرا براساس معماری ورودیهای چند تاخیری و تک خروجی ارائه دادهاند. روش پیشنهادی، توسط نتایج نشان داده شده و تا بهحال عملکرد بهتری با توجه به گام بعدی پیشبینی در مقایسه با مدلهای موجود شبکه عصبی برای پیشبینی زمان شکست داشته است. Tian و Noore (2005b) یک روش مدلسازی شبکه عصبی تکاملی برای پیشبینی زمان شکست نرمافزار ارائه کرده است. نتایج آنها نشان میدهد که نسبت به مدلهای شبکه عصبی موجود بهتر است. همچنین نشان داده است که معماری شبکههای عصبی تاثیر بهسزایی بر عملکرد شبکه دارد. باتوجه به Bai و همکارانش (2005) شبکههای بیزی توانایی قوی برای انطباق در مشکلات مربوط به عوامل پیچیده نشان میدهد. آنها یک مدل پیشبینی نرمافزار براساس شبکههای مارکوف بیزی و یک روش برای حل مدل شبکه پیشنهاد دادهاند. Reformat (2005) یک رویکرد منجر به استخراج دانش چند تکنیکی پیشنهاد داد و یک سیستم پیشبینی متا مدل جامع در حوزه نگهداری اصلاحی از نرمافزار ارائه داد. سیستم براساس نظریه شواهد و تعدادی از مدلهای مبتنی بر فاز بود. علاوهبراین آنها یک مطالعه موردی دقیق برای تخمین تعداد نقص در یک سیستم تصویربرداری پزشکی با استفاده از روش ارائه شده انجام دادند. Pai و Hong (2006) ماشین بردار پشتیبان (SVM ها) را برای پیشبینی قابلیت اطمینان نرمافزار در الگوریتم شبیهسازی دوباره (SA) برای انتخاب پارامترهای مدل SVM مورد استفاده قرار دادند. نتایج تجربی نشان میدهد که مدل ارائه شده پیشبینی بهتری نسبت به روشهای مقایسه شده دارد. Su و Huang (2006) نشان داد که چگونه شبکههای عصبی را برای پیشبینی قابلیت اطمینان نرمافزار به کار ببریم. بیشتر آنها از روش شبکههای عصبی برای ساخت یک مدل وزندار ترکیبی پویا (DWCM) استفاده کردند و نتایج تجربی نشان میدهد که مدل پیشنهادی بهطور قابل توجهی پیشبینی بهتری دارد. همچنین بهتازگی، شبکههای عصبی برای پیشبینی خطا در نرمافزار شیگرا (Kanmani و همکارانش، 2007) بهکار برده شده است. این مطالعه نشان میدهد که مدلهای شبکه عصبی خیلی بهتر از روشهای آماری هستند.
استفاده از تکنیکهای هوشمند بهجای تکنیکهای آماری در سالهای اخیر با فرازونشیب بسیار همراه بوده است. استفاده از تکنیکهای محاسبات نرم در مهندسی قابلیت اطمینان نرمافزار بهتازگی وارد عرصه شده است (Madsen و همکارانش، 2006). باوجود پیشرفتهای اخیر در مدلهای رشد قابلیت اطمینان نرمافزار، مشاهده میشود که مدلهای متفاوت دارای قابلیتهای متفاوت پیشبینی هستند و همچنین هیچ الگوی واحدی تحت هر شرایطی مناسب نیست. گروه از خروجی بهدست آمده از ترکیبات منحصربهفرد بهعنوان ورودی استفاده میکند و دادهها باتوجه به طراحی داور دروغ گفتن در قلب گروه پردازش میشوند.
Abstract
In this paper, ensemble models are developed to accurately forecast software reliability. Various statistical (multiple linear regression and multivariate adaptive regression splines) and intelligent techniques (backpropagation trained neural network, dynamic evolving neuro–fuzzy inference system and TreeNet) constitute the ensembles presented. Three linear ensembles and one non-linear ensemble are designed and tested. Based on the experiments performed on the software reliability data obtained from literature, it is observed that the non-linear ensemble outperformed all the other ensembles and also the constituent statistical and intelligent techniques. 2007 Elsevier Inc. All rights reserved.
1. Introduction
Software reliability is defined as the probability of failure-free software operation for a specified period of time in a specified environment (ANSI definition). Software reliability modeling has gained a lot of importance in the recent years. Criticality of software in many of the present day applications has led to a tremendous increase in the amount of work being carried out in this area. The use of intelligent neural network and hybrid techniques in place of the traditional statistical techniques have shown a remarkable improvement in the prediction of software reliability in the recent years. Among the intelligent and the statistical techniques it is not easy to identify the best one since their performance varies with the change in data.
In this paper, an ensemble-based approach is followed in predicting software reliability. Specifically, a non-linear ensemble trained using backpropagation neural network (BPNN) is proposed. The proposed approach takes the advantage of all the techniques’ prediction capabilities towards the data and appropriately assigns weights to each of the techniques based upon their performance.
The rest of the paper is organized in the following manner. In Section 2, a brief review of the works carried out in the area of software reliability prediction in research is presented. In Section 3, the various stand-alone intelligent methods that are applied in this paper are described briefly. In Section 4, the four ensembles that are developed are presented. Section 5 presents the experimental methodology; discussion of the results is presented in Section 6. In Section 7, the application of this in accurately modeling operational risk in banks is presented. Finally, Section 8 concludes the paper.
2. Literature survey
In the last few years many research studies has been carried out in this area of software reliability modeling and forecasting. They included the application of neural networks, fuzzy logic models; Genetic algorithms (GA) based neural networks, recurrent neural networks, Bayesian neural networks, and support vector machine (SVM) based techniques, to name a few. Cai et al. (1991) advocated the development of fuzzy software reliability models in place of probabilistic software reliability models (PSRMs).
Their argument was based on the proof that software reliability is fuzzy in nature. A demonstration of how to develop a fuzzy model to characterize software reliability was also presented. Karunanithi et al. (1992) carried out a detailed study to explain the use of connectionist models in software reliability growth prediction. It was shown through empirical results that the connectionist models adapt well across different datasets and exhibit better predictive accuracy than the well-known analytical software reliability growth models. Sitte (1999) made a comparative study of neural networks and parametric-recalibration models in software reliability prediction and found neural networks to be much simpler to use and also to be better predictors. Also, through empirical results it was shown that the neural network models are better trend predictors. Ho et al. (2003) performed a comprehensive study of connectionist models and their applicability to software reliability prediction and found them to be better and more flexible than the traditional models. A comparaitive study was performed between their proposed modified Elman recurrent neural network, with the more popular feedforward neural network, the Jordan recurrent model, and some traditional software reliability growth models. Numerical results show that the proposed network architecture performed better than the other models in terms of predictions. Despite of the recent advancements in the software reliability growth models, it was observed that different models have different predictive capabilities and also no single model is suitable under all circumstances.
Tian and Noore (2005a) proposed an on-line adaptive software reliability prediction model using evolutionary connectionist approach based on multiple-delayed-input single-output architecture. The proposed approach, as shown by their results, had a better performance with respect to next-step predictability compared to existing neural network model for failure time prediction. Tian and Noore (2005b) proposed an evolutionary neural network modeling approach for software cumulative failure time prediction. Their results were found to be better than the existing neural network models. It was also shown that the neural network architecture has a great impact on the performance of the network. According to Bai et al. (2005) Bayesian networks show a strong ability to adapt in problems involving complex variant factors. They developed a software prediction model based on Markov Bayesian networks, and a method to solve the network model was proposed. Reformat (2005) proposed an approach leading to a multitechnique knowledge extraction and development of a comprehensive meta-model prediction system in the area of corrective maintenance of software. The system was based on evidence theory and a number of fuzzy-based models. In addition they carried out a detailed case study for estimating the number of defects in a medical imaging system using the proposed approach. Pai and Hong (2006) have applied support vector machines (SVMs) for forecasting software reliability where simulated annealing (SA) algorithm was used to select the parameters of the SVM model. The experimental results show that the proposed model gave better predictions than the other compared methods. Su and Huang (2006) showed how to apply neural networks to predict software reliability. Further they made use of the neural network approach to build a dynamic weighted combinational model (DWCM) and experimental results show that the proposed model gave significantly better predictions. Also recently, neural networks were applied for predicting faults in object-oriented software (Kanmani et al., 2007). The study showed neural network models to be performing much better than the statistical methods.
Application of intelligent techniques in place of the statistical techniques has increased by leaps and bounds in the recent years. Application of Soft Computing techniques in software reliability engineering has come up recently (Madsen et al., 2006). Despite the recent advancements in the software reliability growth models, it was observed that different models have different predictive capabilities and also no single model is suitable under all circumstances. An ensemble uses the output obtained from the individual constituents as inputs to it and the data is processed according to the design of the arbitrator lying at the heart of the ensemble.
چکیده
1. معرفی
2. کارهای گذشته
3. بررسی اجمالی تکنیکهای بهکار گرفته
3.1. شبکههای عصبی مبتنیبر آستانه پذیرش
3.2. شبکه PI-Sigma (PSN)
3.3. رگرسیون خطی چندمتغیره (MARS)
3.4. رگرسیون شبکههای عصبی تعمیم یافته (GRNN)
3.5. TreeNet
3.6. سیستم استنتاج عصبی-فازی پویا (DENFIS)
4. مدلهای پیشبینی گروه
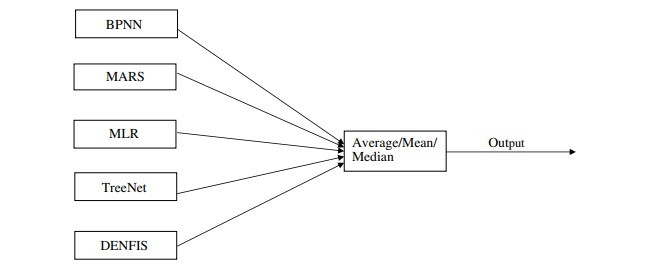
4.1. گروه خطی براساس میانگین
4.2. گروه خطی براساس میانگین وزنی
4.3. گروه خطی براساس متوسط وزن
4.4. شبکههای عصبی مبتنی برگروه غیرخطی
5. طراحی تجربی
6. نتایج و بحث
7. نرمافزار مدلسازی ریسک عملیاتی در بانک ها
8. نتیجهگیری
منابع
Abstract
1. Introduction
2. Literature survey
3. Overview of the techniques applied
3.1. Threshold-acceptance-based neural network
3.2. Pi–Sigma network (PSN)
3.3. Multivariate adaptive regression splines (MARS)
3.4. Generalized regression neural network (GRNN)
3.5. TreeNet
3.6. Dynamic evolving neuro–fuzzy inference system (DENFIS)
4. Ensemble forecasting models
4.1. Linear ensemble based on average
4.2. Linear ensemble based on weighted mean
4.3. Linear ensemble based on weighted median
4.4. Neural network based non-linear ensemble
5. Experimental design
6. Results and discussion
7. Application to operational risk modeling in banks
8. Conclusions
References